La gestion financière de l’entreprise déborde de beaucoup le pré carré qu’on lui attribue habituellement. Sa fonction première est de tenir les cordons de la bourse. Mais elle joue aussi un rôle essentiel dans le développement stratégique de l’entreprise. Des ressources humaines à l’expérience client, en passant par la logistique ou le marketing, la fonction finance doit pouvoir collaborer étroitement avec tous les acteurs de l’organisation. D’où l’importance de déployer un outil de gestion financière tenant compte de l’entreprise dans toute sa complexité. Un domaine dans lequel l’ERP a su démontrer son talent, aussi bien en matière de gestion financière, de gestion de comptabilité que d’analyse prospective.
Qu’est-ce qu’un ERP ?
Un ERP (Enterprise Resource Planning) ou PGI (Progiciel de Gestion Intégrée) permet aux entreprises de centraliser tout leur système d’information au sein d’un seul outil de gestion.
Le modèle de l’ERP a beaucoup évolué au fil des décennies. Grâce aux progrès de la numérisation et du cloud computing, il offre désormais une solution globale qui facilite la gestion de toutes les fonctions de l’entreprise, à commencer par la gestion financière.
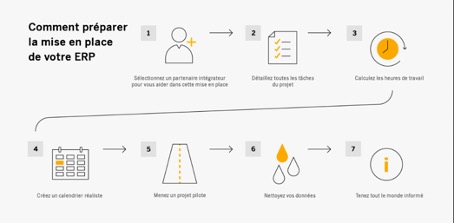
Le choix d’un ERP passe souvent par la définition précise des besoins et des objectifs des entreprises. Ces derniers varient non seulement en fonction du cœur de métier et de l’environnement concurrentiel, mais aussi de la structure même de l’entreprise. C’est pourquoi il est fréquent de sélectionner son ERP de gestion financière en fonction de la taille de son organisation : TPE, PME/PMI, ETI ou grande entreprise.
ERP ou logiciel de comptabilité ?
Durant de nombreuses années, la notion d’ERP a été associée au logiciel de comptabilité utilisé par les services comptables au sein de la plupart des entreprises. Encore aujourd’hui, l’apparition du terme ERP comptable démontre que les fonctionnalités de l’outil sont souvent résumées à la gestion de la comptabilité.
Il existe toutefois des ERP comptables qui représentent une évolution certaine dans le domaine du logiciel de comptabilité. Ils regroupent :
La gestion de la comptabilité générale ;
- L’analyse des écritures comptables ;
- Le Fichier des Ecritures Comptables, ou FEC, un document qu’il est obligatoire de transmettre à l’administration fiscale depuis 2014 ;
- Le rapprochement des écritures bancaires ;
- Les déclarations de TVA ;
- La comptabilisation des décaissements et encaissements ;
- La comptabilité des comptes clients et fournisseurs.
Toutes ces fonctionnalités sont incluses au sein d’un logiciel qui propose de nombreux autres outils : gestion des ressources humaines, logistique, suivi de la relation client, analyse des performances de vente, etc.
L’ERP finance, ou le FRP
Le terme FRP (ou Financial Resource Planning) est apparu dans les années 2000 pour désigner un nouveau type de logiciel de gestion financière. Il s’agit en premier lieu d’un produit orienté PME et grandes entreprises. Il leur permet de piloter leur gestion financière avec un outil de type ERP. Depuis, d’autres solutions logicielles ont été développées en reprenant le principe de l’ERP appliqué à la gestion financière de l’entreprise.
Aujourd’hui, les ERP proposent des fonctions utiles aux entreprises de toute taille, y compris dans la gestion de leurs finances. En effet, ils coordonnent gestion de comptabilité et gestion financière. De plus, ils apportent de nombreux autres bénéfices en termes de productivité, de rentabilité, de gestion des risques ou encore de stratégie marketing.
Quel ERP choisir pour votre gestion financière ?
L’utilité de l’ERP finance a été solidement démontrée pour les PME, les ETI et les entreprises de plus grande taille. Cependant, nombre d’entre elles hésitent encore sur le choix de leur progiciel de gestion intégrée. Deux cas de figure :
- Il s’agit d’une PME/ETI en cours de création ou n’ayant jamais fonctionné avec un ERP pour leur gestion financière ;
- Une première intégration a déjà eu lieu avec un ERP Finance. Mais, l’entreprise souhaite évoluer vers une nouvelle solution plus adaptée à ses besoins actuels. Un changement d’ERP peut s’imposer lorsque le logiciel actuel ne couvre plus tous les besoins de l’entreprise, ou bien lorsqu’il a atteint ses limites fonctionnelles.
Dans les 2 cas, PME ou entreprises de taille intermédiaire sont confrontées à une gamme de plus en plus étendue de progiciels, aux fonctionnalités toujours plus séduisantes. La première étape consiste donc à définir précisément les attentes de chaque entreprise pour sa fonction finance. Or, les besoins de cette dernière sont beaucoup plus importants qu’il n’y paraît. L’étude menée conjointement par Oxford Economics et SAP le démontre.
Un ERP finance pour soutenir la coopération stratégique entre vos services
Le rôle du service financier ne se réduit pas aux fonctions comptables et budgétaires de l’entreprise. C’est un acteur stratégique de son développement. En collaborant avec les autres services de l’entreprise, il apporte une visibilité essentielle à leur stratégie, grâce au soutien financier qu’il apporte.
Sur un panel de 255 cadres financiers interrogés dans le cadre de l’étude menée par SAP et Oxford Economics :
- 28 % déplorent le manque de coopération entre les différents services de l’entreprise ;
- 25 % estiment que leur entreprise connaît des difficultés à élaborer une analyse de rentabilité ou une orientation stratégique.
Les outils financiers de l’ERP doivent donc être adaptés à ce besoin de la fonction finance de participer à une stratégie de développement globale. Leur objectif permet de briser l’organisation « en silo » qui dresse une barrière hermétique entre les différents services.
Un outil de gestion financière pour faire face aux risques
En cette période marquée par l’apparition de la Covid-19 et ses conséquences majeures sur l’économie mondiale, la fonction finance est plus que jamais un acteur incontournable de la gestion du risque.
Une gestion financière harmonisée permet par conséquent de mieux anticiper les évolutions de l’entreprise :
- En fonction des changements de réglementation ;
- Sous la pression d’événements extérieurs : crises sanitaires, économiques, financières, etc.
Expérience client et expérience collaborateur
L’étude SAP/Oxford Economics soulève également la question de l’amélioration de l’expérience client et de l’expérience collaborateur. Un domaine de première importance, fréquemment souligné par les entreprises les plus performantes du marché.
Le rôle du directeur financier consiste dans ce cadre à coordonner les efforts des différents services : département commercial, gestion de la relation client, communication, etc. L’ERP Finance fait une fois encore office de ciment entre ces fonctions.
L’amélioration de l’expérience collaborateur est tout aussi essentielle. C’est même une problématique majeure pour le chef d’entreprise : fidélisation des employés, transmission de la culture d’entreprise, coopération, montée en compétences… Autant de questions essentielles à la santé et au développement de l’organisation.
Là aussi, la gestion du financement des formations professionnelles internes, la fluidité des relations entre RH et employés, l’optimisation des outils de paie, etc. font partie intégrante des responsabilités de l’équipe financière.
SAP : 3 ERP pour optimiser la gestion financière des PME et des ETI
Concepteur expert de solutions de gestion financière pour les entreprises de toutes tailles, SAP a mis au point différents ERP spécialement calibrés selon les besoins de votre PME ou de votre ETI. 3 ERP finance à découvrir dès aujourd’hui : SAP S/4HANA, SAP Business One et SAP Business ByDesign.
SAP S/4HANA
SAP S/4HANA est une solution ERP développée par SAP pour la base de données SAP HANA. Il est deployable sur cloud privé ou public, en interne ou sous une forme hybride. Ce progiciel intègre toutes les dernières évolutions numériques :
- Cloud Computing : facilitez l’accès aux données de l’entreprise à tous ses acteurs, sur un support 100 % sécurisé. Libérez de l’espace données avec la base In-Memory en colonnes ;
- UX optimisée : SAP S/4HANA mise sur une interface intuitive, accessible à tous les collaborateurs quelle que soit leur connaissance des nouvelles technologies ;
- Gestion financière facilitée : Grâce à l’IA intégrée et les fonctions d’analyse améliorées, les analyses et insights sont plus rapides. Votre service financier détient un outil conçu pour l’amélioration des performances de l’entreprise ;
- Réduction des coûts : optimisation de l’infrastructure informatique, rationalisation des flux, amélioration de la fonction logistique… L’usage d’un ERP Finance adapté fait partie des leviers budgétaires à actionner pour augmenter la rentabilité de l’entreprise.
SAP Business One
Cet ERP spécifiquement conçu pour les TPE et les PME prend le relais de votre logiciel de comptabilité pour vous permettre une gestion rationalisée de tous les processus métiers indispensables au fonctionnement de votre entreprise.
L’ERP est deployable sur Cloud ou in situ par le biais de la plateforme SAP HANA. Business One intègre la gestion de la comptabilité, la gestion des finances et toutes les fonctions stratégiques de l’entreprise au cœur d’un seul et même outil.
L’entreprise gagne en efficacité. Par conséquent, l’analyse de ses performances lui offre plus de visibilité, grâce à une interface accessible et adaptée aux besoins de vos collaborateurs. SAP Business One vous permet ainsi de passer à une nouvelle phase de votre développement. Son déploiement rapide et sa facilité d’exécution facilitent votre prise de décision dans tous les domaines.
SAP Business ByDesign
SAP Business ByDesign est une suite ERP complète pour accompagner la croissance des PME et des ETI :
- Un outil de Cloud Computing clé en main, prêt à l’emploi ;
- Des processus rationalisés de bout en bout grâce à une application intelligente ;
- Une analyse en temps réel de toutes vos performances et indicateurs clés.
Cet ERP intègre gestion financière, logiciel de comptabilité, mais aussi outils d’analyse évolués pour exploiter tout le potentiel de votre entreprise et prendre les bonnes décisions quant à son développement. Il est particulièrement adapté aux organisations connaissant une forte croissance et désirant atteindre des objectifs plus ambitieux.
Conclusion : l’ERP Finance SAP au service de toutes les PME et ETI
Au-delà du simple outil de gestion comptabilité, l’ERP est un système d’information et d’analyse perfectionné, en évolution constante. SAP a tiré profit de sa longue expérience auprès des petites et moyennes entreprises pour concevoir les progiciels les plus pertinents. Ce sont désormais des partenaires incontournables de l’entreprise, accessibles à tous ses collaborateurs.
Vous hésitez encore sur le choix de votre ERP de gestion financière ? Les conseillers SAP sont à votre disposition pour vous présenter les produits les plus adaptés à votre cœur de métier.
The post Gestion financière : quel ERP choisir pour gérer votre PME/ETI ? appeared first on SAP France News.