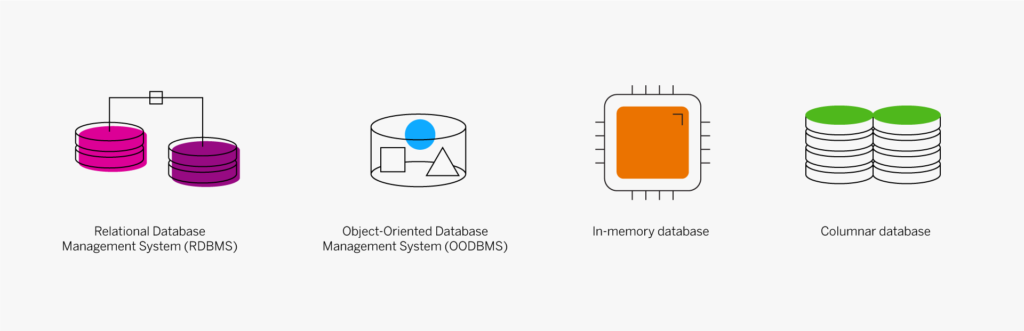
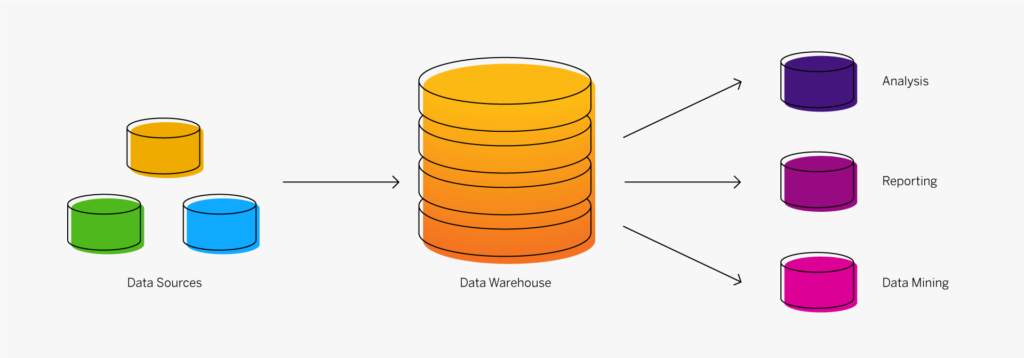
Un data warehouse (entrepôt de données) est un système de stockage numérique qui connecte et harmonise de grandes quantités de données provenant de nombreuses sources différentes. Il a pour but d’alimenter la Business Intelligence (BI), le reporting et l’analyse, ainsi que soutenir la conformité aux exigences réglementaires afin que les entreprises puissent exploiter leurs données et prendre des décisions intelligentes fondées sur les données. Les data warehouse stockent les données actuelles et historiques dans un seul et même endroit et constituent ainsi une source unique de vérité pour une organisation.
Les données sont envoyées vers un data warehouse à partir de systèmes opérationnels (tels qu’un système ERP ou CRM), de bases de données et de sources externes comme les systèmes partenaires, les appareils IoT, les applications météo ou les réseaux sociaux, généralement de manière régulière. L’émergence du cloud computing a changé la donne. Ces dernières années, le stockage des données a été déplacé de l’infrastructure sur site traditionnelle vers de multiples emplacements, y compris sur site, dans le Cloud privé et dans le Cloud public.
Les data warehouse modernes sont conçus pour gérer à la fois les données structurées et les données non structurées, comme les vidéos, les fichiers image et les données de capteurs. Certains utilisent les outils analytiques intégrés et la technologie de base de données in-memory (qui conserve l’ensemble de données dans la mémoire de l’ordinateur plutôt que dans l’espace disque) pour fournir un accès en temps réel à des données fiables et favoriser une prise de décision en toute confiance. Sans entreposage de données, il est très difficile de combiner des données provenant de sources hétérogènes, de s’assurer qu’elles sont au bon format pour les analyses et d’obtenir une vue des données sur le court terme et sur le long terme.
Avantages de l’entreposage de données
Un data warehouse bien conçu constitue la base de tout programme de BI ou d’analyse réussi. Son principal objectif est d’alimenter les rapports, les tableaux de bord et les outils analytiques devenus indispensables aux entreprises d’aujourd’hui. Un entrepôt de données fournit les informations dont vous avez besoin pour prendre des décisions basées sur les données et vous aide à faire les bons choix, que ce soit pour le développement de nouveaux produits ou la gestion des niveaux de stock. Un data warehouse présente de nombreux avantages. En voici quelques-uns :
- Un meilleur reporting analytique : grâce à l’entreposage de données, les décideurs ont accès à des données provenant de plusieurs sources et n’ont plus besoin de prendre des décisions basées sur des informations incomplètes.
- Des requêtes plus rapides : les data warehouse sont spécialement conçus pour permettre l’extraction et l’analyse rapides des données. Avec un entrepôt de données, vous pouvez très rapidement demander de grandes quantités de données consolidées avec peu ou pas d’aide du service informatique.
- Une amélioration de la qualité des données : avant de charger les données dans l’entrepôt de données le système met en place des nettoyages de données afin de garantir que les données sont converties dans un seul et même format dans le but de faciliter les analyses (et les décisions), qui reposent alors sur des données précises et de haute qualité.
- Une visibilité sur les données historiques : en stockant de nombreuses données historiques, un data warehouse permet aux décideurs d’analyser les tendances et les défis passés, de faire des prévisions et d’améliorer l’organisation au quotidien.
Que peut stocker un data warehouse ?
Lorsque les data warehouse sont devenus populaires à la fin des années 1980, ils étaient conçus pour stocker des informations sur les personnes, les produits et les transactions. Ces données, appelées données structurées, étaient bien organisées et mises en forme pour en favoriser l’accès. Cependant, les entreprises ont rapidement voulu stocker, récupérer et analyser des données non structurées, comme des documents, des images, des vidéos, des e-mails, des publications sur les réseaux sociaux et des données brutes issues de capteurs.
Un entrepôt de données moderne peut contenir des données structurées et des données non structurées. En fusionnant ces types de données et en éliminant les silos qui les séparent, les entreprises peuvent obtenir une vue complète et globale sur les informations les plus précieuses.
Termes clés
Il est essentiel de bien comprendre un certain nombre de termes en lien avec les data warehouse. Les plus importants ont été définis ci-dessous. Découvrez d’autres termes et notre FAQ dans notre glossaire.
Data warehouse et base de données
Les bases de données et les data warehouse sont tous deux des systèmes de stockage de données, mais diffèrent de par leurs objectifs. Une base de données stocke généralement des données relatives à un domaine d’activité particulier. Un entrepôt de données stocke les données actuelles et historiques de l’ensemble de l’entreprise et alimente la BI et les outils analytiques. Les data warehouse utilisent un serveur de base de données pour extraire les données présentes dans les bases de données d’une organisation et disposent de fonctionnalités supplémentaires pour la modélisation des données, la gestion du cycle de vie des données, l’intégration des sources de données, etc.
Data warehouse et lac de données
Les data warehouse et les lacs de données sont utilisés pour stocker le Big Data, mais sont des systèmes de stockage très différents. Un data warehouse stocke des données qui ont été formatées dans un but spécifique, tandis qu’un lac de données stocke les données dans leur état brut, non traité, dont l’objectif n’a pas encore été défini. Les entrepôts de données et les lacs de données se complètent souvent. Par exemple, lorsque des données brutes stockées dans un lac s’avèrent utiles pour répondre à une question, elles peuvent être extraites, nettoyées, transformées et utilisées dans un data warehouse à des fins d’analyse. Le volume de données, les performances de la base de données et les coûts du stockage jouent un rôle important dans le choix de la solution de stockage adaptée.
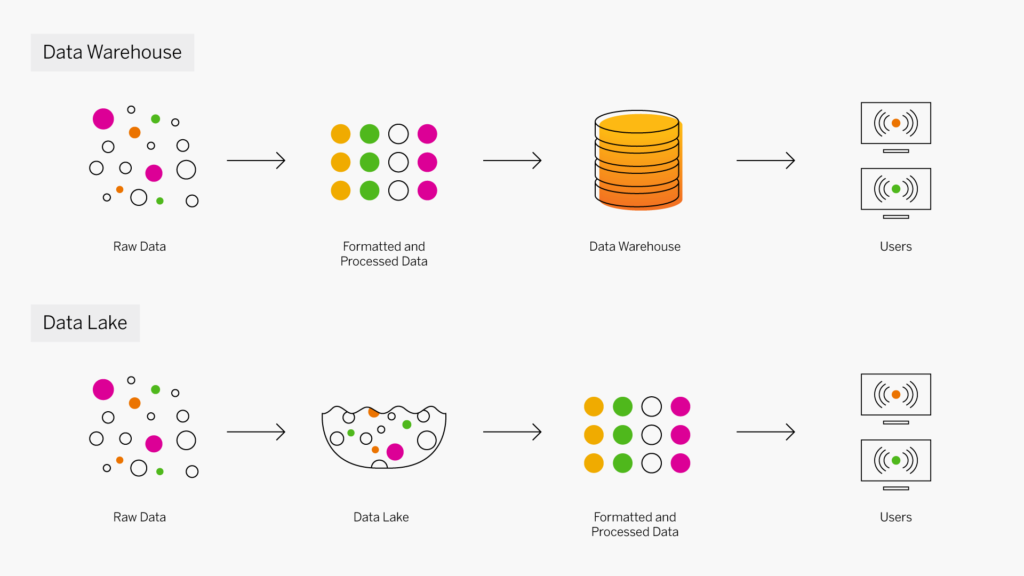
Data warehouse et datamart
Un datamart est une sous-section d’un data warehouse, partitionné spécifiquement pour un service ou un secteur d’activité, comme les ventes, le marketing ou la finance. Certains datamarts sont également créés à des fins opérationnelles autonomes. Alors qu’un data warehouse sert de magasin de données central pour l’ensemble de l’entreprise, un datamart utilise des données pertinentes à un groupe d’utilisateurs désigné. Ces utilisateurs peuvent alors accéder plus facilement aux données, accélérer leurs analyses et contrôler leurs propres données. Plusieurs datamarts sont souvent déployés dans un data warehouse.
Quels sont les composants clés d’un data warehouse ?
Un data warehouse classique comporte quatre composants principaux : une base de données centrale, des outils ETL (extraction, transformation, chargement), des métadonnées et des outils d’accès. Tous ces composants sont conçus pour être rapides afin de vous assurer d’obtenir rapidement des résultats et vous permettre d’analyser les données à la volée.
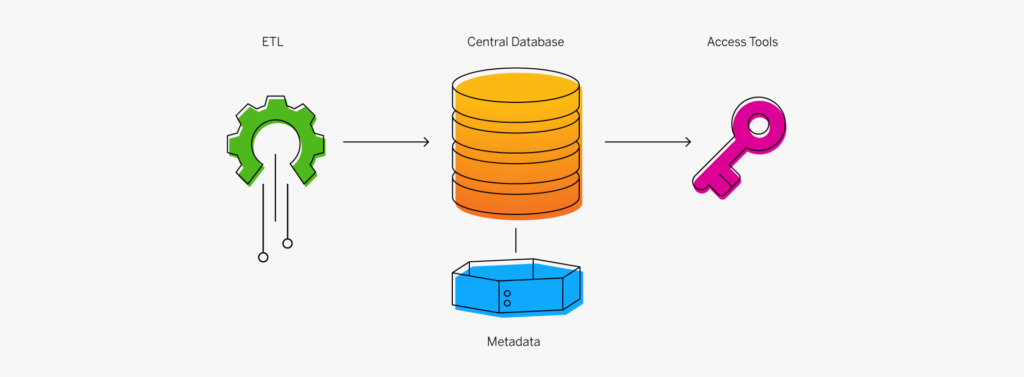
- Base de données centrale : une base de données sert de fondement à votre data warehouse. Depuis le départ, on utilisait essentiellement des bases de données relationnelles standard exécutées sur site ou dans le Cloud. Mais en raison du Big Data, du besoin d’une véritable performance en temps réel et d’une réduction drastique des coûts de la RAM, les bases de données in-memory sont en train de monter en puissance.
- Intégration des données : les données sont extraites des systèmes source et modifiées pour aligner les informations afin qu’elles puissent être rapidement utilisées à des fins analytiques à l’aide de différentes approches d’intégration des données telles que l’ETL (extraction, transformation, chargement) et les services de réplication de données en temps réel, de traitement en masse, de transformation des données et de qualité et d’enrichissement des données.
- Métadonnées : les métadonnées sont des données relatives à vos données. Elles indiquent la source, l’utilisation, les valeurs et d’autres fonctionnalités des ensembles de données présents dans votre data warehouse. Il existe des métadonnées de gestion, qui ajoutent du contexte à vos données, et des métadonnées techniques, qui décrivent comment accéder aux données, définissent leur emplacement ainsi que leur structure.
- Outils d’accès du data warehouse : les outils d’accès permettent aux utilisateurs d’interagir avec les données de votre data warehouse. Exemples d’outils d’accès : outils de requête et de reporting, outils de développement d’applications, outils d’exploration de données et outils OLAP.
Architecture de data warehouse
Auparavant, les data warehouse fonctionnaient par couches, lesquelles correspondaient au flux des données de gestion.
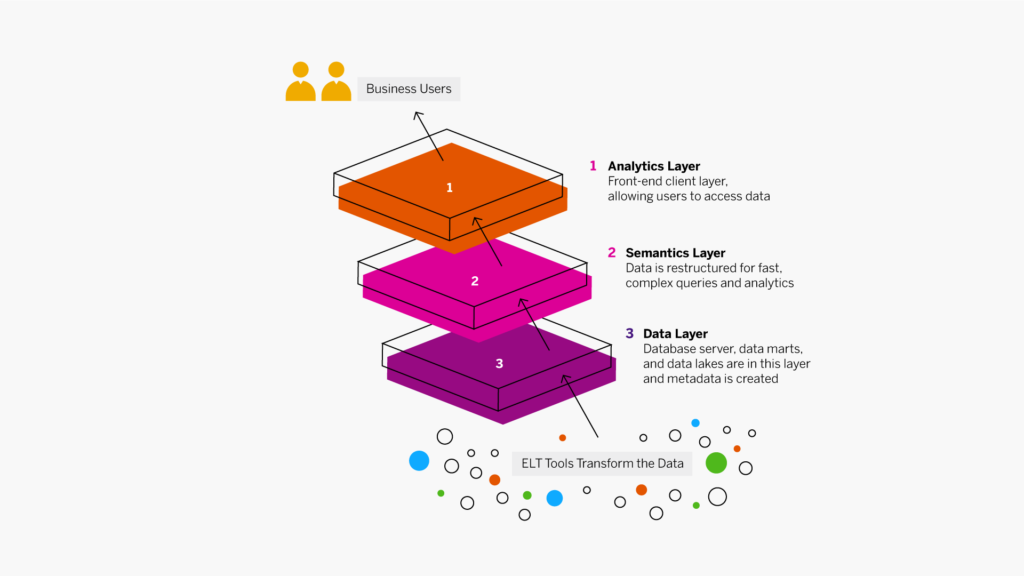
|
Couche de données |
Les données sont extraites de vos sources, puis transformées et chargées dans le niveau inférieur à l’aide des outils ETL. Le niveau inférieur comprend votre serveur de base de données, les datamarts et les lacs de données. Les métadonnées sont créées à ce niveau et les outils d’intégration des données, tels que la virtualisation des données, sont utilisés pour combiner et agréger les données en toute transparence. |
|
Couche sémantique |
Au niveau intermédiaire, les serveurs OLAP (Online Analytical Processing) et OLTP (Online Transaction Processing) restructurent les données pour favoriser des requêtes et des analyses rapides et complexes. |
|
Couche analytique |
Le niveau supérieur est la couche du client frontend. Il contient les outils d’accès du data warehouse qui permettent aux utilisateurs d’interagir avec les données, de créer des tableaux de bord et des rapports, de suivre les KPI, d’explorer et d’analyser les données, de créer des applications, etc. Ce niveau inclut souvent un workbench ou une zone de test pour l’exploration des données et le développement de nouveaux modèles de données. |
Un data warehouse standard comprend les trois couches définies ci-dessus. Aujourd’hui, les entrepôts de données modernes combinent OLTP et OLAP dans un seul système.
Les data warehouse, conçus pour faciliter la prise de décision, ont été essentiellement créés et gérés par les équipes informatiques. Néanmoins, ces dernières années, ils ont évolué pour renforcer l’autonomie des utilisateurs fonctionnels, réduisant ainsi leur dépendance aux équipes informatiques pour accéder aux données et obtenir des informations exploitables. Parmi les fonctionnalités clés d’entreposage de données qui ont permis de renforcer l’autonomie des utilisateurs fonctionnels, on retrouve les suivantes :
- La couche sémantique ou de gestion fournit des expressions en langage naturel et permet à tout le monde de comprendre instantanément les données, de définir des relations entre les éléments dans le modèle de données et d’enrichir les zones de données avec de nouvelles informations.
- Les espaces de travail virtuels permettent aux équipes de regrouper les connexions et modèles de données dans un lieu sécurisé et géré, afin de mieux collaborer au sein d’un espace commun, avec un ensemble de données commun.
- Le Cloud a encore amélioré la prise de décision en permettant aux employés de disposer d’un large éventail d’outils et de fonctionnalités pour effectuer facilement des tâches d’analyse des données. Ils peuvent connecter de nouvelles applications et de nouvelles sources de données sans avoir besoin de faire appel aux équipes informatiques.

Kate Wright, responsable de la Business Intelligence augmentée chez SAP, évoque la valeur d’un data warehouse Cloud moderne.
Les 7 principaux avantages d’un data warehouse Cloud
Les data warehouse Cloud gagnent en popularité, à juste titre. Ces entrepôts modernes offrent plusieurs avantages par rapport aux versions sur site traditionnelles. Voici les sept principaux avantages d’un data warehouse Cloud :
- Déploiement rapide : grâce à l’entreposage de données Cloud, vous pouvez acquérir une puissance de calcul et un stockage de données presque illimités en quelques clics seulement, et créer votre propre data warehouse, datamarts et systèmes de test en quelques minutes.
- Faible coût total de possession (TCO) : les modèles de tarification du data warehouse en tant que service (DWaaS) sont établis de sorte que vous payez uniquement les ressources dont vous avez besoin, lorsque vous en avez besoin. Vous n’avez pas besoin de prévoir vos besoins à long terme ou de payer pour d’autres traitements tout au long de l’année. Vous pouvez également éviter les coûts initiaux tels que le matériel coûteux, les salles de serveurs et le personnel de maintenance. Séparer les coûts du stockage des coûts informatiques vous permet également de réduire les dépenses.
- Élasticité : un data warehouse Cloud vous permet d’ajuster vos capacités à la hausse ou à la baisse selon vos besoins. Le Cloud offre un environnement virtualisé et hautement distribué capable de gérer d’immenses volumes de données qui peuvent diminuer ou augmenter.
- Sécurité et restauration après sinistre : dans de nombreux cas, les data warehouse Cloud apportent une sécurité des données et un chiffrage plus forts que les entrepôts sur site. Les données sont également automatiquement dupliquées et sauvegardées, ce qui vous permet de minimiser le risque de perte de données.
- Technologies en temps réel : les data warehouse Cloud basés sur la technologie de base de données in-memory présentent des vitesses de traitement des données extrêmement rapides, offrant ainsi des données en temps réel et une connaissance instantanée de la situation.
- Nouvelles technologies : les data warehouse Cloud vous permettent d’intégrer facilement de nouvelles technologies telles que l’apprentissage automatique, qui peuvent fournir une expérience guidée aux utilisateurs fonctionnels et une aide décisionnelle sous la forme de suggestions de questions à poser, par exemple.
- Plus grande autonomie des utilisateurs fonctionnels : les data warehouse Cloud offrent aux employés, de manière globale et uniforme, une vue unique sur les données issues de nombreuses sources et un vaste ensemble d’outils et de fonctionnalités pour effectuer facilement des tâches d’analyse des données. Ils peuvent connecter de nouvelles applications et de nouvelles sources de données sans avoir besoin de faire appel aux équipes informatiques.
Meilleures pratiques concernant l’entreposage des données
Pour atteindre vos objectifs et économiser du temps et de l’argent, il est recommandé de suivre certaines étapes éprouvées lors de la création d’un data warehouse ou l’ajout de nouvelles applications à un entrepôt existant. Certaines sont axées sur votre activité tandis que d’autres s’inscrivent dans le cadre de votre programme informatique global. Vous pouvez commencer avec la liste de meilleures pratiques ci-dessous, mais vous en découvrirez d’autres au fil de vos collaborations avec vos partenaires technologiques et de services.
|
Meilleures pratiques métier |
Meilleures pratiques informatiques |
|
Définir les informations dont vous avez besoin. Une fois que vous aurez cerné vos besoins initiaux, vous serez en mesure de trouver les sources de données qui vous aideront à les combler. La plupart du temps, les groupes commerciaux, les clients et les fournisseurs auront des recommandations à vous faire. |
Surveiller la performance et la sécurité. Les informations de votre data warehouse sont certes précieuses, mais elles doivent quand même être facilement accessibles pour apporter de la valeur à l’entreprise. Surveillez attentivement l’utilisation du système pour vous assurer que les niveaux de performance sont élevés. |
|
Documenter l’emplacement, la structure et la qualité de vos données actuelles. Vous pouvez ensuite identifier les lacunes en matière de données et les règles de gestion pour transformer les données afin de répondre aux exigences de votre entrepôt. |
Gérer les normes de qualité des données, les métadonnées, la structure et la gouvernance. De nouvelles sources de données précieuses sont régulièrement disponibles, mais nécessitent une gestion cohérente au sein d’un data warehouse. Suivez les procédures de nettoyage des données, de définition des métadonnées et de respect des normes de gouvernance. |
|
Former une équipe. Cette équipe doit comprendre les dirigeants, les responsables et le personnel qui utiliseront et fourniront les informations. Par exemple, identifiez le reporting standard et les KPI dont ils ont besoin pour effectuer leurs tâches. |
Fournir une architecture agile. Plus vos unités d’affaires et d’entreprise utiliseront les données, plus vos besoins en matière de datamarts et d’entrepôts augmenteront. Une plate-forme flexible s’avérera bien plus utile qu’un produit limité et restrictif. |
|
Hiérarchiser vos applications de data warehouse. Sélectionnez un ou deux projets pilotes présentant des exigences raisonnables et une bonne valeur commerciale. |
Automatiser les processus tels que la maintenance. Outre la valeur ajoutée apportée à la Business Intelligence, l’apprentissage automatique peut automatiser les fonctions de gestion technique du data warehouse pour maintenir la vitesse et réduire les coûts d’exploitation. |
|
Choisir un partenaire technologique compétent pour l’entrepôt de données. Ce dernier doit offrir les services d’implémentation et l’expérience dont vous avez besoin pour la réalisation de vos projets. Assurez-vous qu’il puisse répondre à vos besoins en déploiement, y compris les services Cloud et les options sur site. |
Utiliser le Cloud de manière stratégique. Les unités d’affaires et les services ont des besoins en déploiement différents. Utilisez des systèmes sur site si nécessaire et misez sur des data warehouse Cloud pour bénéficier d’une évolutivité, d’une réduction des coûts et d’un accès sur téléphone et tablette. |
|
Développer un bon plan de projet. Travaillez avec votre équipe sur un plan et un calendrier réalistes qui rendent possible les communications et le reporting de statut. |
En résumé
Les data warehouse modernes, et, de plus en plus, les data warehouse Cloud, constitueront un élément clé de toute initiative de transformation numérique pour les entreprises mères et leurs unités d’affaires. Les data warehouse exploitent les systèmes de gestion actuels, en particulier lorsque vous combinez des données issues de plusieurs systèmes internes avec de nouvelles informations importantes provenant d’organisations externes.
Les tableaux de bord, les indicateurs de performance clés, les alertes et le reporting répondent aux exigences des cadres dirigeants, de la direction et du personnel, ainsi qu’aux besoins des clients et des fournisseurs importants. Les data warehouse fournissent également des outils d’exploration et d’analyse de données rapides et complexes, et n’ont pas d’impact sur les performances des autres systèmes de gestion.
Découvrez la solution SAP Data Warehouse Cloud
Unifiez vos données et analyses pour prendre des décisions avisées et obtenir la flexibilité nécessaire pour un contrôle efficace des coûts, notamment grâce à un paiement selon l’utilisation.
Publié en anglais sur insights.sap.com
The post Qu’est-ce qu’un Data Warehouse ? appeared first on SAP France News.