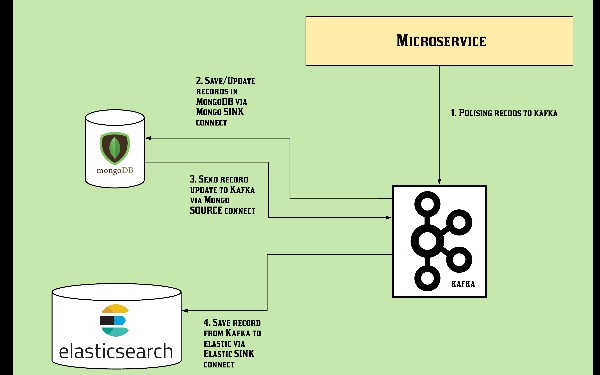
In this article, we will see how to implement a data pipeline from an application to Mongo DB database and from there into an Elastic Search keeping the same document ID using Kafka connect in a Microservice Architecture. In recent days and years, all the microservices architectures are asynchronous in nature and are very loosely coupled. At the same time, the prime approach to have minimum code (minimum maintenance and cost), no batch systems (real-time data), and promising performance without data loss fear. Keeping all the features in mind Kafka and Kafka connect is the best solution so far to integrate different sources and sinks in one architecture to have very robust and reliable results.
We will Depp drive and implement such a solution using Debezium Kafka connect to achieve a very robust pipeline of data from one application into Mongo and then into Elastic cluster.



