Le transfert de données depuis SQL Server vers Excel est un processus important pour les entreprises qui souhaitent faciliter l’analyse et le partage des informations.
Dans cet article, je partagerai des informations sur la façon de transférer des données de n’importe quelle table de notre base de données vers un fichier Excel personnalisé à l’aide de l’outil SSIS fourni par les développeurs MSSQL.
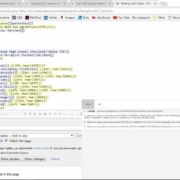
Once the installation is complete, we can open Visual Studio and create a new project. We will select the Integration Services Project type, which will allow us to create a package that will contain our data transfer process. After that, we can add a Data Flow Task to our package. This task will be responsible for transferring data from any table in our database to the custom-designed Excel file.
In order to do this, we need to configure the Data Flow Task. We will start by adding an OLE DB Source component to our Data Flow Task. This component will be used to connect to our database and retrieve the data from the table we want to transfer. We then need to configure the Excel Destination component, which will be used to write the data into the custom-designed Excel file.
Finally, we can configure the Data Flow Task to run in debug mode. This will allow us to test the data transfer process and make sure that it is working correctly. Once we are satisfied with the results, we can deploy the package to our production environment and start using it for our data transfer needs.
Dans cet article, je partagerai des informations sur la façon de transférer des données à partir de n’importe quelle table de notre base de données vers un fichier Excel personnalisé à l’aide de l’outil SSIS fourni par les développeurs MSSQL.
Tout d’abord, pour permettre notre développement via Visual Studio, nous devons installer Microsoft SQL Server Data Tools sur notre ordinateur.
Une fois l’installation terminée, nous pouvons ouvrir Visual Studio et créer un nouveau projet. Nous sélectionnerons le type de projet Integration Services, qui nous permettra de créer un package qui contiendra notre processus de transfert de données. Après cela, nous pouvons ajouter une tâche de flux de données à notre package. Cette tâche sera responsable du transfert des données à partir de n’importe quelle table de notre base de données vers le fichier Excel personnalisé.
Pour ce faire, nous devons configurer la tâche de flux de données. Nous commencerons par ajouter un composant Source OLE DB à notre tâche de flux de données. Ce composant sera utilisé pour se connecter à notre base de données et récupérer les données de la table que nous voulons transférer. Nous devons ensuite configurer le composant Destination Excel, qui sera utilisé pour écrire les données dans le fichier Excel personnalisé.
Enfin, nous pouvons configurer la tâche de flux de données pour qu’elle s’exécute en mode débogage. Cela nous permettra de tester le processus de transfert de données et de nous assurer qu’il fonctionne correctement. Une fois que nous sommes satisfaits des résultats, nous pouvons déployer le package dans notre environnement de production et commencer à l’utiliser pour nos besoins de transfert de données.
Pour vérifier que le transfert des données se déroule correctement, nous pouvons utiliser l’outil SSIS pour exécuter des tests unitaires sur le package. Ces tests unitaires vérifieront que les données sont transférées correctement et que le fichier Excel personnalisé est correctement mis à jour avec les données provenant de la base de données. Une fois que les tests unitaires sont terminés
Source de l’article sur DZONE