https://ankaa-pmo.com/wp-content/uploads/2022/11/google-cloud-for-beginners-how-to-choose-a-database-service.jpg375600Service comm.https://ankaa-pmo.com/wp-content/uploads/2017/04/Logo-Ankaa-engineering.pngService comm.2022-11-11 16:45:442022-11-11 16:45:44Google Cloud for Beginners – How To Choose a Database Service?
This article will demonstrate the heterogeneous systems integration and building of the BI system and mainly talk about the DELTA load issues and how to overcome them. How can we compare the source table and target table when we cannot find a proper way to identify the changes in the source table using the SSIS ETL Tool?
Systems Used
SAP S/4HANA is an Enterprise Resource Planning (ERP) software package meant to cover all day-to-day processes of an enterprise, e.g., order-to-cash, procure-to-pay, finance & controlling request-to-service, and core capabilities. SAP HANA is a column-oriented, in-memory relational database that combines OLAP and OLTP operations into a single system.
SAP Landscape Transformation (SLT) Replication is a trigger-based data replication method in the HANA system. It is a perfect solution for replicating real-time data or schedule-based replication from SAP and non-SAP sources.
Azure SQL Database is a fully managed platform as a service (PaaS) database engine that handles most of the management functions offered by the database, including backups, patching, upgrading, and monitoring, with minimal user involvement.
SQL Server Integration Services (SSIS) is a platform for building enterprise-level data integration and transformation solutions. SSIS is used to integrate and establish the pipeline for ETL and solve complex business problems by copying or downloading files, loading data warehouses, cleansing, and mining data.
Power BI is an interactive data visualization software developed by Microsoft with a primary focus on business intelligence.
Business Requirement
Let us first talk about the business requirements. We have more than 20 different Point-of-Sale (POS) data from other online retailers like Target, Walmart, Amazon, Macy’s, Kohl’s, JC Penney, etc. Apart from this, the primary business transactions will happen in SAP S/4HANA, and business users will require the BI reports for analysis purposes.
https://ankaa-pmo.com/wp-content/uploads/2022/11/sap-s-4hana-microsoft-sql-integration-and-hard-deletion-handling.jpg375600Service comm.https://ankaa-pmo.com/wp-content/uploads/2017/04/Logo-Ankaa-engineering.pngService comm.2022-11-08 13:53:122022-11-08 13:53:12SAP S/4HANA, Microsoft SQL Integration and Hard Deletion Handling
In recent years, an increasing number of enterprises began to use data to power decision-making, which yields new demands for data exploration and analytics. As database technologies evolve with each passing day, a variety of online analytical processing (OLAP) engines keep popping up. These OLAP engines have distinctive advantages and are designed to suit varied needs with different tradeoffs, such as data volume, performance, or flexibility.
This article compares two popular open-source engines, Apache Druid, and StarRocks, in several aspects that may interest you the most, including data storage, pre-aggregation, computing network, ease of use, and ease of O&M. It also provides star schema benchmark (SSB) test results to help you understand which scenario favors which more.
https://ankaa-pmo.com/wp-content/uploads/2022/03/apache-druid-vs-starrocks-a-deep-dive.jpg375600Service comm.https://ankaa-pmo.com/wp-content/uploads/2017/04/Logo-Ankaa-engineering.pngService comm.2022-03-16 01:21:072022-03-16 01:21:07Apache Druid vs StarRocks: A Deep Dive
SQL Server Analysis Services (SSAS) is used to create high-level aggregated views of data, allowing users to quickly create dynamic reports and dashboards to centralize business measurable values like Key Performance Indicators (KPIs).
In this article, we’ll cover how a user continued their analytics in SSAS after transferring terabytes of data into a Snowflake data warehouse.
https://ankaa-pmo.com/wp-content/uploads/2021/08/leveraging-olap-for-advanced-analytics-on-your-data-warehouse-with-ssas.jpg375600Service comm.https://ankaa-pmo.com/wp-content/uploads/2017/04/Logo-Ankaa-engineering.pngService comm.2021-08-12 05:37:072021-08-12 05:37:07Leveraging OLAP for Advanced Analytics on Your Data Warehouse With SSAS
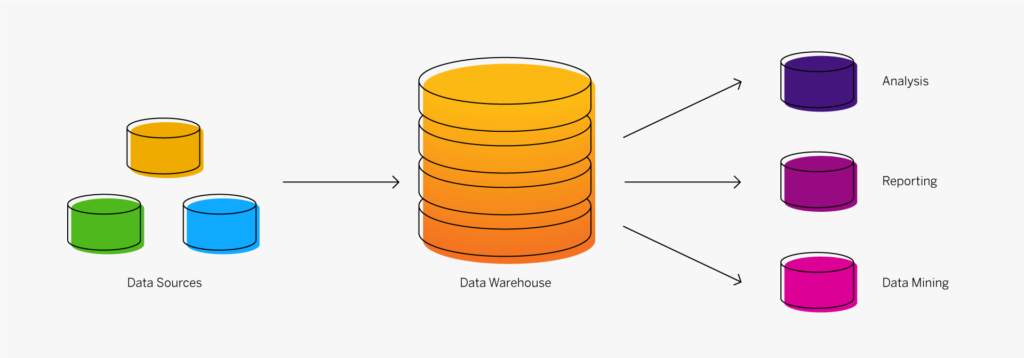
Un data warehouse (entrepôt de données) est un système de stockage numérique qui connecte et harmonise de grandes quantités de données provenant de nombreuses sources différentes. Il a pour but d’alimenter la Business Intelligence (BI), le reporting et l’analyse, ainsi que soutenir la conformité aux exigences réglementairesafin que les entreprises puissent exploiter leurs données et prendre des décisions intelligentes fondées sur les données. Les data warehouse stockent les données actuelles et historiques dans un seul et même endroit et constituent ainsi une source unique de vérité pour une organisation.
Les données sont envoyées vers un data warehouse à partir de systèmes opérationnels (tels qu’un système ERP ou CRM), de bases de données et de sources externes comme les systèmes partenaires, les appareils IoT, les applications météo ou les réseaux sociaux, généralement de manière régulière. L’émergence du cloud computing a changé la donne. Ces dernières années, le stockage des données a été déplacé de l’infrastructure sur site traditionnelle vers de multiples emplacements, y compris sur site, dans le Cloud privé et dans le Cloud public.
Les data warehouse modernes sont conçus pour gérer à la fois les données structurées et les données non structurées, comme les vidéos, les fichiers image et les données de capteurs. Certains utilisent les outils analytiques intégrés et la technologie de base de données in-memory (qui conserve l’ensemble de données dans la mémoire de l’ordinateur plutôt que dans l’espace disque) pour fournir un accès en temps réel à des données fiables et favoriser une prise de décision en toute confiance. Sans entreposage de données, il est très difficile de combiner des données provenant de sources hétérogènes, de s’assurer qu’elles sont au bon format pour les analyses et d’obtenir une vue des données sur le court terme et sur le long terme.
Avantages de l’entreposage de données
Un data warehouse bien conçu constitue la base de tout programme de BI ou d’analyse réussi. Son principal objectif est d’alimenter les rapports, les tableaux de bord et les outils analytiques devenus indispensables aux entreprises d’aujourd’hui. Un entrepôt de données fournit les informations dont vous avez besoin pour prendre des décisions basées sur les données et vous aide à faire les bons choix, que ce soit pour le développement de nouveaux produits ou la gestion des niveaux de stock. Un data warehouse présente de nombreux avantages. En voici quelques-uns :
Un meilleur reporting analytique : grâce à l’entreposage de données, les décideurs ont accès à des données provenant de plusieurs sources et n’ont plus besoin de prendre des décisions basées sur des informations incomplètes.
Des requêtes plus rapides : les data warehouse sont spécialement conçus pour permettre l’extraction et l’analyse rapides des données. Avec un entrepôt de données, vous pouvez très rapidement demander de grandes quantités de données consolidées avec peu ou pas d’aide du service informatique.
Une amélioration de la qualité des données : avant de charger les données dans l’entrepôt de données le système met en place des nettoyages de données afin de garantir que les données sont converties dans un seul et même format dans le but de faciliter les analyses (et les décisions), qui reposent alors sur des données précises et de haute qualité.
Une visibilité sur les données historiques : en stockant de nombreuses données historiques, un data warehouse permet aux décideurs d’analyser les tendances et les défis passés, de faire des prévisions et d’améliorer l’organisation au quotidien.
Que peut stocker un data warehouse ?
Lorsque les data warehouse sont devenus populaires à la fin des années 1980, ils étaient conçus pour stocker des informations sur les personnes, les produits et les transactions. Ces données, appelées données structurées, étaient bien organisées et mises en forme pour en favoriser l’accès. Cependant, les entreprises ont rapidement voulu stocker, récupérer et analyser des données non structurées, comme des documents, des images, des vidéos, des e-mails, des publications sur les réseaux sociaux et des données brutes issues de capteurs.
Un entrepôt de données moderne peut contenir des données structurées et des données non structurées. En fusionnant ces types de données et en éliminant les silos qui les séparent, les entreprises peuvent obtenir une vue complète et globale sur les informations les plus précieuses.
Termes clés
Il est essentiel de bien comprendre un certain nombre de termes en lien avec les data warehouse. Les plus importants ont été définis ci-dessous. Découvrez d’autres termes et notre FAQ dans notre glossaire.
Data warehouse et base de données
Les bases de données et les data warehouse sont tous deux des systèmes de stockage de données, mais diffèrent de par leurs objectifs. Une base de données stocke généralement des données relatives à un domaine d’activité particulier. Un entrepôt de données stocke les données actuelles et historiques de l’ensemble de l’entreprise et alimente la BI et les outils analytiques. Les data warehouse utilisent un serveur de base de données pour extraire les données présentes dans les bases de données d’une organisation et disposent de fonctionnalités supplémentaires pour la modélisation des données, la gestion du cycle de vie des données, l’intégration des sources de données, etc.
Data warehouse et lac de données
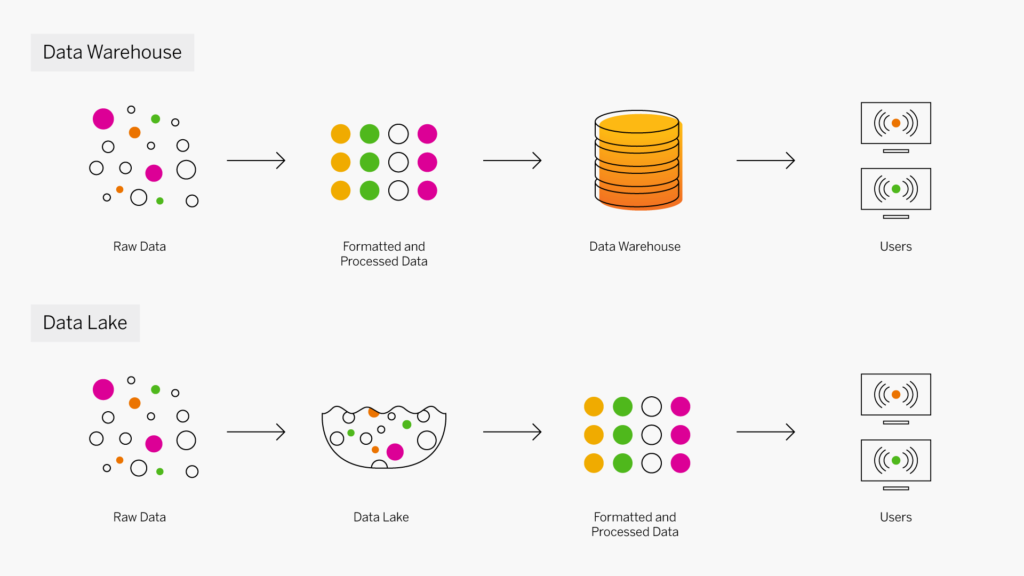
Les data warehouse et les lacs de données sont utilisés pour stocker le Big Data, mais sont des systèmes de stockage très différents. Un data warehouse stocke des données qui ont été formatées dans un but spécifique, tandis qu’un lac de données stocke les données dans leur état brut, non traité, dont l’objectif n’a pas encore été défini. Les entrepôts de données et les lacs de données se complètent souvent. Par exemple, lorsque des données brutes stockées dans un lac s’avèrent utiles pour répondre à une question, elles peuvent être extraites, nettoyées, transformées et utilisées dans un data warehouse à des fins d’analyse. Le volume de données, les performances de la base de données et les coûts du stockage jouent un rôle important dans le choix de la solution de stockage adaptée.
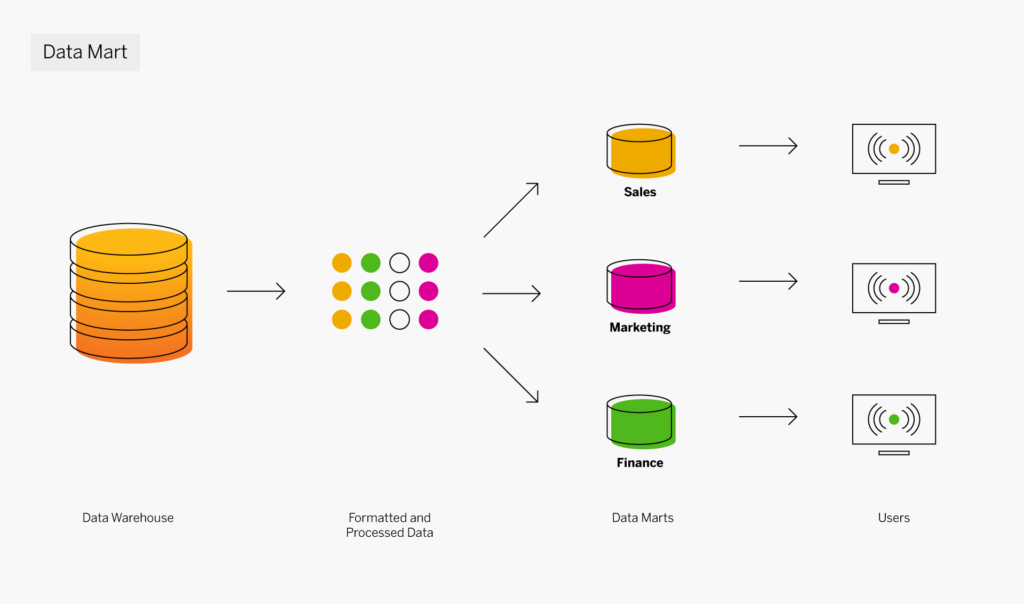
Data warehouse et datamart
Un datamart est une sous-section d’un data warehouse, partitionné spécifiquement pour un service ou un secteur d’activité, comme les ventes, le marketing ou la finance. Certains datamarts sont également créés à des fins opérationnelles autonomes. Alors qu’un data warehouse sert de magasin de données central pour l’ensemble de l’entreprise, un datamart utilise des données pertinentes à un groupe d’utilisateurs désigné. Ces utilisateurs peuvent alors accéder plus facilement aux données, accélérer leurs analyses et contrôler leurs propres données. Plusieurs datamarts sont souvent déployés dans un data warehouse.
Quels sont les composants clés d’un data warehouse ?
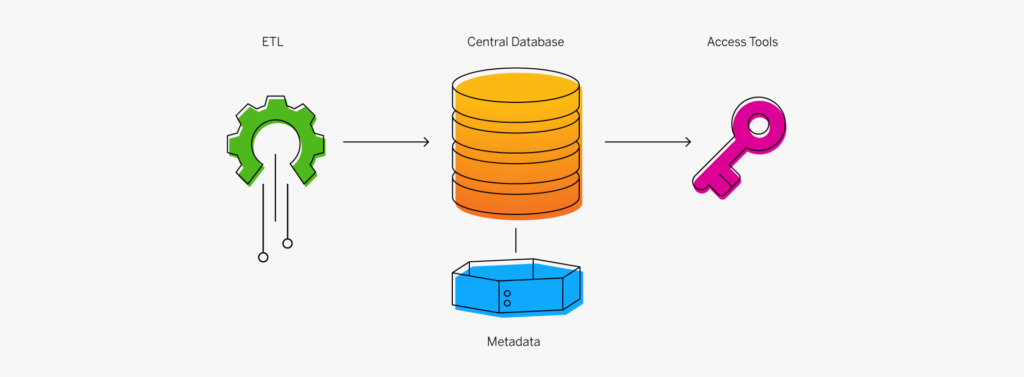
Un data warehouse classique comporte quatre composants principaux : une base de données centrale, des outils ETL (extraction, transformation, chargement), des métadonnées et des outils d’accès. Tous ces composants sont conçus pour être rapides afin de vous assurer d’obtenir rapidement des résultats et vous permettre d’analyser les données à la volée.
Base de données centrale : une base de données sert de fondement à votre data warehouse. Depuis le départ, on utilisait essentiellement des bases de données relationnelles standard exécutées sur site ou dans le Cloud. Mais en raison du Big Data, du besoin d’une véritable performance en temps réel et d’une réduction drastique des coûts de la RAM, les bases de données in-memory sont en train de monter en puissance.
Intégration des données : les données sont extraites des systèmes source et modifiées pour aligner les informations afin qu’elles puissent être rapidement utilisées à des fins analytiques à l’aide de différentes approches d’intégration des données telles que l’ETL (extraction, transformation, chargement) et les services de réplication de données en temps réel, de traitement en masse, de transformation des données et de qualité et d’enrichissement des données.
Métadonnées : les métadonnées sont des données relatives à vos données. Elles indiquent la source, l’utilisation, les valeurs et d’autres fonctionnalités des ensembles de données présents dans votre data warehouse. Il existe des métadonnées de gestion, qui ajoutent du contexte à vos données, et des métadonnées techniques, qui décrivent comment accéder aux données, définissent leur emplacement ainsi que leur structure.
Outils d’accès du data warehouse : les outils d’accès permettent aux utilisateurs d’interagir avec les données de votre data warehouse. Exemples d’outils d’accès : outils de requête et de reporting, outils de développement d’applications, outils d’exploration de données et outils OLAP.
Architecture de data warehouse
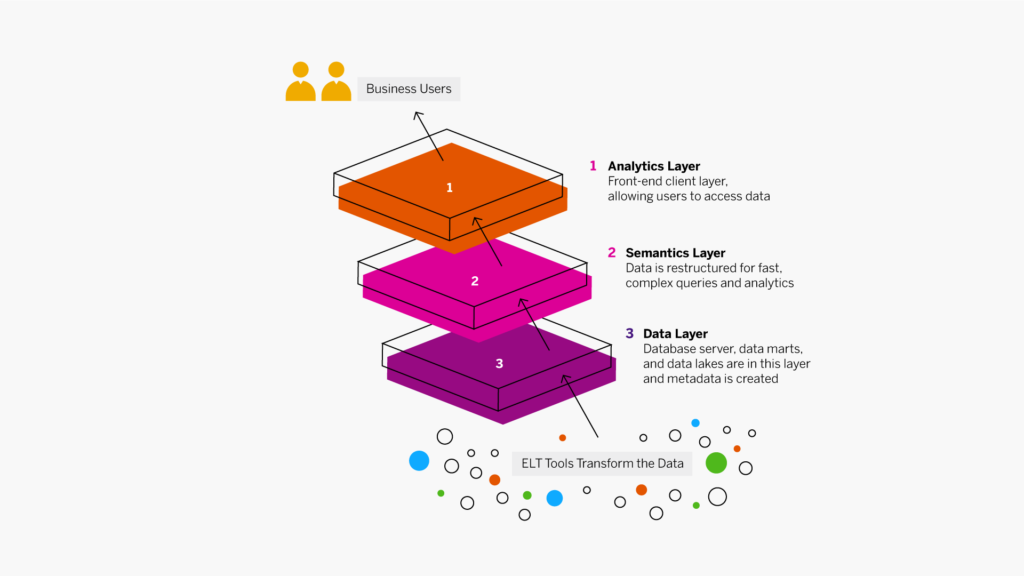
Auparavant, les data warehouse fonctionnaient par couches, lesquelles correspondaient au flux des données de gestion.
Couche de données
Les données sont extraites de vos sources, puis transformées et chargées dans le niveau inférieur à l’aide des outils ETL. Le niveau inférieur comprend votre serveur de base de données, les datamarts et les lacs de données. Les métadonnées sont créées à ce niveau et les outils d’intégration des données, tels que la virtualisation des données, sont utilisés pour combiner et agréger les données en toute transparence.
Couche sémantique
Au niveau intermédiaire, les serveurs OLAP (Online Analytical Processing) et OLTP (Online Transaction Processing) restructurent les données pour favoriser des requêtes et des analyses rapides et complexes.
Couche analytique
Le niveau supérieur est la couche du client frontend. Il contient les outils d’accès du data warehouse qui permettent aux utilisateurs d’interagir avec les données, de créer des tableaux de bord et des rapports, de suivre les KPI, d’explorer et d’analyser les données, de créer des applications, etc. Ce niveau inclut souvent un workbench ou une zone de test pour l’exploration des données et le développement de nouveaux modèles de données.
Un data warehouse standard comprend les trois couches définies ci-dessus. Aujourd’hui, les entrepôts de données modernes combinent OLTP et OLAP dans un seul système.
Les data warehouse, conçus pour faciliter la prise de décision, ont été essentiellement créés et gérés par les équipes informatiques. Néanmoins, ces dernières années, ils ont évolué pour renforcer l’autonomie des utilisateurs fonctionnels, réduisant ainsi leur dépendance aux équipes informatiques pour accéder aux données et obtenir des informations exploitables. Parmi les fonctionnalités clés d’entreposage de données qui ont permis de renforcer l’autonomie des utilisateurs fonctionnels, on retrouve les suivantes :
La couche sémantique ou de gestion fournit des expressions en langage naturel et permet à tout le monde de comprendre instantanément les données, de définir des relations entre les éléments dans le modèle de données et d’enrichir les zones de données avec de nouvelles informations.
Les espaces de travail virtuels permettent aux équipes de regrouper les connexions et modèles de données dans un lieu sécurisé et géré, afin de mieux collaborer au sein d’un espace commun, avec un ensemble de données commun.
Le Cloud a encore amélioré la prise de décision en permettant aux employés de disposer d’un large éventail d’outils et de fonctionnalités pour effectuer facilement des tâches d’analyse des données. Ils peuvent connecter de nouvelles applications et de nouvelles sources de données sans avoir besoin de faire appel aux équipes informatiques.
Kate Wright, responsable de la Business Intelligence augmentée chez SAP, évoque la valeur d’un data warehouse Cloud moderne.
Les 7 principaux avantages d’un data warehouse Cloud
Les data warehouse Cloud gagnent en popularité, à juste titre. Ces entrepôts modernes offrent plusieurs avantages par rapport aux versions sur site traditionnelles. Voici les sept principaux avantages d’un data warehouse Cloud :
Déploiement rapide : grâce à l’entreposage de données Cloud, vous pouvez acquérir une puissance de calcul et un stockage de données presque illimités en quelques clics seulement, et créer votre propre data warehouse, datamarts et systèmes de test en quelques minutes.
Faible coût total de possession (TCO) : les modèles de tarification du data warehouse en tant que service (DWaaS) sont établis de sorte que vous payez uniquement les ressources dont vous avez besoin, lorsque vous en avez besoin. Vous n’avez pas besoin de prévoir vos besoins à long terme ou de payer pour d’autres traitements tout au long de l’année. Vous pouvez également éviter les coûts initiaux tels que le matériel coûteux, les salles de serveurs et le personnel de maintenance. Séparer les coûts du stockage des coûts informatiques vous permet également de réduire les dépenses.
Élasticité : un data warehouse Cloud vous permet d’ajuster vos capacités à la hausse ou à la baisse selon vos besoins. Le Cloud offre un environnement virtualisé et hautement distribué capable de gérer d’immenses volumes de données qui peuvent diminuer ou augmenter.
Sécurité et restauration après sinistre : dans de nombreux cas, les data warehouse Cloud apportent une sécurité des données et un chiffrage plus forts que les entrepôts sur site. Les données sont également automatiquement dupliquées et sauvegardées, ce qui vous permet de minimiser le risque de perte de données.
Technologies en temps réel : les data warehouse Cloud basés sur la technologie de base de données in-memory présentent des vitesses de traitement des données extrêmement rapides, offrant ainsi des données en temps réel et une connaissance instantanée de la situation.
Nouvelles technologies : les data warehouse Cloud vous permettent d’intégrer facilement de nouvelles technologies telles que l’apprentissage automatique, qui peuvent fournir une expérience guidée aux utilisateurs fonctionnels et une aide décisionnelle sous la forme de suggestions de questions à poser, par exemple.
Plus grande autonomie des utilisateurs fonctionnels : les data warehouse Cloud offrent aux employés, de manière globale et uniforme, une vue unique sur les données issues de nombreuses sources et un vaste ensemble d’outils et de fonctionnalités pour effectuer facilement des tâches d’analyse des données. Ils peuvent connecter de nouvelles applications et de nouvelles sources de données sans avoir besoin de faire appel aux équipes informatiques.
L’entreposage de données prend en charge l’analyse complète des dépenses de l’entreprise par service, fournisseur, région et statut, pour n’en citer que quelques-unes.
Meilleures pratiques concernant l’entreposage des données
Pour atteindre vos objectifs et économiser du temps et de l’argent, il est recommandé de suivre certaines étapes éprouvées lors de la création d’un data warehouse ou l’ajout de nouvelles applications à un entrepôt existant. Certaines sont axées sur votre activité tandis que d’autres s’inscrivent dans le cadre de votre programme informatique global. Vous pouvez commencer avec la liste de meilleures pratiques ci-dessous, mais vous en découvrirez d’autres au fil de vos collaborations avec vos partenaires technologiques et de services.
Meilleures pratiques métier
Meilleures pratiques informatiques
Définir les informations dont vous avez besoin. Une fois que vous aurez cerné vos besoins initiaux, vous serez en mesure de trouver les sources de données qui vous aideront à les combler. La plupart du temps, les groupes commerciaux, les clients et les fournisseurs auront des recommandations à vous faire.
Surveiller la performance et la sécurité. Les informations de votre data warehouse sont certes précieuses, mais elles doivent quand même être facilement accessibles pour apporter de la valeur à l’entreprise. Surveillez attentivement l’utilisation du système pour vous assurer que les niveaux de performance sont élevés.
Documenter l’emplacement, la structure et la qualité de vos données actuelles. Vous pouvez ensuite identifier les lacunes en matière de données et les règles de gestion pour transformer les données afin de répondre aux exigences de votre entrepôt.
Gérer les normes de qualité des données, les métadonnées, la structure et la gouvernance. De nouvelles sources de données précieuses sont régulièrement disponibles, mais nécessitent une gestion cohérente au sein d’un data warehouse. Suivez les procédures de nettoyage des données, de définition des métadonnées et de respect des normes de gouvernance.
Former une équipe. Cette équipe doit comprendre les dirigeants, les responsables et le personnel qui utiliseront et fourniront les informations. Par exemple, identifiez le reporting standard et les KPI dont ils ont besoin pour effectuer leurs tâches.
Fournir une architecture agile. Plus vos unités d’affaires et d’entreprise utiliseront les données, plus vos besoins en matière de datamarts et d’entrepôts augmenteront. Une plate-forme flexible s’avérera bien plus utile qu’un produit limité et restrictif.
Hiérarchiser vos applications de data warehouse. Sélectionnez un ou deux projets pilotes présentant des exigences raisonnables et une bonne valeur commerciale.
Automatiser les processus tels que la maintenance. Outre la valeur ajoutée apportée à la Business Intelligence, l’apprentissage automatique peut automatiser les fonctions de gestion technique du data warehouse pour maintenir la vitesse et réduire les coûts d’exploitation.
Choisir un partenaire technologique compétent pour l’entrepôt de données. Ce dernier doit offrir les services d’implémentation et l’expérience dont vous avez besoin pour la réalisation de vos projets. Assurez-vous qu’il puisse répondre à vos besoins en déploiement, y compris les services Cloud et les options sur site.
Utiliser le Cloud de manière stratégique. Les unités d’affaires et les services ont des besoins en déploiement différents. Utilisez des systèmes sur site si nécessaire et misez sur des data warehouse Cloud pour bénéficier d’une évolutivité, d’une réduction des coûts et d’un accès sur téléphone et tablette.
Développer un bon plan de projet. Travaillez avec votre équipe sur un plan et un calendrier réalistes qui rendent possible les communications et le reporting de statut.
En résumé
Les data warehouse modernes, et, de plus en plus, les data warehouse Cloud, constitueront un élément clé de toute initiative de transformation numérique pour les entreprises mères et leurs unités d’affaires. Les data warehouse exploitent les systèmes de gestion actuels, en particulier lorsque vous combinez des données issues de plusieurs systèmes internes avec de nouvelles informations importantes provenant d’organisations externes.
Les tableaux de bord, les indicateurs de performance clés, les alertes et le reporting répondent aux exigences des cadres dirigeants, de la direction et du personnel, ainsi qu’aux besoins des clients et des fournisseurs importants. Les data warehouse fournissent également des outils d’exploration et d’analyse de données rapides et complexes, et n’ont pas d’impact sur les performances des autres systèmes de gestion.
Découvrez la solution SAP Data Warehouse Cloud
Unifiez vos données et analyses pour prendre des décisions avisées et obtenir la flexibilité nécessaire pour un contrôle efficace des coûts, notamment grâce à un paiement selon l’utilisation.
Avec la licence Enterprise Edition, vous accéderez sans restrictions à la base de données SAP HANA. Découvrez en quoi le passage à une licence full use peut être avantageux pour vos données et applications métiers.
Il y a 10 ans, SAP présentait un outil de gestion de bases de données de nouvelle génération, SAP HANA. Une offre présentant plusieurs caractéristiques clés :
In memory : les données sont lues et écrites en mémoire, pour des performances extrêmes
Orienté lignes : ce mode permet d’optimiser l’écriture (un enregistrement par ligne)
Orienté colonnes : ce mode facilite les requêtes (un type de données par colonne)
Cette double casquette ligne/colonne permet à SAP HANA d’adresser à la fois les traitements transactionnels et analytiques. Des technologies avancées gravitent autour de ce cœur : serveur d’applications, scripting, prédictif, Machine Learning, vues OLAP, graphes, gestion des données spatiales…
L’ensemble propose à la fois une connexion aux applications SAP (BICS) ou non (SQL et MDX). Il est également possible d’accéder à des sources de données tierces via Smart Data Streaming et Smart Data Access et aussi d’intégrer quasiment n’importe quel type de données, structurées ou non, jusqu’aux sources Hadoop, au travers de Smart Data Integration. Tout ceci est combiné avec des fonctions de partionning, de haute disponibilité, de répartition de charge, de parallélisation des requêtes, d’aide à la reprise d’activité, etc.
SAP HANA est aujourd’hui au cœur de nombreuses applications SAP. Il est également possible de l’utiliser en mode autonome. « Dans les deux cas, l’ensemble des fonctionnalités est disponible, car il n’existe qu’une seule version de SAP HANA », explique Olivier Demeusy, Director at Center of Excellence, EMEA North for SAP Business Technology Platform.
Runtime VS Enterprise
La principale différence entre SAP HANA Runtime Edition et SAP HANA Enterprise Edition réside dans le mode d’accès à la base de données et les restrictions s’y appliquant :
L’édition Runtime est conçue pour les applications SAP et ne peut être adressée qu’à travers ces applications
L’édition Enterprise est accessible sans restrictions depuis n’importe quel système ou application, SAP ou non.
La Runtime Edition n’autorise donc l’interaction avec la base de données qu’au travers des applications SAP, qui vont se charger de lancer les requêtes. L’Enterprise Edition est pour sa part accessible depuis les applications SAP, des applications tierces ou vos propres applicatifs métiers.
L’accès pourra se faire en direct au travers de requêtes SQL. Les fonctions d’intégration et de qualité de données pourront être librement exploitées, tout comme les moteurs avancés de SAP HANA. Enfin, de multiples ponts seront accessibles afin de lier du code métier à SAP HANA. Et ce jusqu’à l’hébergement de vos applications dans SAP HANA. SAP HANA XS Advanced permet en effet le développement d’applications natives SAP HANA, capables de fonctionner au plus près de la donnée.
Un changement de licence facilité
Passer de la Runtime Edition à l’Enterprise Edition est aisé, SAP HANA restant identique dans les deux cas. « Le passage d’une licence à l’autre ne se traduit par aucun changement technique », confirme Olivier Demeusy.
Le tarif comprend un coût d’acquisition et une maintenance annuelle. « Le tarif appliqué dépend directement du volume de données qui sera pris en charge par SAP HANA, avec un calcul effectué par blocs de 64 Go. » Que vous utilisiez une base de données de 500 Go ou de 20 To, vous aurez donc toujours la garantie de bénéficier d’une offre parfaitement ajustée.
https://ankaa-pmo.com/wp-content/uploads/2017/04/Logo-Ankaa-engineering.png00Service comm.https://ankaa-pmo.com/wp-content/uploads/2017/04/Logo-Ankaa-engineering.pngService comm.2020-10-13 11:45:472020-10-13 11:45:47Exploitez la puissance de SAP HANA dans vos applications, avec une licence full use
As an application architect, eventually, you’d choose the database or database service to power your newest application or a microservice. Selecting one of the databases among relational databases was easier. The use cases were roughly divided into OLTP and OLAP (decision support). The workload differences between OLTP and OLAP were well known. OLTP workloads consist of short transactions on few random rows, expecting millisecond responses on pre-compiled queries; OLAP workloads consist of data loads, long-running queries scanning millions of rows of a fact table of a star/snowflake schema. Each had the performance benchmark and TCO well defined, measured and audited via TPC benchmarks. You can make use of these numbers, approximate your workload, understand the needs and capabilities match on other fronts like administration.
Then, there are NoSQL databases. NoSQL databases were invented to handle the webscale performance of operational applications. It had to be elastic to handle the scale and tolerate nodes going down (aka partition tolerance). That sparked the innovation to create databases on a variety of data models and use cases. There are databases for JSON, graphs, time-series and more. From Azure databases to ZODB, from Couchbase to Cassandra. MongoDB to TiDB, spatial to JSON databases — so many different kinds of databases. In fact, NoSQL-databases.org lists 225 databases as of November 2018.
Paramètres des cookies et politique de confidentialité
Comment nous utilisons les cookies
Nous utilisons les cookies pour nous faire savoir quand vous visitez nos sites Web, comment vous interagissez avec nous, pour enrichir votre expérience utilisateur et pour personnaliser votre relation avec notre site Web.
Cliquez sur les différents titres de catégories pour en savoir plus. Vous pouvez également modifier certaines de vos préférences. Notez que le blocage de certains types de cookies peut avoir un impact sur votre expérience sur nos sites Web et les services que nous sommes en mesure d'offrir.
Cookies essentiels sur ce site
These cookies are strictly necessary to provide you with services available through our website and to use some of its features.
Because these cookies are strictly necessary to deliver the website, you cannot refuse them without impacting how our site functions. You can block or delete them by changing your browser settings and force blocking all cookies on this website.
Cookies Google Analytics
Ces cookies recueillent des renseignements qui sont utilisés sous forme agrégée pour nous aider à comprendre comment notre site Web est utilisé ou l'efficacité de nos campagnes de marketing, ou pour nous aider à personnaliser notre site Web et notre application pour vous afin d'améliorer votre expérience.
Si vous ne voulez pas que nous suivions votre visite sur notre site, vous pouvez désactiver le suivi dans votre navigateur ici :
Autres services
Nous utilisons également différents services externes comme Google Webfonts, Google Maps et les fournisseurs externes de vidéo. Comme ces fournisseurs peuvent collecter des données personnelles comme votre adresse IP, nous vous permettons de les bloquer ici. Veuillez noter que cela pourrait réduire considérablement la fonctionnalité et l'apparence de notre site. Les changements prendront effet une fois que vous aurez rechargé la page.
.
Paramètres de Google Webfont Settings :
Google Map :
Vimeo et Youtube :
Politique de confidentialité
Vous pouvez lire nos cookies et nos paramètres de confidentialité en détail sur la page suivante