Les Namedtuples Python sont un moyen puissant pour améliorer la clarté et la lisibilité du code, en le rendant plus facile à comprendre et à maintenir.
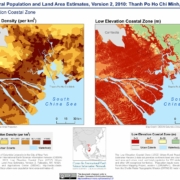
Le module de collection de Python a une fonctionnalité appelée «Namedtuple», un «Namedtuple» est un tuple avec des éléments nommés qui rendent le code plus expressif. Tout comme les dictionnaires dans Python, «Namedtuple» nous permet d’accéder aux éléments en utilisant un membre d’un tuple plutôt qu’un index.
The syntax for creating a namedtuple is as follows:
namedtuple(typename, field_names)
Where ‘typename’ is the name of the tuple and ‘field_names’ is a list of strings which are the names of the fields.
Utilisation d’un Namedtuple
Le module de collection de Python a une fonctionnalité appelée «Namedtuple», un «Namedtuple» est un tuple avec des éléments nommés qui rendent le code plus expressif. Tout comme les dictionnaires dans Python, «Namedtuple» nous permet d’accéder aux éléments en utilisant un membre d’un tuple plutôt qu’un index.
Créer un Namedtuple
Pour créer un namedtuple, nous devons utiliser la fonction «namedtuple» du module de collection.
La syntaxe pour créer un namedtuple est la suivante :
namedtuple (typename, field_names)
Où «typename» est le nom du tuple et «field_names» est une liste de chaînes qui sont les noms des champs.
Utilisation des Namedtuple dans le logiciel
Les Namedtuple peuvent être utilisés dans le logiciel pour stocker des données structurées. Par exemple, si vous avez une application qui stocke des informations sur les employés, vous pouvez créer un namedtuple pour stocker les informations sur chaque employé. Vous pouvez ensuite accéder aux informations sur un employé en utilisant le nom du champ.
Par exemple, si vous avez créé un namedtuple avec les champs «nom», «âge» et «emploi», vous pouvez accéder à l’âge d’un employé en utilisant le nom du champ :
employee.age
Les Namedtuple peuvent également être utilisés pour stocker des données dans des fichiers. Par exemple, si vous avez une application qui stocke des informations sur les employés dans un fichier CSV, vous pouvez lire le fichier et créer un namedtuple pour chaque ligne du fichier. Vous pouvez ensuite accéder aux informations sur un employé en utilisant le nom du champ.
Les Namedtuple sont très utiles pour stocker des données structurées et peuvent faciliter le développement de logiciels. Ils permettent aux développeurs de travailler plus efficacement et de rendre leurs applications plus robustes et fiables.