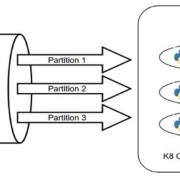
Thanks to services provided by AWS, GCP, and Azure it’s become relatively easy to develop applications that span multiple regions. This is great because slow apps kill businesses. There is one common problem with these applications: they are not supported by multi-region database architecture.
In this blog, I will provide a solution for the problem of getting Kubernetes pods to talk to each other in multi-region deployments.