Dans notre précédent article intitulé « Et si l’avenir de la fiscalité passait par le système d’information ? », nous mettions en avant les besoins grandissants en termes de contrôles autour des fonctions fiscales. En effet, les entreprises sont soumises à de nombreuses réglementations ainsi qu’à une complexification de leur système d’information. Il devient donc nécessaire pour beaucoup d’entre elles de mettre en place des outils de « Tax Compliance ». Ils permettent de supporter les équipes fiscales et d’assurer le respect des obligations. Dans ce second article, nous illustrerons au travers des fonctionnalités offertes par un des outils du marché, SAP Tax Compliance, la valeur apportée par cette démarche d’outillée.
Que peut-on attendre d’un outil de Tax Compliance ?
De nombreux outils de Tax Compliance sont aujourd’hui présents sur le marché français et mondial. Ceux-ci diffèrent en fonction de la cible visée, de la PME nationale à la multinationale implantée dans de nombreux pays. Ils offrent des fonctionnalités plus ou moins avancées ainsi qu’une complexité de mise en œuvre plus ou moins lourde.
Néanmoins, nous pouvons regrouper les fonctionnalités offertes en deux grandes catégories :
- L’aide à la conformité des déclarations (a priori) :
- l’optimisation de l’élaboration de la liasse fiscale (élaboration, vérification et dématérialisation),
- la détermination de taux,
- la conformité de la facturation électronique,
- La déclaration de TVA (soumission, reporting et contrôles).
- La mise en place de contrôles afin de s’assurer de la conformité (a posteriori) :
- l’analyse du FEC,
- les contrôles sur les référentiels (fournisseurs, articles, etc.),
- les contrôles sur les transactions effectuées.
En complément, nous devons également prendre en compte le fait que les gouvernements exigent de plus en plus de données en temps réel, la qualité des données devient un prérequis clé pour la gestion des processus fiscaux et cela peut être amélioré en mettant en œuvre des contrôles fiscaux et en abordant les problèmes à la source, comme nous allons le voir avec l’outil SAP Tax Compliance.
Quels critères prendre en compte dans le choix de son outil de Tax Compliance
Le choix d’une solution doit être fondé sur les critères tant fonctionnels que techniques, pour répondre aux besoins suivants :
- Facilité d’installation et d’exploitation de la solution: évaluer le degré d’autonomie sur l’installation et le paramétrage du logiciel, ainsi que le degré d’intégration dans le paysage SI existant. Il est en effet important que les utilisateurs métiers aient un degré d’autonomie suffisant sur l’exploitation de l’outil pour ne pas avoir de besoin de solliciter les équipes IT pour la moindre opération dans l’outil
- Réponse aux besoins métier au travers de la couverture et richesse fonctionnelle: il est nécessaire d’évaluer la couverture d’un maximum de fonctionnalités et de contrôles standards, ainsi que la couverture géographique au travers d’une gestion multi-pays. Assurance de la facilité de prise en main par l’utilisateur final ou l’auditeur externe au travers d’une ergonomie conviviale et intuitive
- Exploitation des résultats simple et accessible : évaluer la facilité de compréhension et d’interprétation des résultats de contrôles, la facilité d’export sur des outils bureautiques, ainsi que la capacité de génération des rapports d’anomalie sous format.doc ou .pdf avec explication des résultats, annotations utilisateurs, etc.,
- L’intégration dans le paysage applicatif de l’entreprise est également primordiale dans le cas très fréquent où plusieurs ERP ou systèmes comptables cohabitent. Devoir multiplier les outils de Tax Compliance pour adresser les différents systèmes serait en effet contre-productif.
Présentation d’un outil : SAP TAX Compliance
SAP Tax Compliance propose une approche centralisée des contrôles de conformité, couvrant tout l’ensemble du processus, de la détection à la correction, en passant par le reporting et l’audit. À l’aide de l’apprentissage automatique à l’échelle de l’entreprise et de contrôles automatisés, l’application permet aux utilisateurs de détecter systématiquement les problèmes de conformité. Mais aussi d’améliorer la qualité des données fiscales, de rationaliser les corrections et d’atténuer rapidement le risque de non-conformité.
L’automatisation des processus de contrôle fiscal en temps quasi réel permet aux organisations de passer à des modèles de travail en continu. Elle permet aussi de résoudre les problèmes dès le début des processus ce qui est essentiel pour éviter de lourdes charges de travail à la fin de la période. Mais également de se conformer aux mandats les plus exigeants que les gouvernements introduisent dans le monde entier. En fait, avec l’introduction de la conformité numérique, la qualité des données fiscales est plus importante que jamais.
SAP Tax Compliance est une solution agnostique qui peut être intégré à SAP S/4HANA ou facilement déployé côte à côte. Elle peut aussi intégrer des données issues d’autres systèmes ERP (SAP ECC ou non SAP) ou spécialisés métiers (MDM, facturation, site de vente en ligne…). Cela offre ainsi la possibilité de capturer simultanément de gros volumes de données à partir de plusieurs systèmes. La solution offre également un apprentissage automatique natif et une intégration avec le workflow SAP. L’intérêt est de permettre l’automatisation et l’orchestration transparente des tâches de correction.
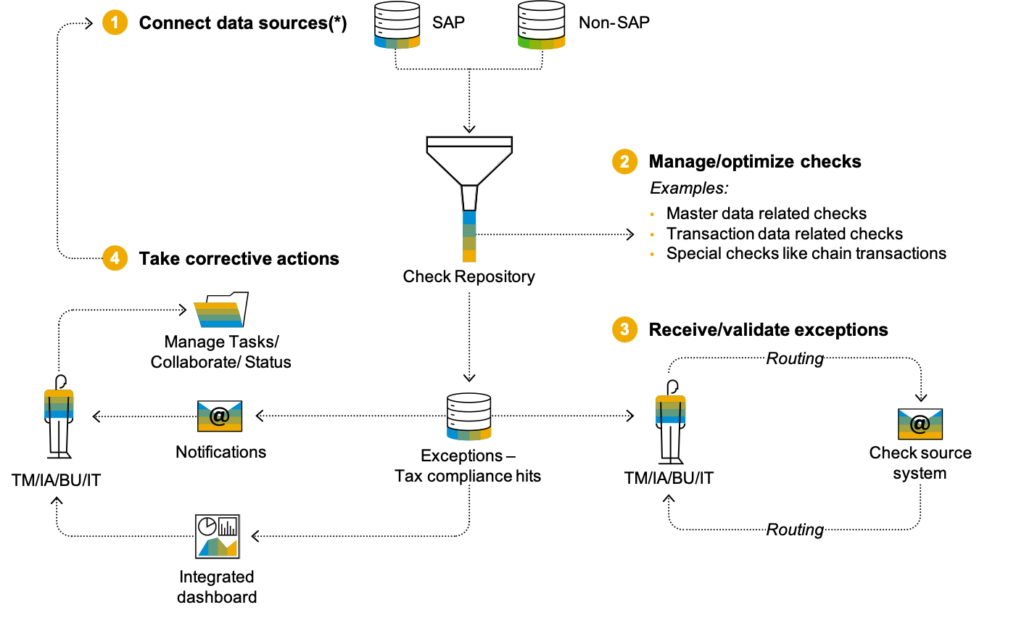
SAP Tax Compliance est fourni avec des règles de contrôles préconfigurées pour vous aider à démarrer et à améliorer immédiatement la qualité des données fiscales.
Par exemple, cela vous permet d’identifier et de corriger facilement les immatriculations de TVA manquantes sur les transactions intracommunautaires de l’UE ou les factures enregistrées sans code TVA. Vous pouvez également utiliser le moteur de détection pour faciliter l’examen des factures avec un montant de TVA très élevé. Ceci, permet de générer une réserve de travail pour examiner efficacement les exceptions sans avoir à identifier manuellement les éléments sur l’ensemble des transactions commerciales.
Il est également très flexible et permet d’enrichir facilement l’ensemble des règles de contrôles de la TVA aux droits de douane et autres taxes. Il permet également de relever constamment la barre en matière de conformité en développant vous-même des règles de contrôles fiscaux supplémentaires. Ou bien encore en intégrant le contenu prêt à l’emploi de notre partenaire Mazars.
Ces règles peuvent être facilement créées en définissant de nouvelles vues sur les données. Une fois celles-ci en place, le reste de la configuration peut être facilement complété via une assistance numérique fourni en tant qu’application Fiori qui guide l’utilisateur dans ses choix. Il s’agit de limiter l’implication du service informatique au développement réel des vues. Mais aussi de permettre aux utilisateurs métier d’adapter les contrôles, de réorganiser les listes de travail, de configurer le Machine Learning lorsque les données historiques sont suffisamment significatives. Ainsi que d’adapter les plannings en fonction des besoins de l’entreprise. Les utilisateurs métiers peuvent également gérer les tâches et les groupes d’utilisateurs correspondants responsables de l’achèvement. L’objectif est de garantir que la configuration en cours peut être facilement adaptée à mesure que l’entreprise évolue sans avoir recours à des experts informatiques qui sont toujours très demandés.
La solution permet également des simulations de paramétrages des règles de contrôle fiscal pour optimiser les contrôles et réduire les faux positifs.
SAP Tax Compliance fournit un tableau de bord centralisé pour obtenir des informations en temps réel sur l’état de conformité dans le monde entier. Il devient également un référentiel central de problèmes et de solutions qui peuvent être exploités pour conduire des améliorations en continu des processus. De plus, il permet d’empêcher les problèmes de se produire en premier lieu.
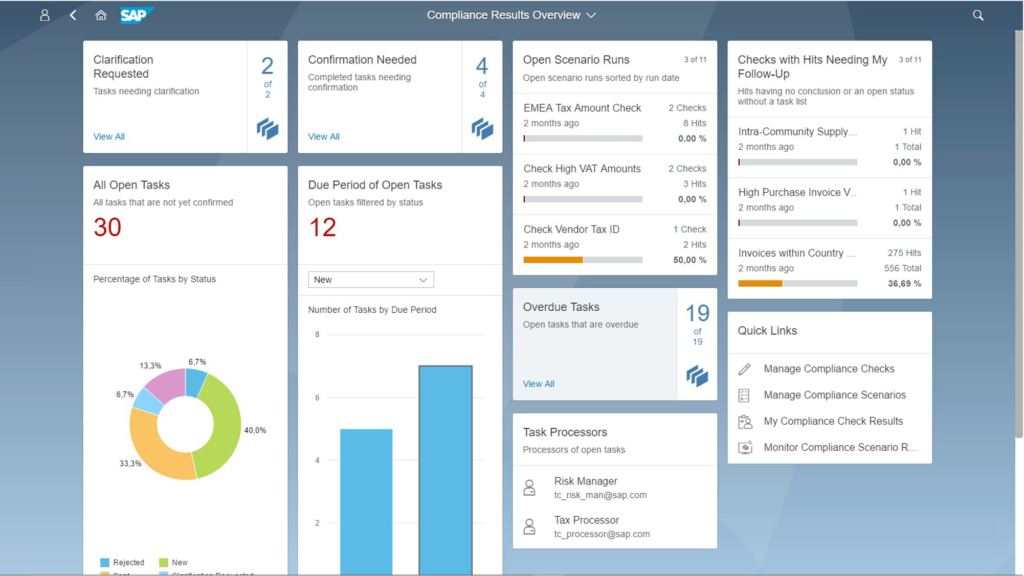
SAP Tax Compliance automatise au-delà de la détection, rationalisant l’ensemble du processus de correction. Il intègre des mécanismes d’apprentissage automatique prêt à l’emploi pour augmenter l’efficacité. De plus, il propose des modèles de workflow natifs pour orchestrer efficacement les tâches entre la myriade d’équipes qui doivent être impliquées dans le processus de correction.
Ces fonctionnalités d’apprentissage automatique peuvent être activées et maintenues par les utilisateurs métiers. Le but étant de libérer la puissance des données sans avoir besoin du support du département IT.
Comment réussir son projet de mise en place ?
Bien qu’il s’agisse d’un projet de mise en place d’outil, celui-ci ne doit pas être considéré comme un projet purement technique mais bien un projet global impliquant les acteurs métiers dès les premières phases. Il s’agit d’être sûr de ne pas se tromper d’objectif. Mais également de réellement apporter la valeur attendue pour toutes les parties prenantes.
C’est pour cela que nous préconisons la mise en place d’une équipe projet pluridisciplinaire. Une équipe qui regroupe les compétences financières, fiscales, juridiques, comptables et IT. Celle-ci est capable de cerner les besoins de la façon la plus exhaustive possible. Mais aussi de mettre en place une cartographie des risques et d’identifier les contrôles afférents.
Au-delà du module Tax compliance il peut être intéressant de disposer d’une solution complète pour la gestion fiscale de bout en bout qui couvre :
- Contrôles fiscaux pour améliorer la qualité des données fiscales et éviter les interruptions d’activité.
- Rapports électroniques en temps réel avec rapprochement complet pour une mise en conformité efficace.
SAP Tax Compliance offre une intégration transparente avec la nouvelle solution SAP Document and Reporting Compliance. Cette solution regroupe les anciennes solutions SAP pour la facturation numérique en temps réel (SAP Document Compliance) et la gestion des déclarations périodiques (SAP Advance Compliance Reporting ACR). Elle garantit que les problèmes identifiés soient rapidement suivis, que l’origine de ces déficiences soient analysées et résolues afin d’empêcher les interruptions d’activité.
Ces solutions SAP pour la facturation numérique en temps réel et la gestion des déclarations périodiques proposent déjà plus de 300 modèles pré-configurés de déclaration pour plus de 50 pays.
En synthèse, l’automatisation des contrôles et de la fonction fiscale devient de plus en plus nécessaire. L’obligation de bien s’outiller devient incontournable.
Vincent DOUX – SAP +33 6 03 43 72 95 v.doux@sap.com
Jérôme HUBER – Mazars +33 6 67 51 13 38 jerome.huber@mazars.fr
Vincent THEOT – Mazars +33 6 60 47 46 64 vincent.theot@mazars.fr
Heyfa LIMAM – Mazars +33 6 66 90 10 81 heyfa.limam@mazars.fr
Nicolas RICHARD – Mazars +33 6 66 61 91 35 nicolas.richard@mazars.fr
The post SAP Tax Compliance, un outil de transformation digitale des fonctions fiscales appeared first on SAP France News.