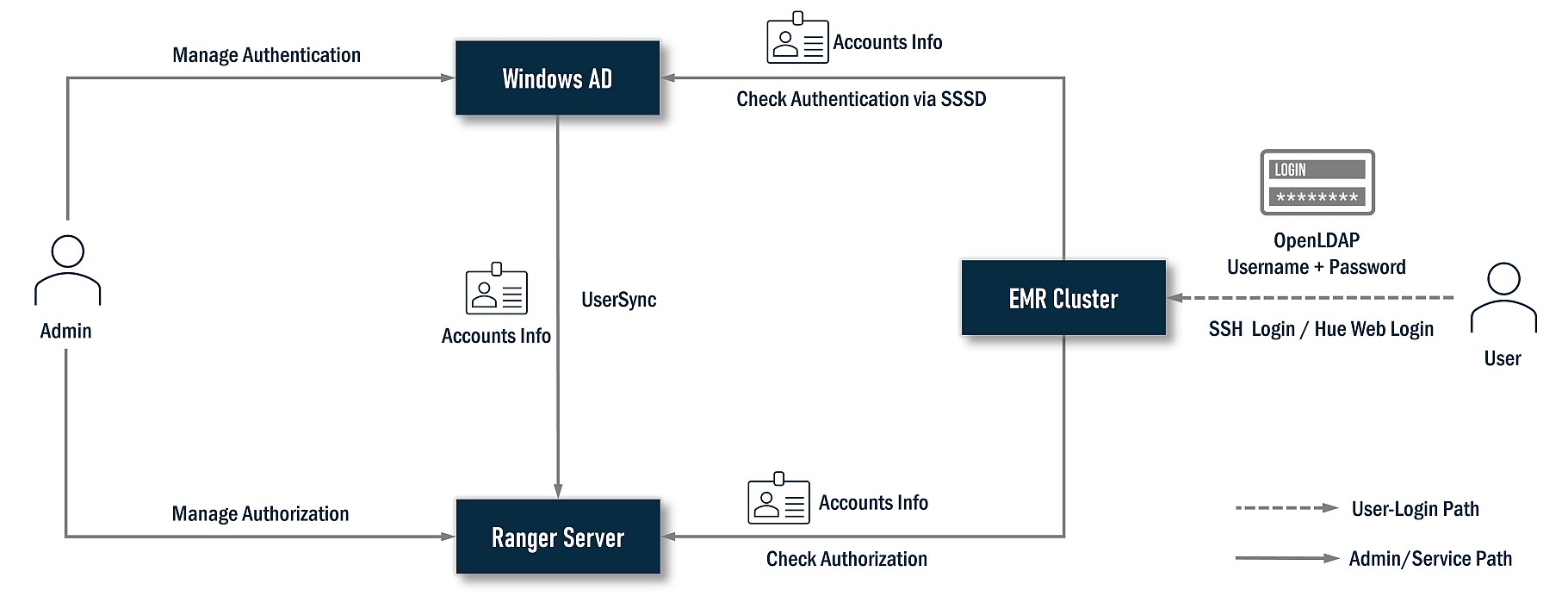
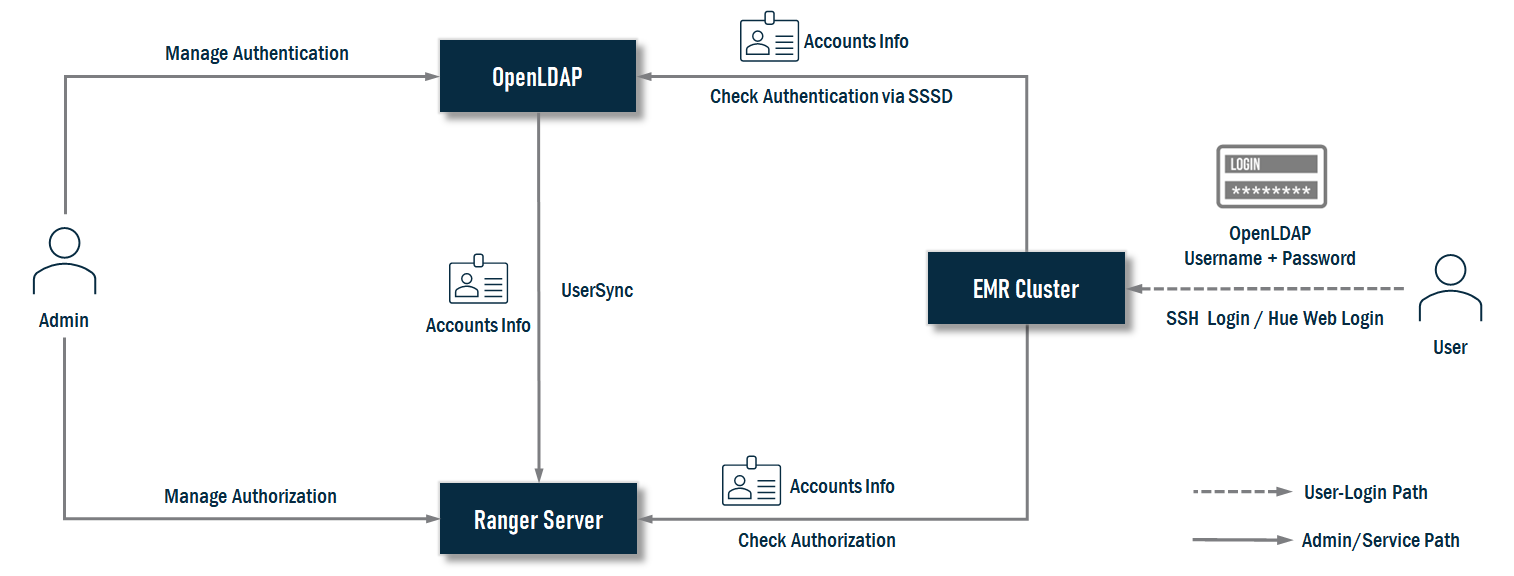
Avec API Gateway, vous pouvez facilement chaîner des requêtes API pour créer des solutions plus complexes et plus riches.
Pourquoi avons-nous besoin d’une demande API enchaînée?
La demande API enchaînée (ou demande de pipeline, ou appels API séquentiels) est une technique utilisée dans le développement logiciel pour gérer la complexité des interactions API lorsque le logiciel nécessite plusieurs appels API pour accomplir une tâche. Il est similaire au traitement des demandes par lots, où vous regroupez plusieurs demandes API en une seule demande et les envoyez au serveur en tant que lot. Bien qu’ils puissent sembler similaires, une demande de pipeline implique l’envoi d’une seule demande au serveur qui déclenche une séquence d’appels API à exécuter dans un ordre défini. Chaque demande API dans la séquence peut modifier les données de demande et de réponse, et la réponse d’une demande API est transmise en entrée à la prochaine demande API dans la séquence. Les demandes de pipeline peuvent être utiles lorsqu’un client doit exécuter une séquence de demandes API dépendantes qui doivent être exécutées dans un ordre spécifique.
Comment Apache APISIX API Gateway peut-il nous aider?
Apache APISIX est un moteur de routage et de mise en cache open source pour les services Web modernes. Il fournit une solution complète pour gérer les demandes API enchaînées. En utilisant Apache APISIX, vous pouvez créer des plugins personnalisés pour gérer les demandes client qui doivent être appelées en séquence. Par exemple, vous pouvez créer un plugin qui envoie une requête à l’API de recherche de produits, puis une requête à l’API de détails de produits pour récupérer des informations supplémentaires sur les produits. Apache APISIX fournit également des outils pour surveiller et analyser les performances des API, ce qui permet aux développeurs de mieux comprendre le comportement des API et d’améliorer leurs performances. Enfin, Apache APISIX fournit des fonctionnalités de sécurité pour protéger les données et les services contre les attaques malveillantes.
En conclusion, l’utilisation d’une demande API enchaînée peut aider à gérer la complexité des interactions API et à améliorer la qualité des services Web. Apache APISIX offre une solution complète pour gérer les demandes API enchaînées, y compris des outils pour surveiller et analyser les performances des API, ainsi que des fonctionnalités de sécurité pour protéger les données et les services contre les attaques malveillantes.