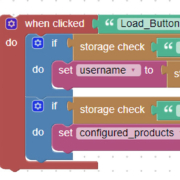
La programmation efficace et l’observabilité Java sont des outils essentiels pour développer des applications modernes. Découvrez comment les mettre en pratique!
Les erreurs courantes que j’ai vues répétées au fil des ans lors de la mise en œuvre de initiatives d’observabilité ne sont pas rares. Cependant, la plus critique et fondamentale de ces erreurs organisationnelles est l’irrésistible infatuation avec la technologie et les outils eux-mêmes.
The answer is simple: observability is not about the tools, it’s about the architecture. It’s about the ability to instrument your code and make it observable, and to have the right data available at the right time. It’s about having the right data and the right tools to make sense of it. It’s about understanding what data is important and what data is not. It’s about understanding the context of the data and how it relates to other data. It’s about understanding how to use the data to make better decisions.
Il y a beaucoup d’erreurs courantes que j’ai vues répétées au fil des ans lors de la mise en œuvre de initiatives d’observabilité. Cependant, le plus critique et le plus fondamental de ces erreurs organisationnelles est l’irrésistible fascination pour la technologie et les outils eux-mêmes.
Cela ne devrait pas être une surprise. De nombreux projets «ajoutons la plateforme d’observabilité X» démarrent avec beaucoup de faste mais aussi un sens de direction très flou et des critères de réussite extrêmement confus. La vision de ce que l’observabilité efficace peut faire pour aider réellement les développeurs à travailler mieux est suspectée d’être absente des prêches de nombreux fournisseurs commerciaux et oracles. Demandez-vous : à quelle fréquence vous trouvez-vous en train de quitter le code dans l’IDE pour voir ce que vous pouvez apprendre de ses données d’exécution?
La réponse est simple : l’observabilité ne concerne pas les outils, mais l’architecture. Il s’agit de la capacité d’instrumenter votre code et de le rendre observable, et d’avoir les bonnes données disponibles au bon moment. Il s’agit d’avoir les bonnes données et les bons outils pour en tirer des conclusions. Il s’agit de comprendre quelles données sont importantes et quelles données ne le sont pas. Il s’agit de comprendre le contexte des données et comment elles se rapportent à d’autres données. Il s’agit de comprendre comment utiliser les données pour prendre de meilleures décisions.
Lorsque vous concevez une architecture d’observabilité, vous devez prendre en compte tous ces aspects. Vous devez comprendre comment les données sont collectées, comment elles sont stockées, comment elles sont analysées et comment elles sont utilisées pour prendre des décisions. Vous devez également comprendre comment les outils peuvent vous aider à atteindre ces objectifs. Une architecture d’observabilité réussie doit être conçue pour fournir une vue complète des performances et des problèmes logiciels, ainsi que des informations sur la façon dont le code est exécuté.
Une fois que vous avez une architecture solide en place, vous pouvez alors commencer à choisir les outils appropriés pour collecter, stocker et analyser les données. Vous pouvez également choisir des outils pour vous aider à prendre des décisions informées sur la façon dont votre code est exécuté. Enfin, une fois que vous avez mis en place une architecture solide et choisi les bons outils, vous pouvez commencer à tirer parti des avantages de l’observabilité.