In this post, you will learn how to execute penetration tests with OWASP Zed Attack Proxy (ZAP). ZAP is a free web app scanner which can be used for security testing purposes.
1. Introduction
When you are developing an application, security must be addressed. It cannot be ignored anymore nowadays. Security must be taken into account starting from initial development and not thinking about it when you want to deploy to production for the first time. Often you will notice that adding security to your application at a later stage in development, will take a lot of time. It is better to take security into account from the beginning, this will save you from some painful headaches. You probably have some security experts inside of your company, so let them participate from the start when a new application needs to be developed. Nevertheless, you will also need to verify whether your developed application is secure. Penetration tests can help you with that. OWASP Zed Attack Proxy (ZAP) is a tool which can help you execute penetration tests for your application. In this post, you will learn how to setup ZAP and execute tests with the desktop client of ZAP. You will also need a preferably vulnerable application. For this purposes, Webgoat of OWASP will be used. In case you do not know what Webgoat is, you can read a previous post first. It might be a little bit outdated because Webgoat has been improved since then, but it will give you a good impression of what Webgoat is. It is advised to disconnect from the internet when using Webgoat because it may expose your machine to attacks.
Ten years ago, people began talking about the “Independent Web.” Although we don’t commonly use the term anymore, that doesn’t mean that it’s not still as vital a topic of discussion today as it was a decade ago.
Today, I want to look at where the term came from, what it refers to today, and why it’s something that all of us in business, marketing, and web design should be thinking about.
What Is The Independent Web?
The Independent Web is a term that was coined back in 2010 by John Battelle.
In “Identity and The Independent Web,” Battelle broaches the subject of internet users losing control of their data, privacy, and decision-making to the likes of social media and search engines.
“When we’re ‘on’ Facebook, Google, or Twitter, we’re plugged into an infrastructure that locks onto us, serving us content and commerce in an automated but increasingly sophisticated fashion. Sure, we navigate around, in control of our experience, but the fact is, the choices provided to us as we navigate are increasingly driven by algorithms modeled on the service’s understanding of our identity.”
That’s the Dependent Web.
This is how Battelle explains the Independent Web:
“There is another part of the web, one where I can stroll a bit more at my own pace, and discover new territory, rather than have territory matched to a presumed identity. And that is the land of the Independent Web.”
In 2010, this referred to websites, search engines, and apps where users and their activity were not tracked. But a lot has changed since then, and many websites that were once safe to peruse without interference or manipulation are no longer.
What Happens When the Dependent Web Takes Over?
Nothing good.
I take that back. It’s not fair to make a blanket statement about Dependent Web platforms and sites. Users can certainly benefit from sharing some of their data with them.
Take Facebook, for instance. Since its creation, it’s enabled people to connect with long-lost friends, stay in touch with distant relatives, enable freelance professionals like ourselves to find like-minded communities, etc.
The same goes for websites and apps that track and use visitor data. Consumers are more than willing to share relevant data with companies so long as they benefit from the resulting personalized experiences.
But the Dependent Web also has a darker side. There are many ways that the Dependent Web costs consumers and businesses control over important things like:
Behavior
If you’ve seen The Social Dilemma, then you know that platforms like Facebook and Google profit from selling their users to advertisers.
That’s right. They’re not just selling user data. They’re selling users themselves. If the algorithms can change the way users behave, these platforms and their advertisers get to cash in big time.
Many websites and apps are also guilty of using manipulation to force users to behave how they want them to.
Personal Data
This one is well-known thanks to the GDPR in the EU and the CCPA in California. Despite these initiatives to protect user data and privacy, the exploitation of personal data on the web remains a huge public concern in recent years.
Content and Branding
This isn’t relevant to websites so much as it is to social media platforms and Google.
Dependent Web platforms ultimately dictate who sees your content and when. And while they’re more than happy to benefit from the traffic and engagement this content brings to their platforms, they’re just as happy to censor or pull down content as they please, just as Skillshare did in 2019 when it deleted half of its courses without telling its course creators.
What’s more, while social media and search engines have become the place to market our businesses, some of our branding gets lost when entering such oversaturated environments.
Income
When algorithms get updated, many businesses often feel the negative effects almost immediately.
For example, Facebook updated its algorithm in 2018 to prioritize “meaningful content.” This pushed out organic business content and pulled regular user content to the top of the heap.
This, in turn, forced businesses to have to pay-to-play if they wanted to use Facebook as a viable marketing platform.
Access
The Dependent Web doesn’t just impact individuals’ experiences. It can have far-reaching effects when one company provides a critical service to a large portion of the population.
When Amazon Web Services burps and half the Internet goes down maybe just maybe it’s not a great idea to have a single company with so much control over what has essentially become our society’s critical infrastructure?
It wasn’t just Amazon’s servers that went down, though. It took out apps and sites like:
1Password
Adobe Spark
Capital Gazette
Coinbase
Glassdoor
Roku
The Washington Post
And there’s absolutely nothing that these businesses or their users could do but sit around and wait… because Amazon hosts a substantial portion of the web.
Innovation
When consumers and businesses become dependent on platforms that predominantly control the way we live and work, it’s difficult for us to stand up for the little guys trying to carve out innovative pathways.
As a result, we really lose the option to choose what we use to improve our lives and our businesses. And innovative thinkers lose the ability to bring much-needed changes to the world because Big Tech wants to own the vast majority of data and users.
How Can We Take Back Control From The Dependent Web?
Many things are happening right now that are trying to push consumers and businesses towards a more Independent Web:
Consumer Privacy Protection: GDPR and CCPA empower consumers to control where their data goes and what it’s used for.
Private Search Engine Usage: Although Google dominates search engine market share, people are starting to use private search engines like Duck Duck Go.
Private Browsing Growth:Over 60% of the global population is aware of what private browsing is (i.e., incognito mode), and roughly 35% use it when surfing the web.
Self-hosted and Open Source CMS Popularity: The IndieWeb community encourages people to move away from Dependent platforms and build their own websites and communities. This is something that Matt Mullenweg, the founder of WordPress, talked about back in 2012.
“The Internet needs a strong, independent platform for those of us who don’t want to be at the mercy of someone else’s domain. I like to think that if we didn’t create WordPress something else that looks a lot like it would exist. I think Open Source is kind of like our Bill of Rights. It’s our Constitution. If we’re not true to that, nothing else matters.”
As web designers, this is something that should really speak to you, especially if you’ve ever met a lead or client who didn’t understand why they needed a website when they could just advertise on Facebook or Instagram.
A Decentralized Web: Perhaps the most promising of all these initiatives are Solid and Inrupt, which were launched in 2018 by the creator of the Web, Tim Berners-Lee.
”The Web was always meant to be a platform for creativity, collaboration, and free invention — but that’s not what we are seeing today. Today, business transformation is hampered by different parts of one’s life being managed by different silos, each of which looks after one vertical slice of life, but where the users and teams can’t get the insight from connecting that data. Meanwhile, that data is exploited by the silo in question, leading to increasing, very reasonable, public skepticism about how personal data is being misused. That in turn has led to increasingly complex data regulations.”
This is something we should all keep a close eye on. Consumers and businesses alike are becoming wary of the Dependent Web.
Who better than the creator of the web to lead us towards the Independent Web where we can protect our data and better control our experience?
https://ankaa-pmo.com/wp-content/uploads/2021/04/what-is-the-independent-web-and-does-it-matter-in-2021.jpg14082560Service comm.https://ankaa-pmo.com/wp-content/uploads/2017/04/Logo-Ankaa-engineering.pngService comm.2021-04-21 16:45:552021-04-21 16:45:55What Is The Independent Web And Does It Matter In 2021?
Rather than spring cleaning, do some spring “shopping” for tools that will make your design life easier. Packed with free options this month, this list is crammed full of tools and elements that you can use in your work every day.
Here’s what new for designers this month:
April’s Top Picks
Charts.css
Charts.css makes creating beautiful online charts that much easier. It’s a modern CSS framework that uses CSS utility classes to style HTML elements as charts. It’s accessible, customizable, responsive, and open source. There’s a quick start option and available source code to work with.
Haikei SVG Generator
Haikei is a web app that helps you generate SVG shapes, backgrounds, and patterns in all types of shapes to use in projects. Everything can be exported into the tools you are already using for easy integration, and every element is customizable. The tool is free right now – no credit card needed – and you get access to 15 generators and can export in SVG and PNG format. A premium option is on the way, and you can sign up to get notified for access.
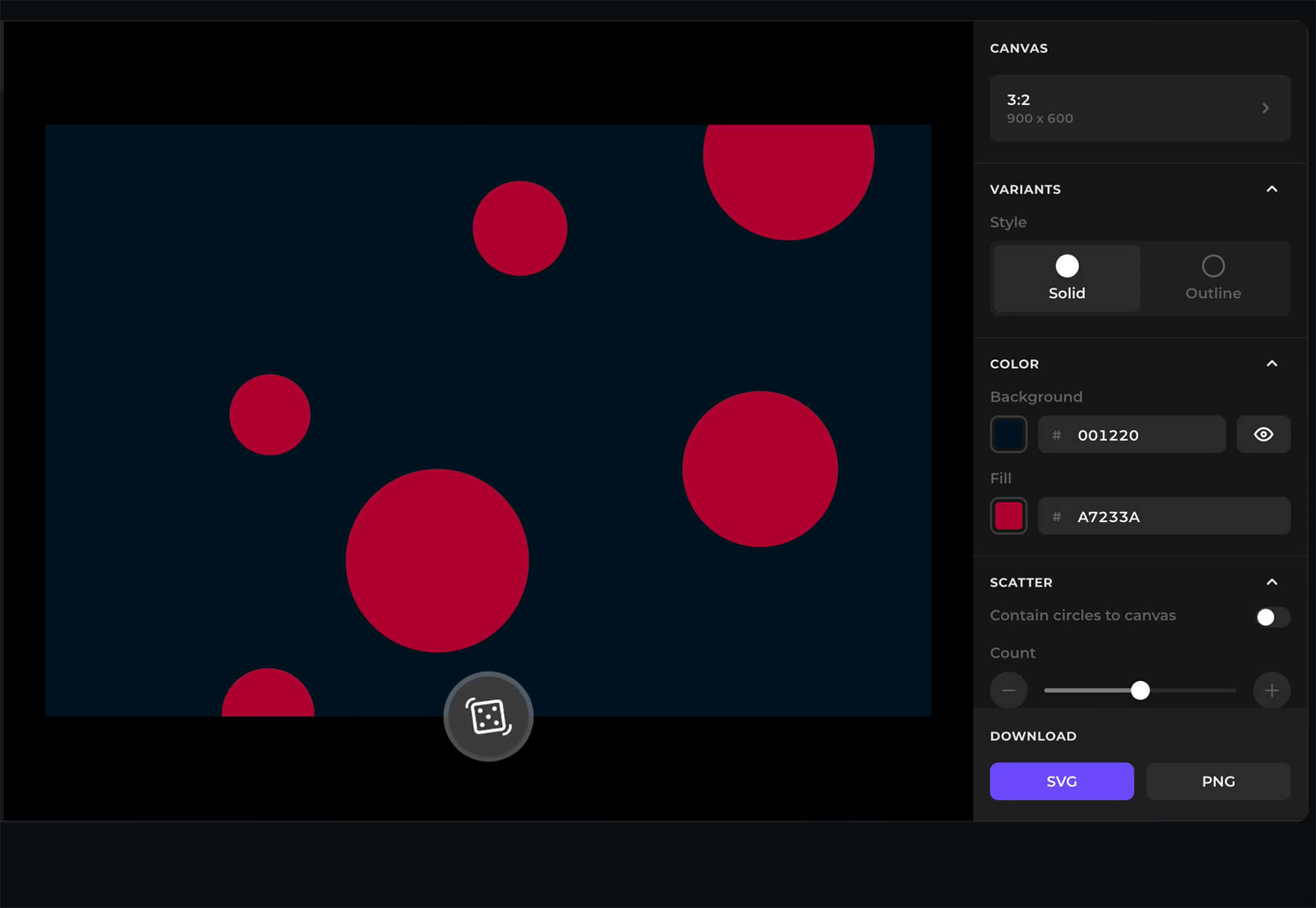
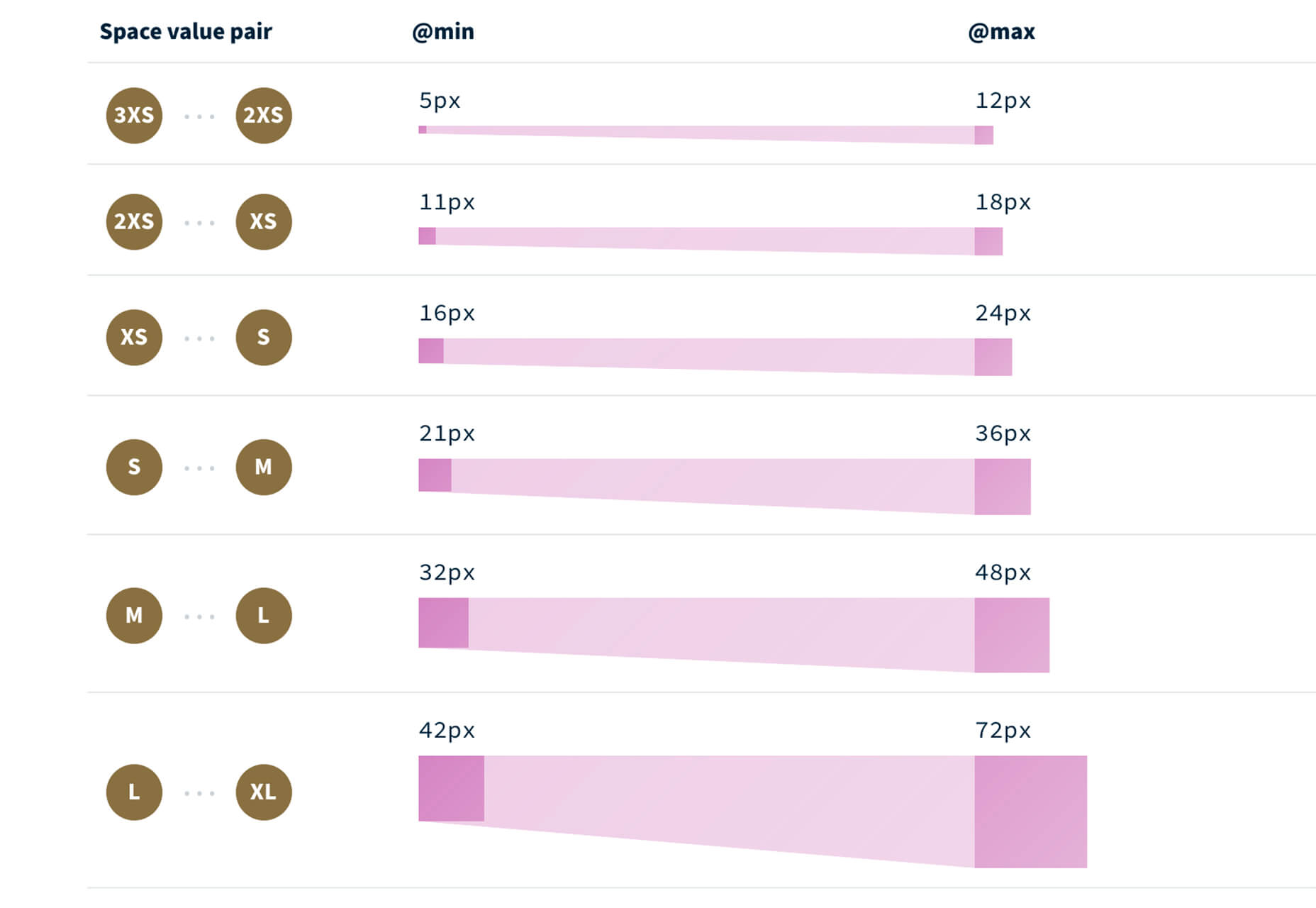
Fluid Space Calculator
Fluid Space Calculator helps you create a related space system and export the CSS to implement it. The calculator allows you to add space value pairs and multipliers and see the impact on the screen before snagging the related code. It’s great for determining how things will look in different viewports and for creating custom space pairs.
Night Eye WordPress Plugin
Night Eye WordPress Plugin helps you create a dark mode option for your WordPress website with ease. It’s completely customizable, schedulable, and one of those things that users are starting to expect. The plugin has free and paid versions – the only difference is a link to credit the developer.
3 Productivity Boosters
Macro
Macro is a supercharged checklist app for recurring processes. It’s designed to help teams document, assign, track, and automate for maximum efficiency. Now is the time to test this tool because it is free in public beta.
Writex.io
Writex.io is a free writing app that uses AI and smart features to help you write more efficiently. It can check readability as you write, make suggestions, check spelling, and allows you to work with versioning. All the settings are customizable, so you can get help and suggestions when you want them and avoid things you don’t want.
Taloflow
Taloflow, which is in beta, is a tool that helps you find the top cloud and dev tools for your use case. This is designed to be a time-saving solution to finding the right infrastructure and API products for your work.
8 Kits with Illustrations and User Interface Elements
Skribbl
Skribbl is a collection of free, hand-drawn illustrations in a light and fun style. The black and white sketches are friendly, and the collection keeps growing. Plus, the illustrators are allowing them to be used free for any use.
Mobile Chat Kit
Mobile Chat Kit is a free starter kit for building apps in Figma, Sketch, and Adobe XD. It includes more than 50 screen options with mapped-out flows for a quick-start project.
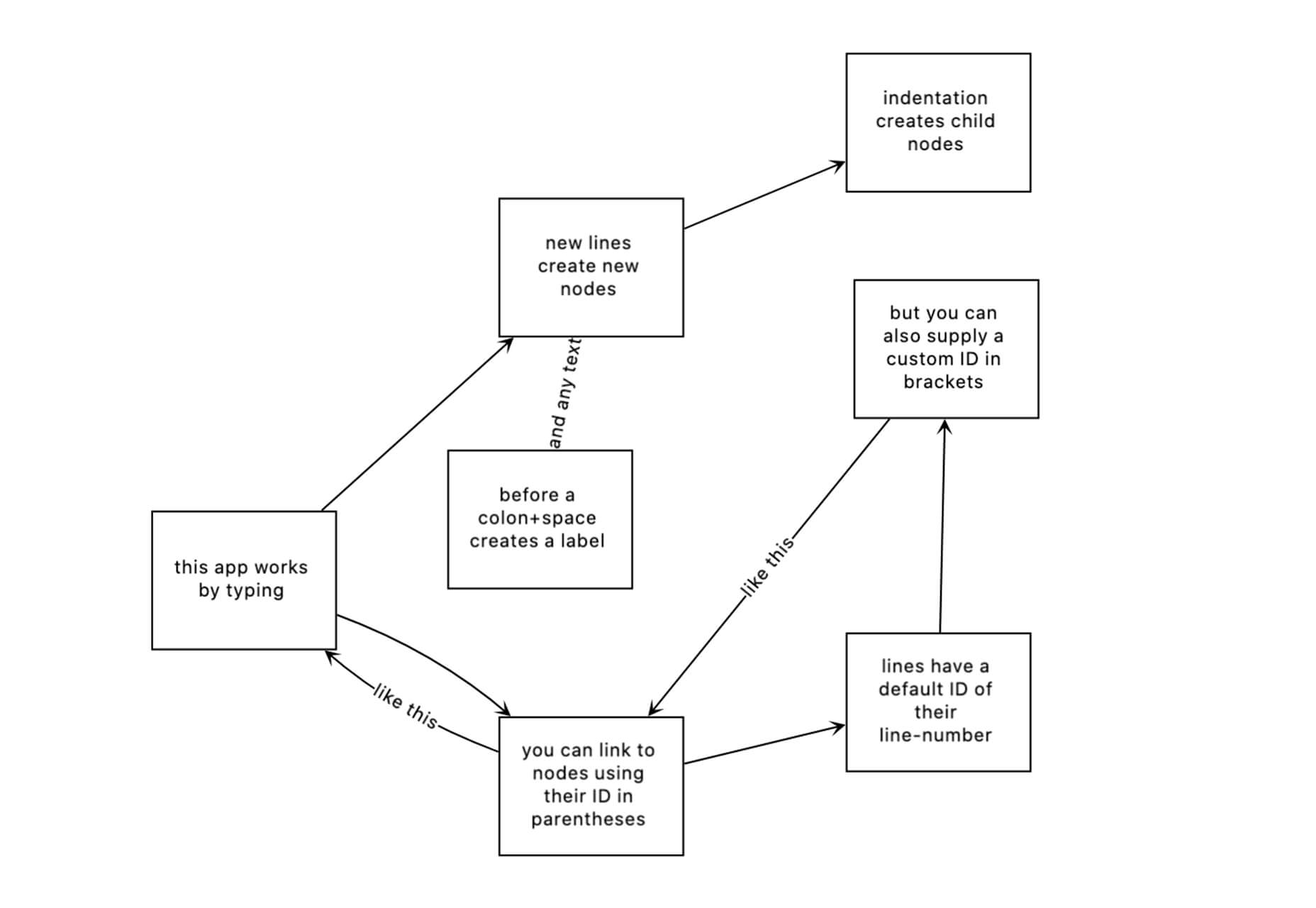
Flowchart.fun
Flowchart.fun is exactly what the name implies. The app allows you to type, create nodes, and link elements to develop simple flow charts quickly. Then you can alter shape and size with drag and drop. Export it for use as an SVG, JPG, or PNG.
Shuffle
Shuffle is a marketplace packed with UI libraries to help you with a variety of digital projects. There are more than 1,500 pre-built components to choose from with professional designs. This premium tool comes with a monthly subscription or lifetime license.
Cryptocurrency 3D Pack
Cryptocurrency 3D Pack is a set of icons with fun colors in three-dimensional shapes that you can use to represent different crypto elements. The pack includes 55 #D icons in PNG and BLEND formats.
Stratum UI Kit for Figma
Stratum UI Kit for Figma includes nine free screens that are ready to use. Options include API documentation, Kanban, document, data dashboard, ecommerce product list, ecommerce product options, payments spreadsheet, cloud storage, and newsfeed.
Conic.css
Conic.css is a collection of simple gradients that you can browse and then click to copy the code into your CSS to use them in projects. It’s quick and easy while using trendy color options.
Artify Illustrations
Artify Illustrations is a Figma plugin that allows you to access more than 5,000 SVG and PNG illustrations within the app. It’s got a built-in search feature, everything is high-resolution, and the huge library includes various styles.
2 Tutorials
A Complete Guide to Accessible Front-End Components
A Complete Guide to Accessible Front-End Components is an amazingly comprehensive guide from Smashing Magazine with everything you need to know about accessible components. From tabs to tables to toggles to tooltips, you’ll find it all here and learn how to use it the right way.
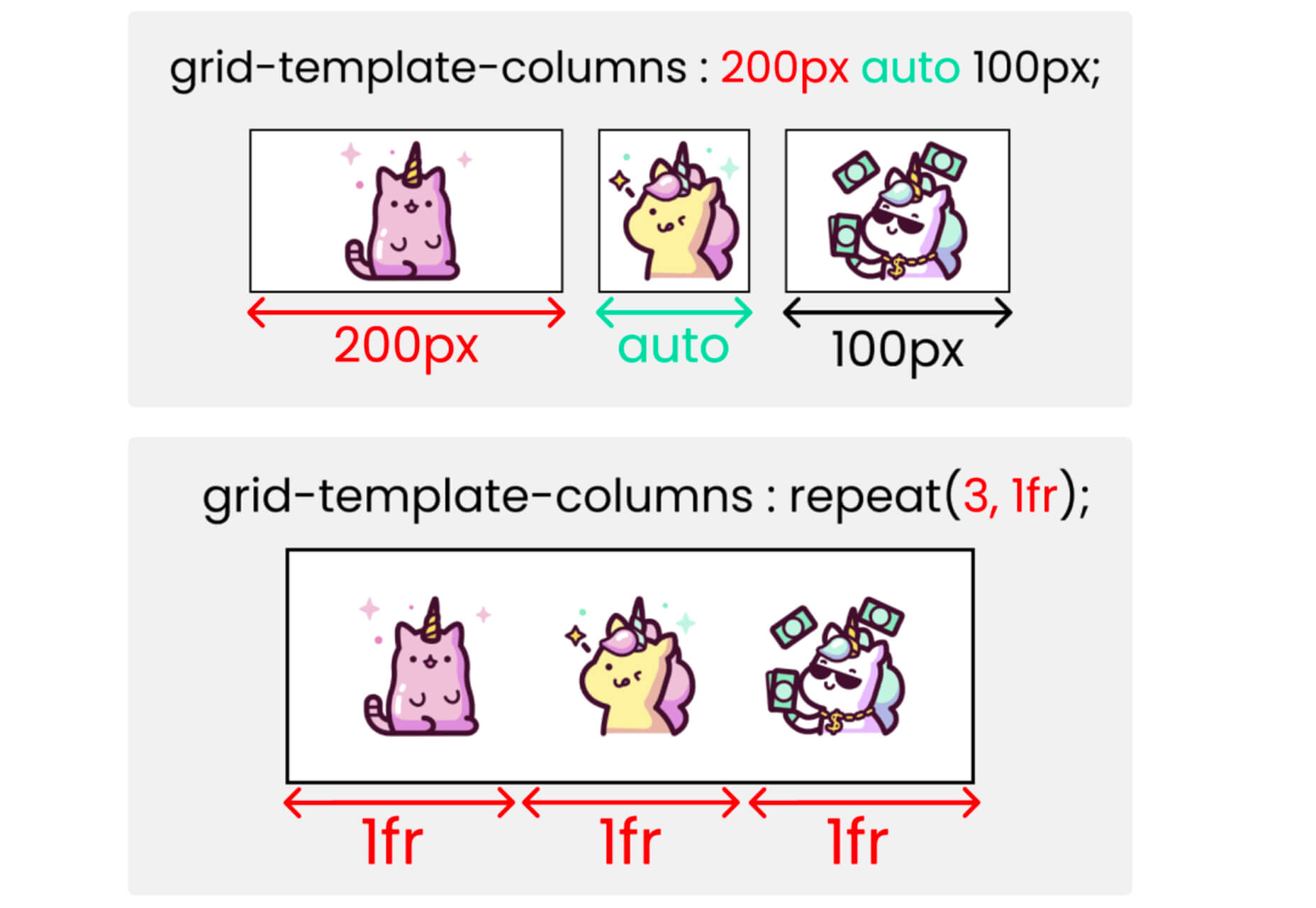
Grid CheatSheet in 2021
Grid CheatSheet in 2021 is a useful guide of everything you can do with CSS Grid. Plus, it has plenty of fun illustrations and an accompanying video.
8 Fresh and Fun Fonts
Athina
Athina is a modern display serif with beautiful connector strokes. The free version is a demo, and there’s a full family that you can buy.
Brique
Brique is a free (personal and commercial) display font with a wide stance and uppercase character set. The letters have a lot of personality and a readable configuration.
Code Next
Code Next is a great geometric sans serif with a full family of styles. Including two variable fonts. It’s highly readable and would work for almost any application.
Inter
Inter is a simple and functional sense serif family with everything from extra light to heavy weights. The extra character personality makes this a fun and functional font option.
Nothing Clean
Nothing Clean is a fun grunge-type option. It’s an all uppercase character set with alternates.
Playout
Playout is a fun, hand-drawn style typeface with interesting glyphs and alternate characters. The most fun feature might be the pawprint characters in the demo set.
Rockford Sans
Rockford Sans is a geometric typeface with subtly rounded edges. It has eight weights and italics. With its large x-height and round features, it’s legible and friendly. It’s suited to cover a wide variety of tasks from editorial to brand design and advertising.
SpaceType
SpaceType is a fun and funky typeface in regular and expanded styles. The stretched letterforms make interesting alternates for display purposes.
https://ankaa-pmo.com/wp-content/uploads/2021/04/25-exciting-new-tools-for-designers-april-2021.jpg14082560Service comm.https://ankaa-pmo.com/wp-content/uploads/2017/04/Logo-Ankaa-engineering.pngService comm.2021-04-19 16:45:302021-04-19 16:45:3025 Exciting New Tools For Designers, April 2021
Every day design fans submit incredible industry stories to our sister-site, Webdesigner News. Our colleagues sift through it, selecting the very best stories from the design, UX, tech, and development worlds and posting them live on the site.
The best way to keep up with the most important stories for web professionals is to subscribe to Webdesigner News or check out the site regularly. However, in case you missed a day this week, here’s a handy compilation of the top curated stories from the last seven days. Enjoy!
https://ankaa-pmo.com/wp-content/uploads/2021/04/popular-design-news-of-the-week-april-12-2021-april-18-2021.jpg14082560Service comm.https://ankaa-pmo.com/wp-content/uploads/2017/04/Logo-Ankaa-engineering.pngService comm.2021-04-18 16:45:242021-04-18 16:45:24Popular Design News Of The Week: April 12, 2021 – April 18, 2021
Gloo Edge is our Kubernetes native API gateway based on Envoy.
It provides Authentication (OAuth, JWT, API keys, JWT, …), Authorization (OPA, custom, …), Web Application Firewall (based on ModSecurity), function discovery (OpenAPI based, Lambda, …), advanced transformations, and much more.
Over the last fortnight one site builder has gone toe-to-toe with another, as Wix launched a marketing campaign aimed at attracting WordPress users, and instead attracted universal ire.
First, Wix sent out expensive headphones as gifts to key WordPress “influencers” in an attempt to lure them to the platform. Second, they produced a series of adverts that instead of promoting their own product, tried to imply that WordPress is so bad you’ll need mental health counselling to cope with it; it’s been widely frowned upon, but am I alone in thinking they’re not a million miles away from Apple’s anti-Windows adverts? No, I’m not.
Then, Wix made an attempt to go viral with an uncomfortable video in which a character portraying “WordPress” releases a “secret” message warning the community of “fake news” supposedly due to be released by Wix. The language and the styling is clear: WordPress is unhip daddio.
Unlike WordPress, Wix is a publicly owned company, it has an obligation to its shareholders to maximize its revenue. Had Wix targeted WordPress’ many failings, that would have been fair game. Had they gone after Shopify, or Webflow, or Squarespace, or one of the many other site builders on the market no one would have blinked an eye. Wix’s error wasn’t going after WordPress, or even the tactics used to do so, Wix’s mistake was in attacking the very community it was attempting to court.
I’m not a big fan of WordPress. I’ve built around a dozen sites in it over the years and we’ve never got along, WordPress and I. But I am a big fan of the ethos of WordPress; who doesn’t love free, open source software, built by volunteers?
The holy grail of marketing is transforming customers into evangelists — individuals who will bare their chests, paint their face with woad, and charge headlong onto social media at the merest hint of a perceived slight. You can’t buy them. It’s a loyalty that has to be cultivated over years, and requires more give than take. WordPress has those evangelists, people who see their careers in web design as intertwined with the CMS. No amount of free headphones is going to convert them to a closed system like Wix.
The irony is that Wix’s approach stemmed from the WordPress community itself. If it is going to celebrate “powering 40% of the Web” then it has to expect to make itself a target. If you’re an antelope, you don’t douse yourself in bbq sauce and strut around the waterhole where the lions like to hang out.
If the row rumbles on, it will eventually end in an apology and a promise from Wix to “do better.” But the truth is, all Wix did was confuse a community of people trying to build websites, with a competing business.
This time next year, Wix will still be recovering from the damage to its reputation, and WordPress will be telling us it powers 110% of the Web.
We all know that Google Chrome is the most popular browser in the world. But do you know, with 17.24% of the overall browser market share, Safari is the second most popular one?
The reason behind Safari’s strong presence is that it is the default web browser for all Apple devices. And we know how much developers and coders love macOS, making it absolutely necessary to ensure that our websites’ are tested and optimized for all Safari versions.
https://ankaa-pmo.com/wp-content/uploads/2021/04/how-to-run-test-on-macos-using-selenium-safari-driver.jpg375600Service comm.https://ankaa-pmo.com/wp-content/uploads/2017/04/Logo-Ankaa-engineering.pngService comm.2021-04-16 10:01:292021-04-16 10:01:29How To Run Test On macOS Using Selenium Safari Driver
We’re no longer arguing about whether climate change exists because climate change is now extensively documented. Instead, we’re arguing over whether climate change is a natural cycle or human-accelerated.
At this point, the reasonable best-case (yes, best-case) scenario is that global temperatures will rise by 2˚C — if we don’t meet our global emissions targets, then it will be higher.
A 2˚C rise in temperature means a rise in sea levels of approximately 20m in the next 100 years. Major cities, including New York and London, will be decimated. Florida will become an island off the coast of Georgia. Venice is in serious trouble, as is the whole of the Netherlands. Many low-lying island nations will cease to exist. If we do nothing, there may not be enough farmable land left to sustain the population.
According to sustainablewebdesign.org, the whole Internet currently churns out 3.8% of global carbon emissions. Next Tuesday is Earth Day 2021, making this a great time to think about your own sites’ carbon footprint.
The key to reducing a website’s carbon footprint is to use as little electricity as possible — including battery power because batteries need to be charged. Some simple ways to achieve this are using dark mode, limiting the amount of resource-hungry JavaScript you use, and limiting your site’s payload. Small incremental gains like these can radically reduce the damage your sites are doing, and conveniently they also happen to be good for UX.
But let’s look at the numbers. An environmentally consciously designed site that gets 100,000 page views per year will output around 0.055 tons of CO2 per annum. By comparison, the average human produces 4 tons of CO2 (in Western countries, it’s closer to 16 tons) over the same period. The world as a whole produces 43.1 billion tons of CO2 per year. If you redesign your site to reduce power usage by 10%, you’ll have solved 0.0000000000001% of the problem.
With such a small impact on such a huge problem, is it really worth changing how we design websites to limit climate change?
Le Big Data est le flot d’informations dans lequel nous nous trouvons tous les jours (des zettaoctets de données provenant de nos ordinateurs, des terminaux mobiles et des capteurs). Ces données sont utilisées par les entreprises pour orienter la prise de décisions, améliorer les processus et les stratégies, et créer des produits, des services et des expériences centrés sur le client.
Le Big Data désigne non seulement de gros volumes de données, mais aussi des données de nature variée et complexe. Il dépasse généralement la capacité des bases de données traditionnelles à capturer, gérer et traiter ce type de données. De plus, le Big Data peut provenir de n’importe où et de tout ce que nous sommes en mesure de surveiller numériquement. Les satellites, les appareils IoT (Internet des Objets), les radars et les tendances des réseaux sociaux ne sont que quelques exemples parmi la multitude de sources de données explorées et analysées pour rendre les entreprises plus résilientes et compétitives.
L’importance de l’analyse du Big Data
La véritable valeur du Big Data se mesure d’après votre capacité à l’analyser et à le comprendre. L’intelligence artificielle (IA), le machine learning et les technologies de base de données modernes permettent de visualiser et d’analyser le Big Data pour fournir des informations exploitables en temps réel. L’analyse du Big Data aide les entreprises à exploiter leurs données en vue de saisir de nouvelles opportunités et de créer de nouveaux modèles de gestion. Comme l’a si bien dit Geoffrey Moore, auteur et analyste de gestion, « sans analyse du Big Data, les entreprises sont aveugles et sourdes, errant sur le Web comme des cerfs sur une autoroute ».
Aussi inconcevable que cela puisse paraître aujourd’hui, l’Apollo Guidance Computer a emmené l’homme sur la lune avec moins de 80 kilo-octets de mémoire. Depuis, la technologie informatique s’est développée à un rythme exponentiel, de même que la génération de données. La capacité technologique mondiale à stocker des données a doublé tous les trois ans depuis les années 1980. Il y a un peu plus de 50 ans, lors du lancement d’Apollo 11, la quantité de données numériques générées dans le monde aurait pu tenir dans un ordinateur portable. Aujourd’hui, l’IDC estime ce chiffre à 44 zettaoctets (soit 44 000 milliards de gigaoctets) et prévoit qu’il atteindra 163 zettaoctets en 2025.
44zettaoctets de données numériques aujourd’hui, IDC
Plus les logiciels et la technologie se développent, moins les systèmes non numériques sont viables. Le traitement des données générées et collectées numériquement requiert des systèmes de data management plus avancés. En outre, la croissance exponentielle des plates-formes de réseaux sociaux, des technologies pour smartphones et des appareils IoT connectés numériquement ont contribué à l’émergence du Big Data.
Types de Big Data : que sont les données structurées et non structurées ?
Les ensembles de données sont généralement catégorisés en trois types, selon leur structure et la complexité de leur indexation.
Données structurées : ce type de données est le plus simple à organiser et à rechercher. Il peut inclure des données financières, des machine logs et des détails démographiques. Une feuille de calcul Microsoft Excel, avec sa mise en forme de colonnes et de lignes prédéfinies, offre un moyen efficace de visualiser les données structurées. Ses composants peuvent facilement être catégorisés, ce qui permet aux concepteurs et administrateurs de bases de données de définir des algorithmes simples pour la recherche et l’analyse. Même lorsque les données structurées sont très volumineuses, elles ne sont pas nécessairement qualifiées de Big Data, car elles sont relativement simples à gérer et ne répondent donc pas aux critères qui définissent le Big Data. Traditionnellement, les bases de données utilisent un langage de programmation appelé SQL (Structured Query Language) pour gérer les données structurées. SQL a été développé par IBM dans les années 1970 pour permettre aux développeurs de créer et gérer des bases de données relationnelles (de type feuille de calcul) qui commençaient à émerger à l’époque.
Données non structurées : cette catégorie de données peut inclure des publications sur les réseaux sociaux, des fichiers audio, des images et des commentaires client ouverts. Ces données ne peuvent pas être facilement capturées dans les bases de données relationnelles standard en lignes et colonnes. Auparavant, les entreprises qui voulaient rechercher, gérer ou analyser de grandes quantités de données non structurées devaient utiliser des processus manuels laborieux. La valeur potentielle liée à l’analyse et à la compréhension de ces données ne faisait aucun doute, mais le coût associé était souvent trop exorbitant pour en valoir la peine. Compte tenu du temps nécessaire, les résultats étaient souvent obsolètes avant même d’être générés. Contrairement aux feuilles de calcul ou aux bases de données relationnelles, les données non structurées sont généralement stockées dans des lacs de données, des entrepôts de données et des bases de données NoSQL.
Données semi-structurées : comme leur nom l’indique, les données semi-structurées intègrent à la fois des données structurées et non structurées. Les e-mails en sont un bon exemple, car ils incluent des données non structurées dans le corps du message, ainsi que d’autres propriétés organisationnelles telles que l’expéditeur, le destinataire, l’objet et la date. Les dispositifs qui utilisent le marquage géographique, les horodatages ou les balises sémantiques peuvent également fournir des données structurées avec un contenu non structuré. Une image de smartphone non identifiée, par exemple, peut indiquer qu’il s’agit d’un selfie et préciser l’heure et l’endroit où il a été pris. Une base de données moderne exécutant une technologie d’IA peut non seulement identifier instantanément différents types de données, mais aussi générer des algorithmes en temps réel pour gérer et analyser efficacement les ensembles de données disparates.
Les sources du Big Data
Les objets générateurs de données se développent à un rythme spectaculaire, depuis les drones jusqu’aux grille-pains. Toutefois, à des fins de catégorisation, les sources de données sont généralement divisées en trois types :
Données sociales
Comme leur nom l’indique, les données sociales sont générées par les réseaux sociaux : commentaires, publications, images et, de plus en plus, vidéos. En outre, compte tenu de l’ubiquité croissante des réseaux 4G et 5G, on estime que le nombre de personnes dans le monde qui regardent régulièrement des contenus vidéo sur leur smartphone atteindra 2,72 milliards en 2023. Bien que les tendances concernant les réseaux sociaux et leur utilisation évoluent rapidement et de manière imprévisible, leur progression en tant que générateurs de données numériques est incontestable.
Données machine
Les machines et appareils IoT sont équipés de capteurs et ont la capacité d’envoyer et de recevoir des données numériques. Les capteurs IoT aident les entreprises à collecter et traiter les données machine provenant des appareils, des véhicules et des équipements. Globalement, le nombre d’objets générateurs de données augmente rapidement, des capteurs météorologiques et de trafic jusqu’à la surveillance de la sécurité. Selon l’IDC, il y aura plus de 40 milliards d’appareils IoT en 2025, générant près de la moitié des données numériques mondiales.
Données altérables
Il s’agit des données parmi les plus évolutives au monde. Par exemple, un détaillant international traite plus d’un million de transactions client par heure. Si l’on ajoute à cela les transactions d’achat et bancaires au niveau mondial, on comprend mieux le volume phénoménal de données générées. En outre, les données altérables contiennent de plus en plus de données semi-structurées, y compris des images et des commentaires, ce qui les rend d’autant plus complexes à gérer et à traiter.
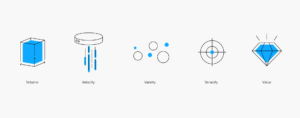
Les cinq V du Big Data
Ce n’est pas parce qu’un ensemble de données est volumineux qu’il s’agit nécessairement de Big Data. Pour être qualifiées en tant que telles, les données doivent posséder au minimum les cinq caractéristiques suivantes :
Volume : même si le volume n’est pas le seul composant qui constitue le Big Data, il s’agit d’une de ses caractéristiques principales. Pour gérer et exploiter pleinement le Big Data, des algorithmes avancés et des analyses pilotées par l’IA sont nécessaires. Mais avant tout cela, il doit exister un moyen fiable et sécurisé de stocker, d’organiser et d’extraire les téraoctets de données détenus par les grandes entreprises.
Vitesse : auparavant, les données générées devaient ensuite être saisies dans un système de base de données traditionnel (souvent manuellement) avant de pouvoir être analysées ou extraites. Aujourd’hui, grâce à la technologie du Big Data, les bases de données sont capables de traiter, d’analyser et de configurer les données lorsqu’elles sont générées, parfois en l’espace de quelques millisecondes. Pour les entreprises, cela signifie que les données en temps réel peuvent être exploitées pour saisir des opportunités financières, répondre aux besoins des clients, prévenir la fraude et exécuter toute autre activité pour laquelle la rapidité est un facteur clé.
Variété : les ensembles de données contenant uniquement des données structurées ne relèvent pas nécessairement du Big Data, quel que soit leur volume. Le Big Data comprend généralement des combinaisons de données structurées, non structurées et semi-structurées. Les solutions de gestion des données et les bases de données traditionnelles n’offrent pas la flexibilité et le périmètre nécessaires pour gérer les ensembles de données complexes et disparates qui constituent le Big Data.
Véracité : bien que les bases de données modernes permettent aux entreprises d’accumuler et d’identifier des volumes considérables de Big Data de différents types, elles ne sont utiles que si elles sont précises, pertinentes et opportunes. S’agissant des bases de données traditionnelles alimentées uniquement avec des données structurées, le manque de précision des données était souvent dû à des erreurs syntaxiques et des fautes de frappe. Les données non structurées présentent toute une série de nouvelles difficultés en matière de véracité. Les préjugés humains, le « bruit social » et les problèmes liés à la provenance des données peuvent avoir un impact sur la qualité des données.
Valeur : les résultats de l’analyse du Big Data sont souvent fascinants et inattendus. Mais pour les entreprises, l’analyse du Big Data doit fournir une visibilité qui les aident à gagner en compétitivité et en résilience, et à mieux servir leurs clients. Les technologies modernes du Big Data offrent la possibilité de collecter et d’extraire des données susceptibles de procurer un avantage mesurable à la fois en termes de résultats et de résilience opérationnelle.
Avantages du Big Data
Les solutions modernes de gestion du Big Data permettent aux entreprises de transformer leurs données brutes en informations pertinentes avec une rapidité et une précision sans précédent.
Développement de produits et de services :l’analyse du Big Data permet aux développeurs de produits d’analyser les données non structurées, telles que les témoignages clients et les tendances culturelles, et de réagir rapidement.
Maintenance prédictive : dans le cadre d’uneenquête internationale, McKinsey a constaté que l’analyse du Big Data émanant des machines IoT pouvait réduire les coûts de maintenance des équipements jusqu’à 40 %.
Expérience client :dans le cadre d’une enquête réalisée en 2020 auprès de responsables d’entreprises du monde entier, Gartner a déterminé que « les entreprises en croissance collectent plus activement des données sur l’expérience client que les entreprises à croissance nulle ». L’analyse du Big Data permet aux entreprises d’améliorer et de personnaliser l’expérience de leurs clients avec leur marque.
Gestion de la résilience et des risques :la pandémie de COVID-19 a été une véritable prise de conscience pour de nombreux dirigeants d’entreprise qui se sont rendu compte à quel point leur activité était vulnérable. La visibilité offerte par le Big Data peut aider les entreprises à anticiper les risques et à se préparer aux imprévus.
Économies et efficacité accrue : lorsque les entreprises effectuent une analyse avancée du Big Data pour tous les processus de l’organisation, elles peuvent non seulement détecter les inefficacités, mais aussi déployer des solutions rapides et efficaces.
Amélioration de la compétitivité : les informations obtenues grâce au Big Data peuvent aider les entreprises à réaliser des économies, à satisfaire leurs clients, à concevoir de meilleurs produits et à innover dans les opérations de gestion.
IA et Big Data
La gestion du Big Data repose sur des systèmes capables de traiter et d’analyser efficacement de gros volumes d’informations disparates et complexes. À cet égard, le Big Data et l’IA ont une relation de réciprocité. Sans l’IA pour l’organiser et l’analyser, le Big Data n’aurait pas grande utilité. Et pour que l’IA puisse générer des analyses suffisamment fiables pour être exploitables, le Big Data doit contenir des ensembles de données suffisamment étendus. Comme l’indique Brandon Purcell, analyste chez Forrester Research, « les données sont au cœur de l’intelligence artificielle. Un système d’IA doit apprendre des données pour remplir sa fonction ».
« Les données sont au cœur de l’intelligence artificielle. Un système d’IA doit apprendre des données pour remplir sa fonction ».
Brandon Purcell, analyste, Forrester Research
Machine learning et Big Data
Les algorithmes de machine learning définissent les données entrantes et identifient des modèles associés. Ces informations permettent de prendre des décisions avisées et d’automatiser les processus. Le machine learning se nourrit du Big Data, car plus les ensembles de données analysés sont fiables, plus le système est susceptible d’apprendre, de faire évoluer et d’adapter ses processus en continu.
Technologies du Big Data
Architecture du Big Data
À l’instar de l’architecture du bâtiment, l’architecture du Big Data fournit un modèle pour la structure de base déterminant la manière dont les entreprises gèrent et analysent leurs données. L’architecture du Big Data mappe les processus requis pour gérer le Big Data à travers quatre « couches » de base, des sources de données au stockage des données, puis à l’analyse du Big Data, et enfin via la couche de consommation dans laquelle les résultats analysés sont présentés en tant que Business Intelligence.
Analyse du Big Data
Ce processus permet de visualiser les données de manière pertinente grâce à l’utilisation de la modélisation des données et d’algorithmes spécifiques aux caractéristiques du Big Data. Dans le cadre d’une étude approfondie et d’une enquête de la MIT Sloan School of Management, plus de 2 000 dirigeants d’entreprise ont été interrogés sur leur expérience en matière d’analyse du Big Data. Comme on pouvait s’y attendre, ceux qui s’étaient impliqués dans le développement de stratégies de gestion du Big Data ont obtenu les résultats les plus significatifs.
Big Data et Apache Hadoop
Imaginez une grande boîte contenant 10 pièces de 10 centimes et 100 pièces de 5 centimes. Puis imaginez 10 boîtes plus petites, côte à côte, contenant chacune 10 pièces de 5 centimes et une seule pièce de 10 centimes. Dans quel scénario sera-t-il plus facile de repérer les pièces de 10 centimes ? Hadoop fonctionne sur ce principe. Il s’agit d’une structure en open source permettant de gérer le traitement du Big Data distribué sur un réseau constitué de nombreux ordinateurs connectés. Ainsi, au lieu d’utiliser un gros ordinateur pour stocker et traiter toutes les données, Hadoop regroupe plusieurs ordinateurs sur un réseau pouvant évoluer presque à l’infini et analyse les données en parallèle. Ce processus utilise généralement un modèle de programmation appelé MapReduce, qui coordonne le traitement du Big Data en regroupant les ordinateurs distribués.
Lacs de données, entrepôts de données et NoSQL
Les bases de données traditionnelles de type feuille de calcul SQL servent à stocker les données structurées. Le Big Data non structuré et semi-structuré nécessite des modèles de stockage et de traitement uniques, car il ne peut pas être indexé et catégorisé. Les lacs de données, les entrepôts de données et les bases de données NoSQL sont des référentiels de données capables de gérer les ensembles de données non traditionnels. Un lac de données est un vaste pool de données brutes qui n’ont pas encore été traitées. Un entrepôt de données est un référentiel de données qui ont déjà été traitées à des fins spécifiques. Les bases de données NoSQL fournissent un schéma flexible qui peut être modifié en fonction de la nature des données à traiter. Ces systèmes présentent chacun des avantages et des inconvénients, c’est pourquoi de nombreuses entreprises utilisent plutôt une combinaison de ces référentiels de données pour répondre au mieux à leurs besoins.
Bases de données in-memory
Les bases de données traditionnelles sur disque ont été conçues pour SQL et les bases de données relationnelles. Bien qu’elles soient capables de traiter de gros volumes de données structurées, elles ne sont pas adaptées au stockage et au traitement des données non structurées. Dans le cas des bases de données in-memory, le traitement et l’analyse se font entièrement dans la RAM, pour ne pas avoir à extraire les données d’un système sur disque. Les bases de données in-memory reposent également sur des architectures distribuées. Cela signifie qu’elles peuvent atteindre des vitesses beaucoup plus élevées en utilisant le traitement parallèle, par rapport aux modèles de base de données sur disque à un seul nœud.
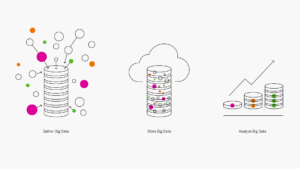
Fonctionnement du Big Data
Le Big Data remplit ses fonctions lorsque son analyse fournit des informations pertinentes et exploitables qui améliorent l’activité de manière significative. Pour se préparer à la transition vers le Big Data, les entreprises doivent s’assurer que leurs systèmes et processus sont en mesure de collecter, de stocker et d’analyser le Big Data.
Collecter le Big Data.Une grande partie du Big Data est constituée d’énormes ensembles de données non structurées qui émanent de sources disparates et incohérentes. Les bases de données traditionnelles sur disque et les mécanismes d’intégration des données ne sont pas suffisamment performants pour les gérer. La gestion du Big Data requiert des solutions de base de données in-memory et des solutions logicielles spécifiques de l’acquisition de ce type de données.
Stocker le Big Data.Comme son nom l’indique, le Big Data est volumineux. De nombreuses entreprises utilisent des solutions de stockage sur site pour leurs données existantes et espèrent réaliser des économies en réutilisant ces référentiels pour traiter le Big Data. Toutefois, le Big Data est plus performant lorsqu’il n’est pas soumis à des contraintes de taille et de mémoire. Les entreprises qui n’intègrent pas dès le départ des solutions de stockage Cloud dans leurs modèles de Big Data le regrettent souvent quelques mois plus tard.
Analyser le Big Data. Il est impossible d’exploiter pleinement le potentiel du Big Data sans utiliser les technologies d’IA et de machine learning pour l’analyser. L’un des cinq V du Big Data est la « vitesse ». Pour être utiles et exploitables, les informations du Big Data doivent être générées rapidement. Les processus d’analyse doivent s’auto-optimiser et tirer régulièrement profit de l’expérience, un objectif qui ne peut être atteint qu’avec l’IA et les technologies modernes de bases de données.
Applications du Big Data
La visibilité offerte par le Big Data est bénéfique à la plupart des entreprises ou secteurs d’activité. Cependant, ce sont les grandes entreprises aux missions opérationnelles complexes qui en tirent souvent le meilleur parti.
Finance
Dans le Journal of Big Data, une étude de 2020 souligne que le Big Data « joue un rôle important dans l’évolution du secteur des services financiers, en particulier dans le commerce et les investissements, la réforme fiscale, la détection et les enquêtes en matière de fraude, l’analyse des risques et l’automatisation ». Le Big Data a également contribué à transformer le secteur financier en analysant les données et les commentaires des clients pour obtenir les informations nécessaires à l’amélioration de la satisfaction et de l’expérience client. Les ensembles de données altérables figurent parmi les plus importants et les plus évolutifs au monde. L’adoption croissante de solutions avancées de gestion du Big Data permettra aux banques et aux établissements financiers de protéger ces données et de les utiliser d’une manière qui bénéficie à la fois au client et à l’entreprise.
Hygiène et santé
publique
L’analyse du Big Data permet aux professionnels de santé d’établir des diagnostics plus précis, fondés sur des données avérées. De plus, le Big Data aide les administrateurs d’hôpitaux à identifier les tendances, à gérer les risques et à limiter les dépenses inutiles, afin de consacrer le maximum de fonds aux soins des patients et à la recherche. En cette période de pandémie, les chercheurs du monde entier s’efforcent de traiter et de gérer au mieux la COVID-19, et le Big Data joue un rôle fondamental dans ce processus. Un article de juillet 2020 paru dans The Scientist explique comment des équipes médicales ont pu collaborer et analyser le Big Data afin de lutter contre le coronavirus : « Nous pourrions transformer la science clinique en exploitant les outils et les ressources du Big Data et de la science des données d’une manière que nous pensions impossible ».
Transport et logistique
L’« effet Amazon » est un terme qui définit la manière dont Amazon a fait de la livraison en un jour la nouvelle norme, les clients exigeant désormais la même vitesse d’expédition pour tout ce qu’ils commandent en ligne. Le magazine Entrepreneur souligne qu’en raison de l’effet Amazon, « la course logistique au dernier kilomètre ne fera que s’intensifier ». Les entreprises du secteur s’appuient de plus en plus sur l’analyse du Big Data pour optimiser la planification des itinéraires, la consolidation des charges et les mesures d’efficacité énergétique.
Éducation
Depuis l’apparition de la pandémie, les établissements d’enseignement du monde entier ont dû réinventer leurs programmes d’études et leurs méthodes d’enseignement afin de faciliter l’apprentissage à distance. L’un des principaux défis a été de trouver des moyens fiables d’analyser et d’évaluer la performance des étudiants et l’efficacité globale des méthodes d’enseignement en ligne. Un article paru en 2020 au sujet de l’impact du Big Data sur la formation et l’apprentissage en ligne indique, au sujet des enseignants, que « le Big Data les aide à gagner en confiance pour personnaliser l’enseignement, développer l’apprentissage mixte, transformer les systèmes d’évaluation et promouvoir l’apprentissage continu ».
Énergie et services publics
Selon le U.S. Bureau of Labor Statistics, le service public consacre plus de 1,4 milliard de dollars aux relevés de compteurs et s’appuie généralement sur des compteurs analogiques et des lectures manuelles peu fréquentes. Les relevés de compteurs intelligents fournissent des données numériques plusieurs fois par jour et, grâce à l’analyse du Big Data, ces informations permettent d’accroître l’efficacité de la consommation énergétique, ainsi que la précision des prix et des prévisions. En outre, lorsque les agents n’ont plus à se charger des relevés de compteurs, la saisie et l’analyse des données peuvent permettre de les réaffecter plus rapidement là où les réparations et les mises à niveau sont les plus urgentes.
https://ankaa-pmo.com/wp-content/uploads/2017/04/Logo-Ankaa-engineering.png00Service comm.https://ankaa-pmo.com/wp-content/uploads/2017/04/Logo-Ankaa-engineering.pngService comm.2021-04-15 12:39:522021-04-15 12:39:52Qu’est-ce que le Big Data ?
Have you ever wondered why we’re so amazed by motion? A moving image is more likely to grab your attention than a static one. Motion is exciting and attention-grabbing – plus, it allows us to access more information in a short space of time.
For a while now, companies have been experimenting with all kinds of motion and animation in their design choices. We’ve seen the rise of animated website backgrounds or live-playing videos instead of images on a home page. There are videos and 360-degree pictures on product pages to help people get a better view of certain items and immersive AR experiences on apps.
So why has the power of motion not made its way into the logo design landscape yet?
Sure, there are a few examples of animated logos out there, but they haven’t had the same long-lasting impact as animated websites. Perhaps that’s because people don’t have the right tools to bring their animated logos to life?
Today, we’re going to cover some top tips for live logo design.
1. Understand What “Live Logo” Means
An animated logo or live logo can be a powerful tool in a company’s branding strategy. Although there’s more to a company’s identity than its logo, it’s fair to say that logos make a huge difference to how we feel about brands and their identity.
A powerful logo can make an emotional connection with your target audience and help your brand to thrive in virtually any environment. Live logos, or animated logos, bring more attention to the brand image, by helping a customer to focus on the logo’s action. A live logo might tell a story about what the business does through motion, or just be eye-catching.
The level of animation varies depending on the designer, but it can go all the way from a short video presentation to a few simple moves. The Skype logo is an excellent example of something simple, that multiple designers have played with to great effect.
Today, there are plenty of open-access tools helping to create more immersive animated graphics in the logo design world. Additionally, the types of animation available are becoming more impressive all the time.
2. Explore the Types of Logo Animation
The next stage of properly leveraged live logos, is knowing what kinds of logo animation are available. There are plenty of different styles of animation to explore today, depending on the kind of impact you want to have.
For instance, sometimes the animation you choose will be connected to your business. A vehicle company might have a logo that seems to “drive” into the central space on the screen. An electricity company might choose a logo that pulses like an electric charge. This animated FedEx logo is an excellent example of how animation can show what a business does.
Options for animation might include:
Rotation: Make an emblem stand out by moving it to the sides or allowing it to move on its axis. Rotation gives a logo a sense of 3D space.
Appearance/Disappearance: You can make a logo grow on the screen by bringing to life one pixel at a time, or have it dissolve and disappear in a similar way.
Transformation: Your logo doesn’t have to start out in the shape it’s going to achieve. You might start with a seed that gradually grows into a tree-shaped logo for a gardening company, for example.
Replacement: Another great way to tell a story is to replace a graphic related to the company in question with the logo through an immersive animated experience.
3. Set Goals for the Live Logo
If you’re not sure what kind of animations to experiment with, then it’s a good idea to start with some solid goals. Your goals will give you a direction to move in with your logo choices. An animated logo can be a dynamic and modern way to present a brand to an audience, but it’s only going to be effective when implemented carefully.
Let’s look at some of the goals you can choose for your live logo:
Differentiation: While it’s true that animation and live content is gaining more attention lately, it’s still relatively new as an overall concept. With an animated logo, you could help a brand to create a more unique image for themselves, which sets them apart from the other organisations in the same space.
Storytelling: As mentioned above, animated logos can tell a story about what the company or product actually does. In this example for Firefox, for instance, the logo mimics a loading wheel to demonstrate a speedy internet browser.
Brand awareness: Dynamic logos and animations are more likely to capture your audience’s attention than static images. They’re also more of a novel experience, which means that customers might want to share them with other people too.
Memorability: Today’s customers are bombarded by hundreds, if not thousands of logos all the time. They need something special to convince them that one image deserves a spot at the front of their mind. Animation can help to make a business more memorable.
4. Do Your Research
Doing your own research is an excellent way to get some inspiration for a live logo or animation. Ideally, you’ll want to focus on the industry you’re already working in, as this will give you some guidance as to the kind of movement that can attract the most attention from the correct audience.
Watch as intros to brand videos and check out as many live logos as you can. Check out the kind of animations that people use in their videos when they’re showcasing products online. You can learn a lot about what works just by evaluating what other people have done before. Just be careful not to simply copy what you’ve found elsewhere.
The aim of your live animation should be to tell a unique story about the company
The aim of your live animation should be to tell a unique story about the company in question. If you’re not sure how to start with differentiating the image, check out the brand guidelines for the company in question. The guidelines that the company used to choose the right brand colors, fonts, and other visual assets can work just as well for your animation strategy.
Remember, the aim here is to tell a specific story, send a message, or evoke a certain emotion. Don’t make the mistake of designing something that looks cool but doesn’t have much of a purchase. Most human beings will naturally look for the meaning behind the content that they see. If there isn’t anything there, it’ll just lead to confusion.
5. Use Live Logos on Brand Websites
The most obvious way to begin experimenting with animated logos in web design, is to implement live logos into a client’s website. Some companies have a “welcome screen” for their site which uses an animation to introduce visitors to the home page and other navigation options. There are also brands out there who love the impact that animation can have but want to use it more subtly.
In these cases, live logos can be an excellent way to draw the eye to a specific spot on a website, perhaps the area just above the “contact” button that encourages a client to reach out. Crucially, to avoid weighing down the website and distracting visitors, companies and designers will need to make some important choices.
Although it might be tempting to keep the animation looping at all times, just in case someone misses the first round, this requires a lot of extra processing power. Too much animation also makes it harder for businesses to push the focus of their visitors to other points on the website, like landing pages for products, or testimonial pages.
Often, as with most innovative decisions in web-design, the best bet is usually to start small and work your way up. Don’t over-do it with animation on day one. See how the visitors to the website respond first.
6. Find the Right Balance
Animations in a live logo are there to grab attention quickly, and effectively. They shouldn’t go on for too long, or you risk overwhelming your audience before they have a chance to browse the rest of the website or check out other content. A live logo should only be active for a few seconds at most, and in that time, it needs to say something valuable.
Often, the best strategy is to start by building up curiosity, and getting your viewer engaged so that they’re keen to see more. Every frame will count to pull the customer in and make them feel connected to the brand in question.
Make sure that the logo animation is dynamic so that it doesn’t just capture the attention of the viewer but maintain their interest for the full time required. During the motion, the viewer’s brain should be working to figure out what’s going to happen next.
Just like most logo design and graphic animation strategies, the key to success is finding the right balance between clever experiences, and simplicity. You want to do something meaningful that earns your viewer’s attention, but you need to compete with the fact that attention spans are plummeting all the time.
7. Explore Logo Animation in Video
One of the best ways to use logo animation, is to draw interest for a company at the beginning of a video. Video is gaining incredible levels of popularity lately, particularly in a world where you can view video content almost anywhere. Companies are adding videos to their product pages, social media accounts, applications, websites, and so much more .
For the majority of companies, a live logo at the start of a video can help their brand to seem more professional. It’s a reminder to viewers of the brand that they’re learning about with that video content. Plus, a logo at the beginning of a piece of video content can also build on the consistency that companies attempt to create by using the same brand assets in various mediums online.
(Starting a video with an animated logo is great for presentation, but it can also be frustrating to customers in certain pieces of content where they’re looking for quick answers to questions. If an animated logo is more than a couple of seconds long, it may be better placed at the back of a video instead.)
With videos for news reports or announcements where you want to get straight to the point and generate excitement about a new product or service, it can be better to jump straight into action. Ending a video with a live logo keeps the brand image front of mind for the customer for longer, even after the message has ended. On the other hand, ending a video with a logo could increase the chances that customers miss the animation, because they click away from the content too quickly.
If you’re new to adding live logos into videos, consider experimenting with different strategies to see which works best. Different companies might get unique results.
8. Bring Logo Animation to the Real World
Another interesting option for live logo design, could be to step outside of the computer screen for a while. In today’s digitally transforming landscape, it’s becoming more common to see the real and digital worlds converging. Most events and trade-shows come with presentations that rely on digital content, like animated presentations and slide shows.
Depending on the signage solutions available at industry events, companies could even use an animated logo above their booth to draw attention in a cluttered environment. Around 48% of exhibitors agree that a more eye-catching stand or booth is often the most effective way to attract visitors and customers at an event.
Animation and live logos may have started life on the computer screen, but they can appear in much more diverse environments today. Offices could use a live logo in the reception room or lobby to make their on-premises environment more appealing. Retail locations could display ads on digital signage, followed by live logos that work to both separate messages, and keep shoppers entertained when they’re enjoying the bricks-and-mortar experience.
9. Include Live Logos in Brand Signatures
Remember, a live logo doesn’t just have to sit on a company’s app or website until someone discovers it. Sometimes, the right logo can also be a powerful way to “sign off” on a message from a brand or its management team. For instance, email remains to be one of the most valuable tools for business marketing and customer relationship building today.
It’s the third most influential source of content and news for a lot of B2B audiences, and yet, most companies aren’t taking full advantage of what their email marketing software solutions are capable of. If you can display gifs and animated videos in an email (which most software solutions can), then you can also add a live logo to the brand signature.
The important thing to remember is that if you’re going to be adding a signature to a lightweight thing, like an email, it needs to be lightweight too. Don’t make the live logo too long and complicated, or it might prevent the email from loading properly.
Outside of email, don’t forget to consider options for live logos in things like social media profile pictures too. According to experts, around 80% of companies use visual assets in their social media marketing. A live logo is a great way to go beyond the basics with a company’s imagery. Motion grabs attention, and video content is quickly gaining steam on a lot of social media platforms.
Embracing a New World of Live Animation
Designers are only just beginning to scratch the surface of what’s possible with animated logos. For many companies, live logos are an excellent way to capture audience attention and encourage engagement with a brand.
A live logo at the beginning of a video, at the start of an app loading screen, or even at the top of a website can differentiate a company and make them stand out. As technology continues to evolve, and customer expectations continue to expand, the options for live animation could continue to grow. You might even be able to infuse live logos with elements of VR and AR, to impart brand essence in a brand-new digital world.
If you haven’t begun experimenting with live logo design yet, now could be the time to start.
https://ankaa-pmo.com/wp-content/uploads/2021/04/9-tips-for-better-live-logo-design.png15292780Service comm.https://ankaa-pmo.com/wp-content/uploads/2017/04/Logo-Ankaa-engineering.pngService comm.2021-04-14 16:45:092021-04-14 16:45:099 Tips for Better Live Logo Design
Paramètres des cookies et politique de confidentialité
Comment nous utilisons les cookies
Nous utilisons les cookies pour nous faire savoir quand vous visitez nos sites Web, comment vous interagissez avec nous, pour enrichir votre expérience utilisateur et pour personnaliser votre relation avec notre site Web.
Cliquez sur les différents titres de catégories pour en savoir plus. Vous pouvez également modifier certaines de vos préférences. Notez que le blocage de certains types de cookies peut avoir un impact sur votre expérience sur nos sites Web et les services que nous sommes en mesure d'offrir.
Cookies essentiels sur ce site
These cookies are strictly necessary to provide you with services available through our website and to use some of its features.
Because these cookies are strictly necessary to deliver the website, you cannot refuse them without impacting how our site functions. You can block or delete them by changing your browser settings and force blocking all cookies on this website.
Cookies Google Analytics
Ces cookies recueillent des renseignements qui sont utilisés sous forme agrégée pour nous aider à comprendre comment notre site Web est utilisé ou l'efficacité de nos campagnes de marketing, ou pour nous aider à personnaliser notre site Web et notre application pour vous afin d'améliorer votre expérience.
Si vous ne voulez pas que nous suivions votre visite sur notre site, vous pouvez désactiver le suivi dans votre navigateur ici :
Autres services
Nous utilisons également différents services externes comme Google Webfonts, Google Maps et les fournisseurs externes de vidéo. Comme ces fournisseurs peuvent collecter des données personnelles comme votre adresse IP, nous vous permettons de les bloquer ici. Veuillez noter que cela pourrait réduire considérablement la fonctionnalité et l'apparence de notre site. Les changements prendront effet une fois que vous aurez rechargé la page.
.
Paramètres de Google Webfont Settings :
Google Map :
Vimeo et Youtube :
Politique de confidentialité
Vous pouvez lire nos cookies et nos paramètres de confidentialité en détail sur la page suivante


 Ten years ago, people began talking about the “Independent Web.” Although we don’t commonly use the term anymore, that doesn’t mean that it’s not still as vital a topic of discussion today as it was a decade ago.
Ten years ago, people began talking about the “Independent Web.” Although we don’t commonly use the term anymore, that doesn’t mean that it’s not still as vital a topic of discussion today as it was a decade ago.
 Rather than spring cleaning, do some spring “shopping” for tools that will make your design life easier. Packed with free options this month, this list is crammed full of tools and elements that you can use in your work every day.
Rather than spring cleaning, do some spring “shopping” for tools that will make your design life easier. Packed with free options this month, this list is crammed full of tools and elements that you can use in your work every day.














 Every day design fans submit incredible industry stories to our sister-site,
Every day design fans submit incredible industry stories to our sister-site, 












 Over the last fortnight one site builder has gone toe-to-toe with another, as Wix launched a marketing campaign aimed at attracting WordPress users, and instead attracted universal ire.
Over the last fortnight one site builder has gone toe-to-toe with another, as Wix launched a marketing campaign aimed at attracting WordPress users, and instead attracted universal ire.

 We’re no longer arguing about whether climate change exists because climate change is now extensively documented. Instead, we’re arguing over whether climate change is a natural cycle or human-accelerated.
We’re no longer arguing about whether climate change exists because climate change is now extensively documented. Instead, we’re arguing over whether climate change is a natural cycle or human-accelerated.