Votre prochaine grande décision lorsque vous envisagez un nouveau système ERP ? La façon dont il sera déployé. Vous avez le choix entre plusieurs approches, notamment le déploiement traditionnel sur site, le déploiement dans le cloud ou une combinaison hybride des deux.
Vous voudrez tenir compte des différences financières et examiner les forces et les attraits de chaque stratégie de déploiement ERP, ainsi que les limitations ou les défis uniques. Il est essentiel d’examiner toutes les options et de choisir l’approche de déploiement qui répondra le mieux aux besoins de votre entreprise aujourd’hui – et dans un avenir prévisible.
Avant de vérifier les options de déploiement de votre ERP, voyez comment – et pourquoi – le cloud est devenu un environnement vital pour la réussite des entreprises dans l’économie numérique.
Pourquoi cette tendance d’un déploiement cloud ?
Nous observons tous avec un vif intérêt l’évolution de la technologie informatique à un rythme toujours plus rapide. Les premiers systèmes d’entreprise et les premiers systèmes ERP étaient hébergés sur de gros ordinateurs centraux et de milieu de gamme avec des terminaux pour la saisie des données par les utilisateurs – après avoir remplacé les cartes perforées et la saisie sur disque, bien sûr ! La technologie de pointe suivante était l’architecture client/serveur, dans laquelle les terminaux étaient remplacés par des PC (appelés aujourd’hui clients) qui pouvaient gérer une partie de la charge de travail. Cela a permis de réduire la quantité de données qui devaient faire l’objet d’allers-retours avec l’ordinateur serveur.
Aux alentours du millénaire, deux évolutions importantes ont changé le monde de l’informatique et de l’ERP : l’Internet et le cloud. Il n’était plus nécessaire d’acheter et de prendre en charge du matériel et des logiciels pour gérer votre entreprise. La totalité ou la majeure partie de la technologie pouvait désormais être « louée » ou externalisée dans le cadre d’une offre groupée comprenant toute la maintenance et une grande partie des opérations techniques. L’omniprésence d’Internet a fourni l’infrastructure de communication nécessaire pour rendre le cloud pratique et disponible partout dans le monde.
Mais les entreprises n’ont pas immédiatement migré leurs systèmes ERP vers un déploiement dans le cloud. Il a fallu un certain temps pour que la technologie et les applications arrivent à maturité et pour que les entreprises réalisent que l’ordinateur n’a pas besoin d’être sur place pour bénéficier d’un accès fiable et d’une sécurité pour les applications essentielles à l’entreprise. Une partie de cette évolution a impliqué que les développeurs apprennent à :
- Tirer pleinement parti du déploiement dans le cloud
- écrire ou réécrire des applications de manière appropriée
- Reconstruire leur infrastructure (technologie et ressources humaines) pour prendre en charge les systèmes dans le cloud.
Et, surtout, les systèmes ERP dans le cloud offrent désormais des technologies avancées telles que l’intelligence artificielle (IA) et l’apprentissage automatique pour améliorer la productivité et le service, des expériences utilisateur personnalisées pour favoriser l’adoption, ainsi que des fonctionnalités étendues et des analyses intégrées pour fournir une vue complète de l’entreprise, ce qui, au final, favorise l’innovation et la croissance de l’entreprise.
Le modèle tarifaire du SaaS
Dans le passé, la plupart des logiciels étaient installés dans les locaux de l’entreprise et la seule option de licence était l’achat d’une licence perpétuelle – l’application étant concédée pour un montant initial plus un contrat de maintenance annuel pour les mises à niveau et les corrections de bogues. Les licences de logiciels sont le plus souvent facturées par utilisateur. La maintenance annuelle est généralement facturée à 18 % ou 20 % du prix courant du logiciel. Cela signifie que la licence du logiciel est essentiellement « rachetée » tous les cinq ou six ans.
Avec l’ERP sur site, tout le matériel et le logiciel sont achetés ou loués et installés sur le(s) site(s) de l’entreprise. L’entreprise est responsable de la maintenance, de l’assistance et des éventuelles mises à niveau ou extensions du matériel, des systèmes et des logiciels d’application, ainsi que des locaux, de l’assurance, des ressources de basculement et du stockage de sauvegarde hors site.
Les systèmes ERP basés sur le cloud, en revanche, ne sont généralement pas installés sur site et sont pris en charge par un fournisseur dans le cadre d’une redevance mensuelle ou annuelle. Ils font l’objet d’une licence sur la base de ce que l’on appelle un logiciel en tant que service (SaaS). Les licences SaaS peuvent être facturées par utilisateur, par application ou par ensemble d’applications (tout l’ERP, par exemple), en fonction de la taille de votre entreprise ou d’autres variations.
Un aspect intéressant des licences de déploiement dans le cloud est leur évolutivité. Si la licence est accordée par « siège » d’utilisateur, vous pouvez ajouter ou réduire le nombre d’utilisateurs et payer un prix plus ou moins élevé en fonction du nombre de nouveaux utilisateurs. Si vos besoins en termes de volume de transactions, de capacité de stockage ou de puissance de calcul changent, le fournisseur est chargé de mettre à niveau ses installations pour tenir compte de ce changement, ce qui signifie que vous n’aurez pas à acheter et à installer plus de serveurs ou plus de stockage sur disque.
L’analogie la plus proche pourrait être la télévision par câble. Vous payez pour ce dont vous avez besoin, et ce prix comprend l’utilisation et l’exploitation de toutes les installations physiques, le personnel, la maintenance et toutes les autres dépenses liées au service de câble à votre emplacement. Si vous avez besoin de plus de chaînes et que vous en ajoutez, vous payez simplement ce que vous avez demandé et vous ne vous inquiétez pas de savoir comment ils parviennent à fournir les chaînes supplémentaires.
Cloud public vs. privé vs. hybride cloud vs. deux-tiers
Il existe quatre façons possibles de mettre en œuvre un véritable système ERP dans le cloud :
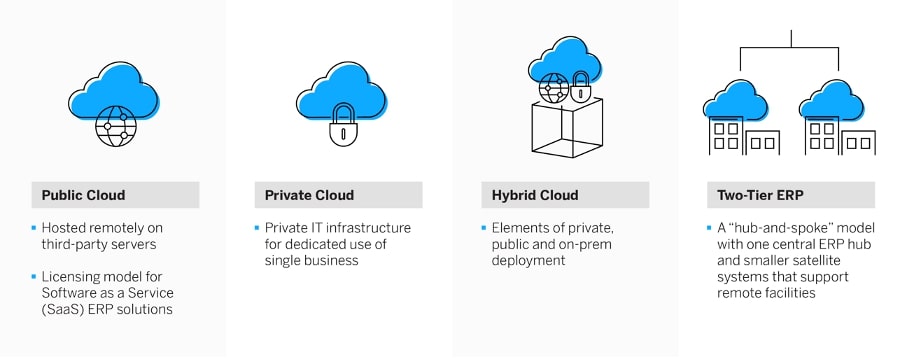
1. ERP sur le cloud public
Le cloud public est le principal modèle de licence pour les solutions ERP de type « software-as-a-service » (SaaS). Le fournisseur du système dispose de son propre centre de données – ou peut louer un espace sur un nuage public pour héberger ses applications et ses systèmes. Tout le matériel, les systèmes et les services d’assistance sont fournis par le biais du cloud public. La mise en œuvre est ainsi plus rapide et plus facile pour l’entreprise utilisatrice car, avec tous les éléments matériels et logiciels déjà en place, elle peut commencer directement par le transfert des données et la formation des utilisateurs.
Avec cette option de déploiement de l’ERP dans le cloud, votre fournisseur de logiciels s’occupera également de l’installation, de la maintenance et de l’assistance, y compris de toutes les mises à jour et mises à niveau logicielles telles que l’ajout de puissance de calcul ou de stockage. De plus, les systèmes, les applications et les ressources peuvent être « autoscalés », c’est-à-dire augmentés ou diminués automatiquement pour répondre à des besoins changeants. Il n’est donc plus nécessaire de payer pour des ressources informatiques qui peuvent rester inutilisées la plupart du temps, comme c’est le cas avec les systèmes ERP sur site.
L’ERP SaaS basé sur le cloud public a un coût initial faible ou nul (une « dépense d’investissement ») mais un coût mensuel un peu plus élevé (une « dépense d’exploitation »), par rapport à une installation sur site typique. Si l’on considère la période normale de coût du cycle de vie de cinq à sept ans, le coût total de possession (TCO) est similaire, voire inférieur, à celui d’une installation sur site et offre potentiellement un meilleur service, un meilleur support et une meilleure sécurité.
L’ERP en cloud public offre également le chemin le plus rapide vers l’innovation, ce qui le rend idéal pour les entreprises qui veulent poursuivre agressivement leur stratégie de transformation numérique. Cette option de déploiement permet aux entreprises de réimaginer, d’optimiser et d’adapter facilement leurs processus métier en fonction des besoins, et de tirer parti des meilleures pratiques standardisées que les fournisseurs d’ERP modernes devraient prendre en charge.
2. ERP en cloud privé
Bien qu’ils soient similaires à l’option du cloud public, le matériel, les logiciels système et l’assistance du cloud privé peuvent être détenus, gérés et exploités par l’entreprise, un tiers ou une combinaison des deux pour l’usage exclusif d’une seule organisation. Dans le cadre d’un déploiement dans le cloud privé, l’entreprise utilisatrice doit généralement payer la licence du logiciel ERP.
L’option de propriété tierce est populaire auprès des services informatiques qui souhaitent externaliser le matériel, la base de données et une grande partie des tâches de mise en réseau, ce qui leur permet de bénéficier de certains des avantages d’un cloud public. Cette option de déploiement est également privilégiée par les entreprises qui souhaitent passer au cloud par étapes, que ce soit rapidement ou progressivement, ou comme étape intermédiaire vers le cloud public. Cela est particulièrement vrai pour les grands fabricants mondiaux et les autres entreprises dont les systèmes sont complexes, fragmentés ou hautement personnalisés.
Le déploiement d’un cloud privé implique généralement un investissement initial plus important (dépenses d’investissement), mais le coût du cycle de vie peut se situer quelque part entre celui du cloud public et celui des systèmes sur site. Certains fournisseurs modifient ce calcul en proposant des packs de mise en œuvre groupés qui réduisent les coûts initiaux et incluent tous les outils et services, l’infrastructure et les exigences du réseau par le biais d’une tarification par abonnement. Les entreprises peuvent profiter d’un coût total de possession plus faible grâce à l’économie du cloud, d’une architecture moderne basée sur le cloud, ainsi que d’une fonctionnalité ERP complète qui inclut les modules complémentaires, les extensions et les améliorations des partenaires.
3. ERP en cloud hybride
Les éléments d’un déploiement ERP dans un cloud privé, un cloud public et sur site peuvent être combinés pour créer un cloud hybride, qui offre la flexibilité de choisir le déploiement optimal pour chaque application. L’ERP dans le cloud hybride peut être utilisé comme un tremplin vers le cloud public, ou pour répondre à des questions de réglementation sectorielle et à des exigences de sécurité particulières qui peuvent imposer le recours à des applications sur site dans certaines situations. D’autres restrictions ou préférences peuvent également rendre les applications sur site souhaitables pour certaines applications. La complexité d’une entreprise et de son environnement actuel, ainsi que le désir d’une vitesse de changement plus lente, sont des facteurs déterminants dans la décision de déployer un scénario hybride.
Une mise en œuvre hybride permet aux applications et aux données de passer d’une option à l’autre en fonction de l’évolution de la charge de travail. Elle offre les avantages du cloud pour la partie du système qui se trouve dans le cloud. Cependant, elle nécessite une plus grande implication de l’informatique locale pour prendre en charge les éléments sur site, ainsi que la coordination entre les deux – ou plus – environnements de système ERP.
4. ERP deux-tiers
Véritable variante de l’approche hybride mise en œuvre pour les mêmes raisons, le déploiement d’un ERP à deux niveaux – parfois appelé déploiement en étoile – fait appel à un système central et à des systèmes satellites plus petits qui prennent en charge les installations distantes. Imaginez que l’ERP de l’entreprise est le centre, et que les systèmes ERP individuels des usines, entrepôts ou bureaux des filiales renvoient tous leurs données au centre. Cette idée n’est pas nouvelle ; elle est apparue au cours de la phase de traitement distribué des années 1990, lorsque les entreprises ont choisi de mettre en œuvre des systèmes plus petits, plus simples et moins coûteux sur des sites distants, tout en conservant le système d’entreprise plus grand et plus performant au siège de la société. Tous les systèmes d’un réseau à deux niveaux, ou certains d’entre eux, peuvent être installés sur site ou dans le cloud, achetés ou sous licence SaaS.
Le coût global d’un déploiement ERP à deux niveaux – avec des systèmes moins coûteux aux nœuds au lieu du même système d’entreprise partout – permettra de réduire le coût de l’achat initial. Toutefois, l’intégration et le support peuvent entraîner un coût global continu plus élevé, car les interfaces doivent être construites et entretenues. Et, année après année, il faudra davantage de soutien informatique pour assurer la coordination avec les multiples fournisseurs, ainsi que pour gérer les calendriers de mise à niveau et les changements d’interface non coordonnés.
Que signifie l’expression « faux cloud » ?
Le faux cloud, également connu sous le nom de « cloud washing », fait référence à un système ERP existant porté vers le cloud et peut-être « enveloppé » d’un logiciel supplémentaire pour adapter le système à cet environnement. Mais ces applications ne sont pas écrites pour être déployées dans le cloud et ne peuvent donc pas vraiment bénéficier de ce que le cloud a à offrir. Il s’agit exactement des mêmes applications ERP héritées installées sur du matériel externalisé. Le « wrapper » peut présenter aux utilisateurs des écrans modernes de type Web, mais les informations saisies doivent être traduites en fonction des exigences de saisie du système existant et retransmises aux écrans enveloppés pour affichage – une approche peu efficace. Pour l’utilisateur, cela ressemble au nuage, mais il ne fonctionnera pas comme une application dans le cloud et ne sera pas en mesure de tirer parti de la connectivité dans le cloud, des fonctionnalités avancées ou des performances opérationnelles optimisées.
Les véritables fournisseurs d’ERP dans le cloud conçoivent leurs solutions de A à Z, spécifiquement pour le cloud. Les applications patrimoniales enveloppées dans le cloud n’ont pas été conçues pour le cloud et des problèmes de performance peuvent donc survenir. Les personnalisations et les intégrations peuvent également poser problème, et ces solutions doivent toujours être mises à jour et entretenues, souvent par les ressources informatiques de l’entreprise utilisatrice.
Étant donné que les applications patrimoniales portées sur le cloud sont essentiellement les mêmes que les applications sur site, la tarification est rarement basée sur les besoins d’utilisation, d’où un risque de sur-achat. En outre, le modèle SaaS n’est pas couramment appliqué, ce qui signifie que l’entreprise utilisatrice conserve en interne toute la responsabilité du support et des mises à jour.
Quand choisir un système ERP sur site plutôt que dans le cloud ?
De plus en plus d’entreprises passent à l’ERP dans le cloud, mais cette solution ne convient pas à toutes les entreprises. La principale raison de conserver une solution ERP sur site est le besoin de conformité, qu’il s’agisse des exigences des clients, du secteur ou des pouvoirs publics en matière de réglementation et de normes. Des exigences plus strictes nécessitent parfois une mise en œuvre sur site dans les secteurs plus réglementés.
Le manque de fiabilité du service Internet est cité par certaines entreprises comme une raison de ne pas passer au cloud. Pour les applications ERP critiques, il est crucial d’être opérationnel et disponible 99 % du temps. Cependant, avec les réseaux, serveurs et processus modernes, les temps d’arrêt ne sont généralement plus un problème et empêchent rarement le déploiement d’un ERP dans le cloud.
La gestion des données peut être une autre raison de conserver votre système ERP dans vos locaux. Dans le cas d’un déploiement dans le cloud, vous pouvez ou non être en mesure de déplacer facilement vos données, selon les politiques de votre fournisseur de services. Assurez-vous qu’il prend en charge les services dont vous avez besoin.
Une autre raison est la perte de contrôle (par exemple, sur la sécurité, les données ou les mises à niveau). Avec un ERP basé sur le cloud, votre entreprise se décharge de nombreuses responsabilités informatiques sur un tiers. Il est donc important de s’assurer que ce tiers est fiable et qu’il a fait ses preuves. Cependant, certaines entreprises choisissent encore de tout garder « en interne ».
Les déploiements d’ERP sur site présentent certains inconvénients, notamment la nécessité de procéder à des mises à niveau manuelles du système et l’absence de services intégrés d’installation, de maintenance et d’assistance. Heureusement, pour les entreprises qui ont besoin de ce type de mise en œuvre, certains fournisseurs proposent des services qui offrent certains des avantages des logiciels basés sur le cloud.
Astuces pour la sélection des processus
Choisissez d’abord le logiciel ERP par le biais d’un processus d’évaluation minutieux, puis examinez les options de déploiement en fonction des capacités de déploiement du logiciel, des besoins de votre entreprise et du retour sur investissement potentiel de l’ERP. Certains logiciels ERP ne sont disponibles qu’en mode cloud ou SaaS, tandis que d’autres fournisseurs proposent des solutions cloud, on-prem et hybrides. Les options de déploiement disponibles peuvent être un critère d’inclusion dans la liste restreinte, mais elles ne doivent pas être le seul déterminant du choix du système. .
- Évitez les applications ERP héritées du faux cloud pour les raisons mentionnées ci-dessus.
- Les entreprises à croissance rapide et celles qui prévoient des changements prochains dans le nombre d’utilisateurs (à la hausse ou à la baisse) devraient probablement se concentrer sur les vrais systèmes ERP dans le cloud pour leur évolutivité et leur tarification à l’usage.
- Assurez-vous que tous les membres de l’équipe de sélection comprennent les caractéristiques et les avantages de l’ERP dans le cloud public, privé ou hybride.
Synthèse
Au départ, les entreprises peuvent être attirées par le déploiement d’un ERP dans le cloud pour des raisons financières (peu ou pas de dépenses d’investissement et coût total du cycle de vie réduit), mais elles sont enthousiasmées par les avantages techniques et opérationnels qu’offre le cloud, notamment
- Un ERP qui est toujours à jour avec les dernières mises à niveau (sans coût ni effort supplémentaire).
- Une évolutivité quasi illimitée
- Paiement uniquement pour ce dont vous avez besoin/ce que vous utilisez
- une mise en œuvre plus rapide
- Une meilleure sécurité et de meilleurs contrôles d’accès, et plus encore
Le déploiement intégral dans le cloud n’est pas la seule option. Il est parfois plus judicieux de conserver certaines applications sur place et d’utiliser le cloud pour le reste. Heureusement, de nombreux choix de configuration et de déploiement sont disponibles afin que vous puissiez choisir le déploiement qui vous convient le mieux sur le plan financier et opérationnel.
Le passage à un nouveau système ERP est un changement important pour les utilisateurs du système, le service informatique et l’ensemble de l’entreprise. Il est judicieux d’explorer toutes les options et de choisir la configuration du système qui offre les meilleures performances au meilleur coût. Ensuite, prévoyez comment vos ressources internes et votre structure devront changer pour tirer le meilleur parti de votre investissement, quels que soient la configuration et le déploiement.
Publié pour la première fois en anglais sur insights.sap.com
The post Planifier le déploiement de votre ERP dans le cloud appeared first on SAP France News.
Source de l’article sur sap.com