Directement intégré aux solutions qui alimentent les processus les plus critiques,
Joule est un copilote qui comprend vraiment l’entreprise.
WALLDORF, Allemagne – le 26 septembre 2023 — SAP SE (NYSE: SAP) a présenté aujourd’hui Joule, un copilote d’intelligence artificielle générative en langage naturel, destiné à transformer la manière dont les entreprises fonctionnent. Joule sera intégré à l’ensemble du portefeuille d’entreprises ayant choisi les solutions cloud de SAP, qui fournissent des informations proactives et contextualisées, issues de l’ensemble de la gamme de solutions SAP, ainsi que de sources tierces. En triant et en contextualisant rapidement des réseaux complexes de données d’entreprises cloisonnées, le nouvel assistant est en mesure de proposer des aperçus complets. Grâce à l’IA générative, Joule améliore la productivité en entreprise et favorise l’atteinte de meilleurs résultats commerciaux, de manière sécurisée et en conformité avec les règlementations. Joule s’inscrit dans la lignée des innovations révolutionnaires de SAP, faisant ses preuves avec des résultats concrets.
Joule : une intégration dans l’écosystème de solutions SAP
“Avec près de 300 millions d’utilisateurs professionnels dans le monde entier qui travaillent régulièrement avec les solutions cloud de SAP, Joule a le pouvoir de redéfinir la manière dont les entreprises – et leurs employés – travaillent“, déclare Christian Klein, PDG et membre du conseil exécutif de SAP SE. “Joule s’appuie sur la position unique de SAP, au carrefour des écosystèmes de l’entreprise et de la technologie, et repose sur l’approche pertinente, fiable et responsable de l’IA métier que nous avons initiée pour continuer à aider nos clients à résoudre leurs problèmes les plus urgents. Joule comprendra ce que vous voulez dire, pas seulement ce que vous dites.”
Joule sera intégré aux applications SAP, de la gestion des Ressources Humaines à la Finance, en passant par la Supply Chain, les Achats et la User Expérience, ainsi qu’à la plateforme technologique commerciale de SAP.
La capacité de s’adapter à une multitude de cas concrets
Le fonctionnement est simple : les employés posent les questions qu’ils souhaitent ou exposent un problème à résoudre, en langage clair, et reçoivent des réponses intelligentes tirées des données commerciales, de textes, d’images et d’informations provenant de l’ensemble du portefeuille de solutions SAP, ainsi que de sources tierces.
| Imaginez, par exemple, un fabricant demander à Joule de l’aider à mieux comprendre les performances de ventes en magasin : en se connectant à un ensemble de données, Joule est capable de détecter un problème dans la chaîne d’approvisionnement et de proposer des solutions. Joule proposera continuellement et au fil du temps de nouveaux scénarios de plus en plus élaborés, et pour toutes les solutions. Pour les Ressources Humaines, par exemple, il aidera à rédiger des fiches de poste conformes et à générer des questions pertinentes pour les entretiens. |
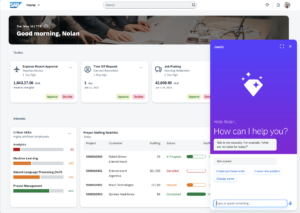
« À mesure que l’IA générative dépasse l’engouement initial, le travail visant à garantir un retour sur investissement mesurable commence », précise Phil Carter, vice-président du Groupe, Worldwide Thought Leadership Research, IDC. « SAP a compris que l’IA générative finira par faire partie intégrante de la vie courante et professionnelle de chacun d’entre-nous, et a pris le temps de construire un copilote business qui se concentre sur la réponse à des problématiques du monde réel. Par ailleurs, le Groupe a accordé une importance particulière à la mise en place de garde-fous nécessaires pour garantir la responsabilité des choix de Joule. »
Un déploiement progressif prévu à partir du mois de novembre
Joule sera disponible avant la fin de l’année avec les solutions SAP SuccessFactors et SAP Start, puis avec SAP S/4HANA Public Cloud Edition en début d’année prochaine. SAP Customer Experience, les solutions SAP Ariba et la plateforme technologique commerciale de SAP suivront avec de nombreuses autres mises à jour à venir dans l’ensemble du portefeuille de SAP, qui seront annoncées lors de SAP SuccessConnect du 2 au 4 octobre, SAP Spend Connect Live du 9 au 11 octobre, SAP Customer Experience Live du 25 octobre, et SAP TechEd du 2 au 3 novembre.
Joule s’appuie sur les offres Business AI existantes de SAP alors que plus de 26 000 clients cloud SAP ont maintenant accès à SAP Business AI. La stratégie globale de SAP visant à construire un écosystème d’IA d’avenir comprend des investissements directs, comme ceux annoncés en juillet avec Aleph Alpha, Anthropic et Cohere, ainsi que des partenariats avec des tiers, notamment ceux avec Microsoft, Google Cloud et IBM annoncés en mai 2023. Sapphire Ventures LLC, une société mondiale de capital-risque en logiciels soutenue par SAP, consacre plus d’un milliard de dollars au financement de start-ups technologiques d’entreprise alimentées par l’IA.
À propos de SAP
La stratégie de SAP est d’aider chaque organisation à fonctionner en « entreprise intelligente » et durable. En tant que leader du marché des logiciels d’application d’entreprise, nous aidons les entreprises de toutes tailles et de tous secteurs à opérer au mieux : 87 % du commerce mondial total est généré par nos clients. Nos technologies de Machine Learning, d’Internet des objets (IoT) et d’analyse avancée aident nos clients à transformer leurs activités en « entreprises intelligentes ». SAP permet aux personnes et aux organisations d’avoir une vision approfondie de leur business et favorise la collaboration pour qu’ils puissent garder une longueur d’avance sur leurs concurrents. Nous simplifions la technologie afin que les entreprises puissent utiliser nos logiciels comme elles le souhaitent, sans interruption. Notre suite d’applications et de services end-to-end permet aux clients privés et publics de 25 secteurs d’activité dans le monde entier, de fonctionner de manière rentable, de s’adapter en permanence et de faire la différence. Grâce à un réseau mondial de clients, de partenaires, d’employés et de leaders d’opinion, SAP aide le monde à mieux fonctionner et à améliorer la vie de chacun.
Pour plus d’informations, visitez le site www.sap.com.
Contact presse : sylvie.lechevin@sap.com | sap@the-arcane.com
The post SAP annonce son nouvel assistant d’IA générative : Joule. appeared first on SAP France News.
Source de l’article sur sap.com



![Maîtrisez le programmation orientée données avec Java 21 Record et Pattern Matching [Vidéo]](https://ankaa-pmo.com/wp-content/uploads/2023/10/maitrisez-le-programmation-orientee-donnees-avec-java-21-record-et-pattern-matching-video-180x180.jpg)



