Les gestionnaires de produits doivent adopter des stratégies de gestion de la vie des produits (LLM) pour garantir le succès à long terme de leurs produits.
Embarquer dans l’excitante aventure de faire passer un produit de l’idée à sa mise sur le marché nécessite une planification et un storytelling minutieux. Les responsables produits jouent un rôle crucial dans la définition et la gestion du succès d’un produit. De l’idée à sa mise sur le marché, les responsables produits doivent naviguer à travers divers défis et prendre des décisions stratégiques. En tant que responsable produit, créer des récits et des stratégies convaincants est essentiel au succès. Alors que le LLM bouleverse le marché, les PM peuvent utiliser les LLM pour construire des stratégies efficaces à chaque étape du cycle de vie du produit afin d’améliorer leur productivité.
L’architecture d’un produit est un voyage passionnant qui commence par une idée et se termine par son lancement sur le marché. Les chefs de produit jouent un rôle crucial dans la définition et la réussite d’un produit. De la conception de l’idée à son lancement sur le marché, les chefs de produit doivent relever de nombreux défis et prendre des décisions stratégiques. En tant que chef de produit, il est essentiel de créer des récits et des stratégies convaincants pour réussir. Avec l’arrivée des modèles d’apprentissage automatique, les chefs de produit peuvent utiliser ces outils pour construire des stratégies efficaces à chaque étape du cycle de vie du produit et améliorer leur productivité.
Cet article vise à identifier le cycle de vie d’une idée à son lancement sur le marché et à montrer comment nous pouvons utiliser l’ingénierie prompte pour interroger un modèle d’apprentissage automatique et augmenter la productivité en tant que chef de produit.
L’architecture d’un produit est un processus complexe qui nécessite une planification et une gestion minutieuses. Les chefs de produit doivent être en mesure de comprendre les différentes phases du cycle de vie du produit et de prendre des décisions stratégiques à chaque étape. La première étape consiste à développer une idée et à la transformer en un produit viable. Une fois que le produit a été conçu, les chefs de produit doivent le tester et le lancer sur le marché. La dernière étape consiste à surveiller les performances du produit et à apporter des modifications si nécessaire.
Les modèles d’apprentissage automatique peuvent être utilisés pour améliorer le processus d’architecture du produit. Les chefs de produit peuvent utiliser ces modèles pour analyser les données du marché et prendre des décisions plus éclairées. Les modèles peuvent également être utilisés pour tester le produit avant son lancement et identifier les points forts et les points faibles. Enfin, les modèles peuvent être utilisés pour surveiller les performances du produit et apporter des modifications si nécessaire.
En conclusion, l’architecture d’un produit est un processus complexe qui nécessite une planification et une gestion minutieuses. Les chefs de produit peuvent utiliser les modèles d’apprentissage automatique pour améliorer le processus d’architecture du produit et augmenter leur productivité. Les modèles peuvent être utilisés pour analyser les données du marché, tester le produit avant son lancement, surveiller les performances du produit et apporter des modifications si nécessaire.










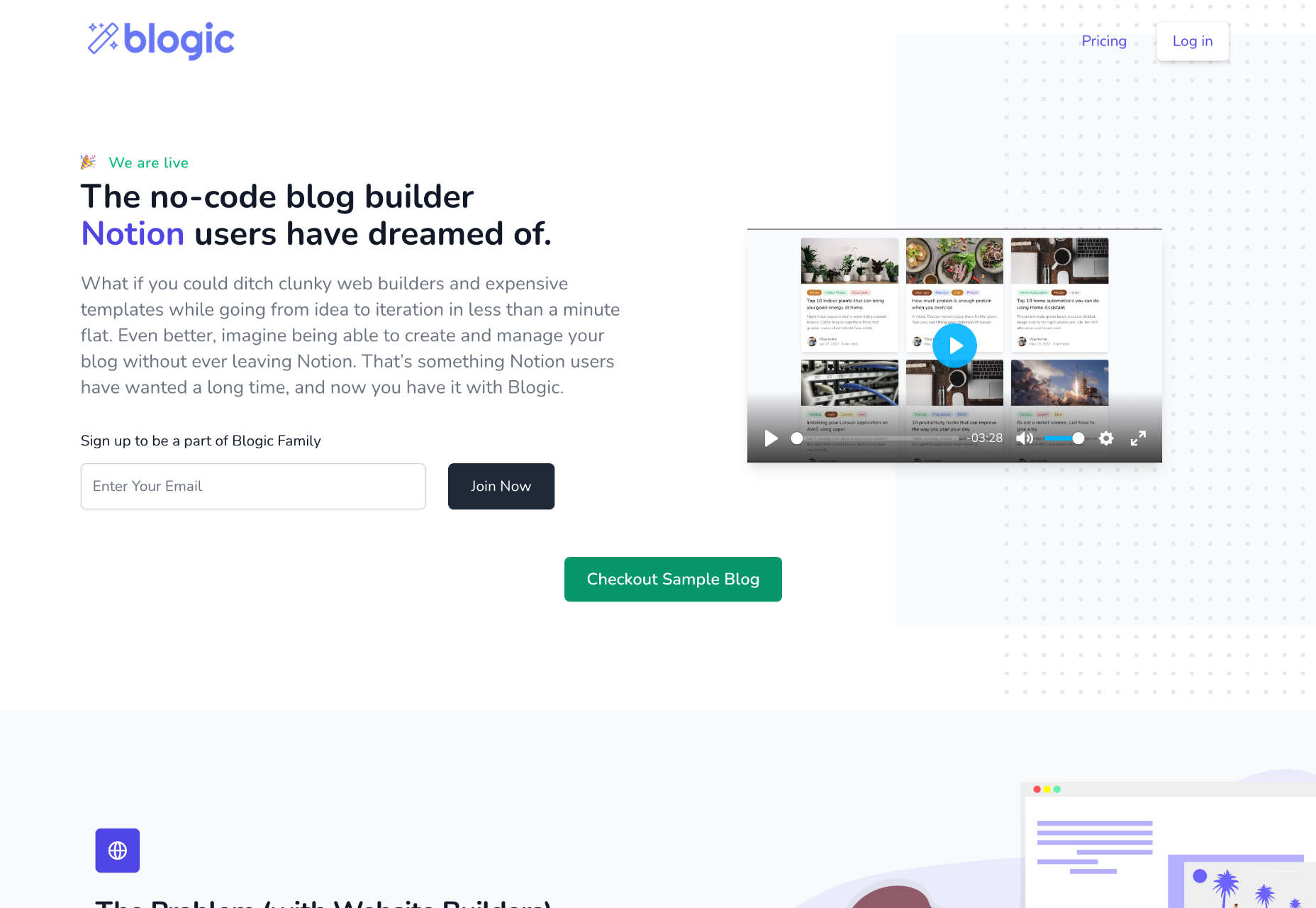
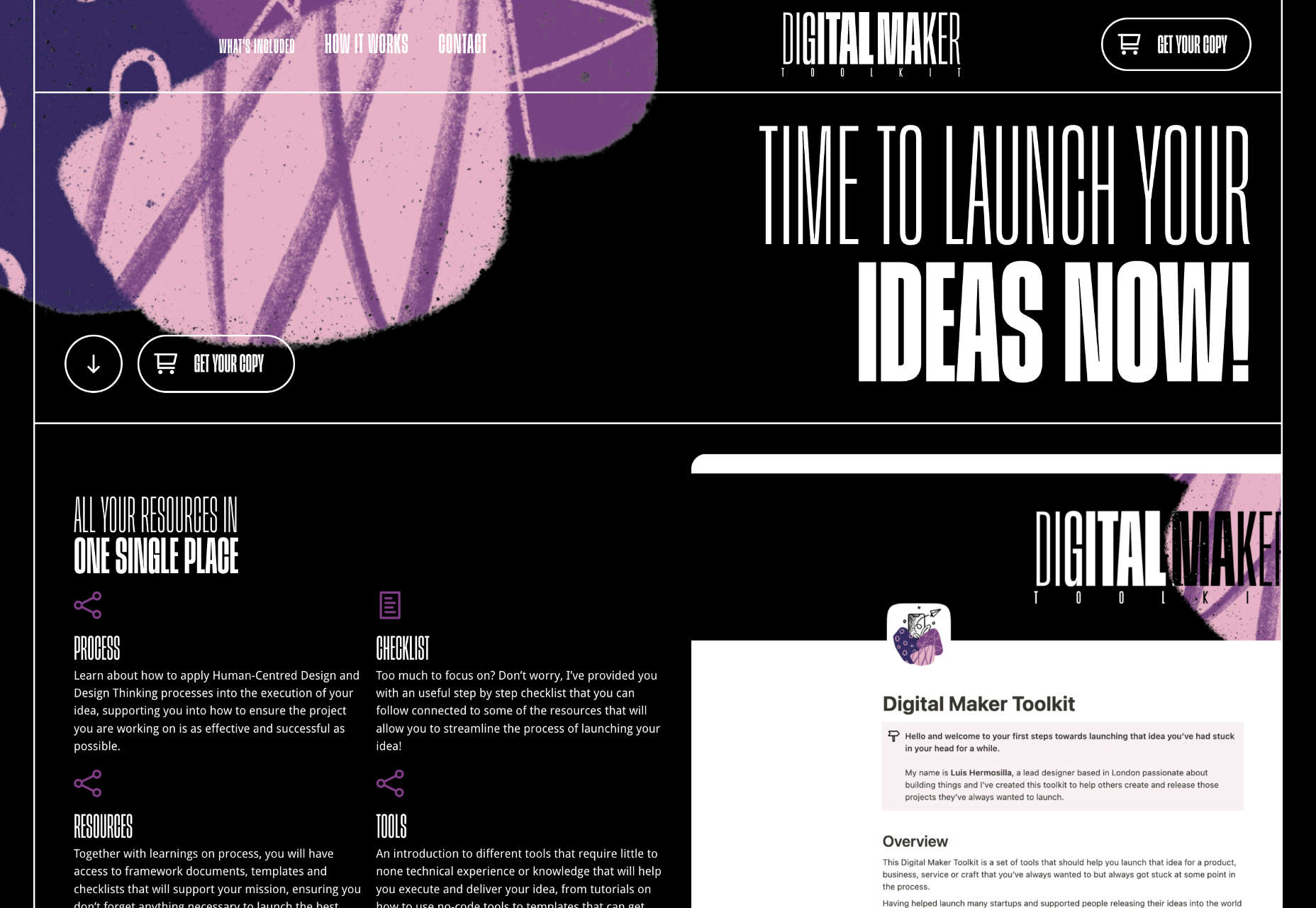
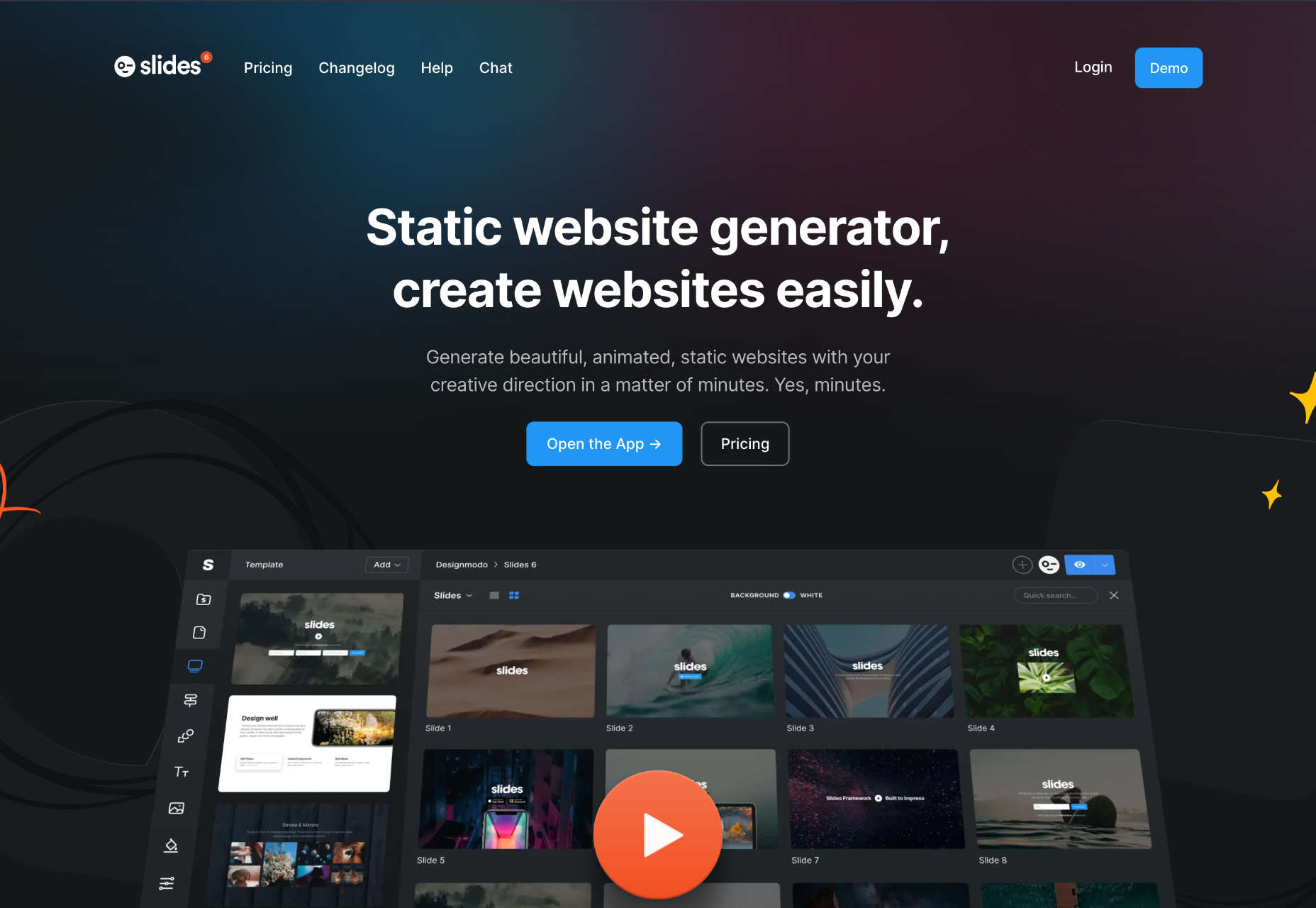
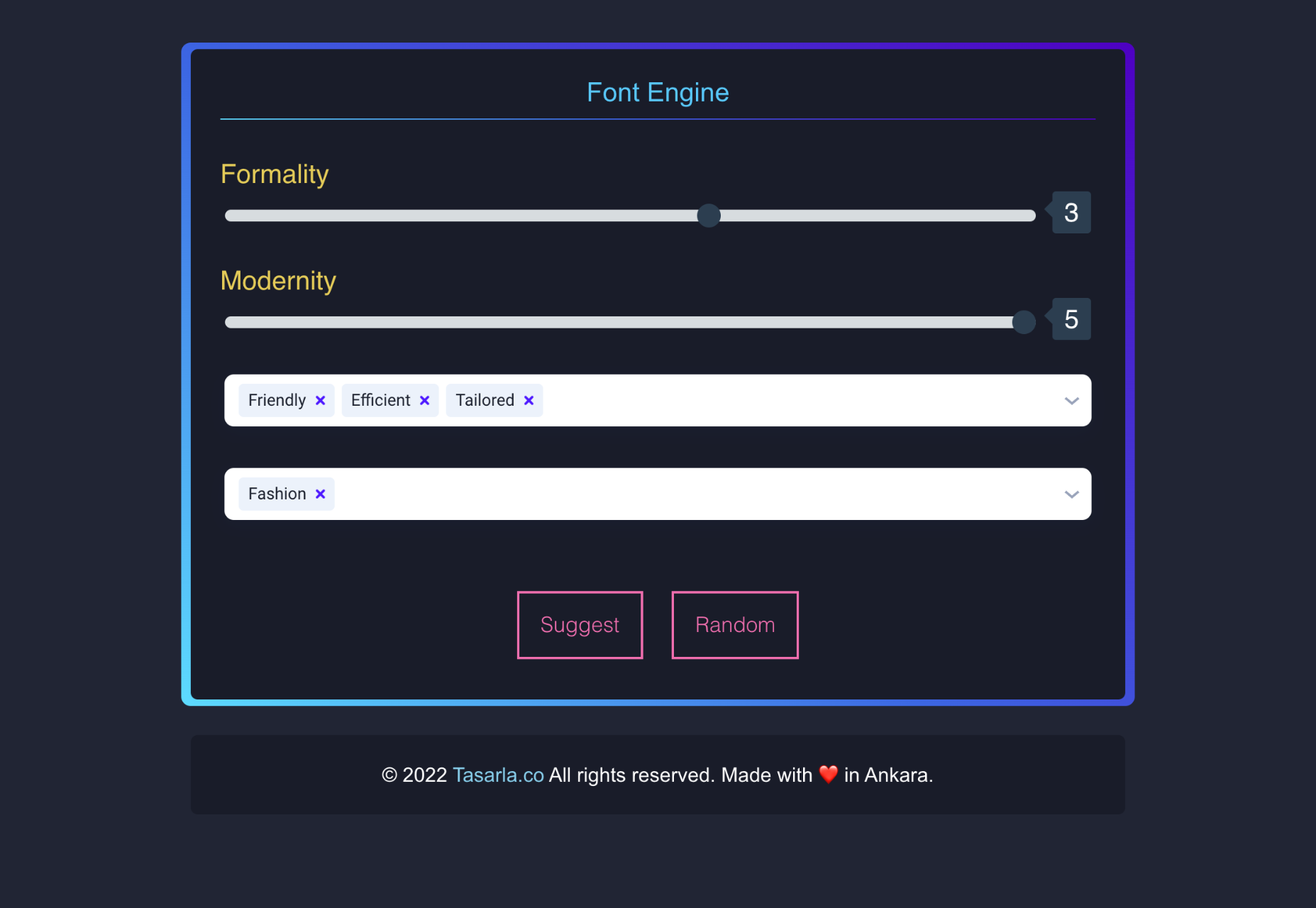
 We write this guide to the best new tools for designers and developers each month. For October, we’ve sought out tools to make you a better website builder, some handy utilities to make you more productive, and a spooky font for the end of the month. Enjoy!
We write this guide to the best new tools for designers and developers each month. For October, we’ve sought out tools to make you a better website builder, some handy utilities to make you more productive, and a spooky font for the end of the month. Enjoy!