Dans cette quatrième partie, nous allons apprendre à valider les messages CDC avec Schemaverse, un outil puissant et facile à utiliser pour la validation des données.
## C’est la partie quatre d’une série de billets de blog sur la construction d’un système moderne à événements avec Memphis.dev.
In this blog post, we will focus on how to use the data captured by Debezium in Memphis.dev to build an event-driven system. We will cover topics such as setting up a data pipeline, creating an event-driven workflow, and deploying the system.
Ceci est la quatrième partie d’une série de billets de blog sur la construction d’un système moderne à événements à l’aide de Memphis.dev.
Dans les deux billets de blog précédents (partie 2 et partie 3), nous avons décrit comment mettre en œuvre une pipeline de capture des données de changement (CDC) pour MongoDB à l’aide de Debezium Server et Memphis.dev.
Dans ce billet de blog, nous nous concentrerons sur la façon d’utiliser les données capturées par Debezium dans Memphis.dev pour construire un système à événements. Nous aborderons des sujets tels que la mise en place d’une pipeline de données, la création d’un flux de travail à événements et le déploiement du système.
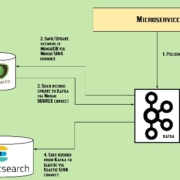
Pour commencer, nous devons configurer une pipeline de données pour récupérer les données capturées par Debezium et les envoyer à Memphis.dev. Pour ce faire, nous devons configurer un connecteur Kafka qui envoie les données à un canal Kafka, puis configurer un canal Kafka qui envoie les données à un canal Apache Pulsar. Une fois que la pipeline de données est configurée, nous pouvons commencer à créer des flux de travail à événements basés sur ces données.
Ensuite, nous devons créer un flux de travail à événements qui prend en charge le traitement des données capturées par Debezium. Pour ce faire, nous devons créer un modèle de données qui décrit le schéma des données capturées par Debezium et définir des règles pour le traitement des données. Une fois que le modèle et les règles sont définis, nous pouvons créer un flux de travail à événements qui prend en charge le traitement des données capturées par Debezium.
Enfin, nous devons déployer le système à événements que nous avons construit. Pour ce faire, nous devons déployer le connecteur Kafka et le canal Kafka sur un cluster Kafka, puis déployer le canal Apache Pulsar sur un cluster Pulsar. Une fois que tout est déployé, nous pouvons commencer à envoyer des données capturées par Debezium à notre système à événements et à traiter ces données selon les règles que nous avons définies.
En conclusion, nous avons vu comment utiliser les données capturées par Debezium dans Memphis.dev pour construire un système à événements. Nous avons vu comment configurer une pipeline de données pour récupérer les données capt