La taxonomie des anti-modèles Scrum est une classification des pratiques qui sont contraires à l’approche Scrum. Découvrons comment ces pratiques peuvent nuire à l’efficacité de votre équipe.
TL; DR : Taxonomie des anti-patterns Scrum
TL; DR: Taxonomie des anti-patterns Scrum
Alors que le processus d’édition du Guide des anti-patterns Scrum est sur le point de se terminer, il est temps de passer à l’étape suivante. Le tout nouveau Guide des anti-patterns Scrum offre plus de 180 anti-patterns organisés par rôles, événements, artefacts et engagements. Cependant, le guide ne crée pas une taxonomie d’anti-patterns Scrum de niveau métal ou abstrait. Par conséquent, le guide ne fournit pas de stratégie globale pour contrer ou éviter les anti-patterns Scrum à un niveau personnel, culturel, structurel ou organisationnel. La question est de savoir s’il est possible de créer une telle taxonomie.
Lisez la suite et en apprenez plus sur les premières étapes de la finalisation du grand tableau des anti-patterns Scrum.
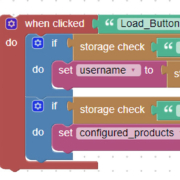
La taxonomie des anti-patterns Scrum est un outil précieux pour les développeurs et les équipes qui cherchent à améliorer leur processus de développement et à éviter les erreurs courantes. Une taxonomie des anti-patterns Scrum peut être utilisée pour identifier les problèmes courants et les solutions possibles. Elle peut également être utilisée pour comprendre comment les différents aspects du développement peuvent interagir et affecter le processus global. Une taxonomie des anti-patterns Scrum peut également aider à identifier les bonnes pratiques et à définir des objectifs pour améliorer le processus de développement.
Une taxonomie des anti-patterns Scrum peut être divisée en quatre catégories principales : le code, le processus, l’organisation et la culture. Chaque catégorie peut être divisée en sous-catégories plus spécifiques. Par exemple, la catégorie « code » peut être divisée en sous-catégories telles que le codage, la documentation, la qualité et la sécurité. La catégorie « processus » peut être divisée en sous-catégories telles que la planification, l’estimation, le suivi et la gestion des changements. La catégorie « organisation » peut être divisée en sous-catégories telles que la structure organisationnelle, la communication et la collaboration. Enfin, la catégorie « culture » peut être divisée en sous-catégories telles que l’apprentissage, l’innovation et l’amélioration continue.
Une fois que les différentes catégories et sous-catégories sont identifiées, il est possible de créer une taxonomie des anti-patterns Scrum. Cette taxonomie peut être utilisée pour identifier les problèmes courants et les solutions possibles. Elle peut également être utilisée pour comprendre comment les différents aspects du développement peuvent interagir et affecter le processus global. Enfin, elle peut aider à identifier les bonnes pratiques et à définir des objectifs pour améliorer le processus de développement.
La taxonomie des anti-patterns Scrum est un outil précieux pour les développeurs et les équipes qui cherchent à améliorer leur processus de développement et à éviter les erreurs courantes. En créant une taxonomie des anti-patterns Scrum, il est possible d’identifier les