Choosing to work for free, pro bono, gratis, without charge is something that most of us find ourselves doing at one time or another. Whether we’re filling a hole in our portfolio, there’s a friend or relative we feel beholden to, or because there’s an opportunity to aid a cause we value.
Choosing to work for free, pro bono, gratis, without charge is something that most of us find ourselves doing at one time or another. Whether we’re filling a hole in our portfolio, there’s a friend or relative we feel beholden to, or because there’s an opportunity to aid a cause we value.
Recently, I agreed to take on some work, free of charge, for a charity whose goals I share. Because it’s a cause I believe in, I enjoyed the idea of being able to contribute in a more meaningful way than donating money. But my initial goodwill rapidly diminished as the project spiraled out of control, leaving me resenting the time I spent on it.
No one should feel obliged to give away their time for free, but if you do choose to, there are rules you can apply to ensure that everything runs smoothly and you’re left with a positive experience.
1. Be Specific in What You’re Donating
The most obvious problem with working pro bono is that there is no correlation between cost and value.
Budget reins in project ambitions in a regular designer-client relationship; the more you ask for, the more it costs. Everyone encounters clients who want an ecommerce store “just like Amazon,” only to then rapidly downscale their plans when the actual development cost of a site on that scale is made clear.
working pro bono…there is no correlation between cost and value
But when there is no development budget, ambitions quickly escalate. Clients do not necessarily understand the work involved, and if they’re not footing the bill, there’s no incentive to learn.
As the professional, you need to guide them. Set limits on what you’re expecting to donate, and use that to frame what is reasonably achievable.
“I’m donating 40 hours of my time, which normally costs $3000.” Or, “I’m donating my SEO package, which is enough to meet your initial goals as discussed.” They are both perfectly fine.
The purpose is not to highlight your generosity; it’s to establish clear boundaries to prevent scope creep.
2. They’re Not Doing You a Favour
Any client who suggests that their project will be good for your portfolio or gain you “exposure” knows they’re underpaying you. When you hear it from a pro bono client, walk away immediately.
The client needs to understand you are donating your expertise, not because you need to, not because you’re expecting something in return, but because you’re an awesome human being who wants to make the world a little better.
A client who thinks you’re getting something out of the arrangement does not understand your commercial value and will treat you as a novice. Your evidence will become guesses, your decisions will become suggestions, and the client will have little faith in the project outcome.
Clients, whether paying or not, need guidance. If they don’t respect you and believe in your guidance, they will start to cast around for other opinions to the detriment of the project outcome and your relationship.
This brings us neatly on to…
3. Everyone’s an Expert
Q. What’s the difference between an amateur and a professional? A. Professionals get paid.
You’re not getting paid, so in the client’s eyes, you’re now an amateur. Hey, guess what? Their 12-year-old daughter is an amateur too, and her views are now equally valid.
When you’re working pro bono, you can expect a lot of “help.” You’ll find that someone’s niece is planning to major in graphic design…when she graduates high school…in four years. You’ll find that someone’s partner has a hiking blog, read an SEO article, and is happy to “give it a try.” You may even find that the client themselves fancies a career switch to web design and doesn’t think it looks too hard.
Shut that **** down immediately. Smile, be gracious. Explain that, of course, you’re happy for contributions, and then avoid them like the coronavirus.
You’re donating a professional service that you’ve spent years developing, and you’re donating it to a cause that you value. You’re not there to increase someone’s chance of getting into college or to distract someone from their boring day job. If you do want to mentor people, there are places you can do that.
Everyone Actually Is An Expert
The nature of pro bono work is that more often than not, the people involved actually are experts. The simple truth is that people who aren’t experts in something tend to be in low-paying employment and are too busy trying not to be in low-paying employment to donate their time.
Like you, the people volunteering their time are doing so because they can afford to. For example, you may find that the organization’s head of accounts spends Monday–Friday as a tax advisor; the head of outreach is a project manager at a construction firm; the head of safeguarding is a school teacher.
People bring transferable skills to pro bono roles. Be sensitive to the fact that just as you are an expert in your professional context, so may they be. Simply not being an expert in design does not make them an idiot.
4. Do Not Foot the Bill
It’s tempting to simply donate everything to do with the project: the domain name’s going to cost $10? Well, it’s only $10; hosting’s $5/month? Well, it’s not too arduous to set up a small space on your own server.
imparting your experience sets the organization up for future success
However, when you give everything away, the client doesn’t understand the cost or value they’re receiving. As a professional, it’s part of your job to educate the client on the costs of a project like this; imparting your experience sets the organization up for future success.
Be clear at the start of the project that the client will be responsible for all expenses.
If you wish to — and you should not feel obliged — you are always free to make a financial donation equivalent to the expenses.
5. Stick to Office Hours
When you agree to do pro bono design work, the chances are that you know the person or organization you’re doing the work for. There’s almost always a personal connection of some kind, which means that the person or organization doesn’t see you in the professional context that normal clients see.
All good clients will respect the fact that you don’t answer emails on a Sunday morning. Not so the charity client. Not only will the charity client assume that you’re available outside of office hours, they may even think they are doing you a favor by not disturbing you during your regular office hours.
It’s important that you find some downtime outside of work to live your life. If you don’t want your evening out with friends to descend into an impromptu planning meeting (you don’t), set clear boundaries about when and how you’re prepared to work on the project.
Unless you’re self-employed, you can’t donate time when you should be working; what you can do is append pro bono work to your paid employment — do an hour after work, on weekday evenings, for example.
If you are literally doing this in your spare time, then allocate a specific time slot, such as a Saturday afternoon, and stick to it.
7. Stick to the Plan, and the Deadline
It is a universal truth that projects run better when there’s a structured approach. It doesn’t matter if it’s lean, agile, waterfall, or whatever you want to dub it. What matters is that you have a plan that works for you and is suitable for the project goals.
A structured approach, especially one that includes a timeline, will combat most disruptions. On the project I was working on recently, I was preparing for final sign-off when one volunteer announced it was time to “start thinking about what pages we need on the site.” 
Discipline is crucial in pro bono work because different stakeholders will have different levels of commitment; some people will be full-time volunteers, others will be donating an hour per week. What matters is that the project that you are responsible for runs on your schedule.
8. You Have Zero Availability
Non-profits tend to talk to one another. When your friends and family see what you’ve done for Joe’s startup, they will start having ideas of their own. The client you’re completed the project for will have other projects lined up. When you aren’t charging, there’s no shortage of clients.
be prepared to say, “no,” at some point
Before you agree to do any pro bono work at all, be prepared to say “no,” at some point.
The simplest way out is to say you have zero availability: you’re already booked up with paying work, or your boss has let you know she needs you for overtime next month.
Don’t feel bad about it. It’s probably true. There are only so many hours in the day, and even if you do have some time to spare, doesn’t your partner, dog, or social life deserve some attention?
There’s No Profit In Non-Profits
Working for free is not transactional. It probably won’t benefit your portfolio. It definitely won’t lead to paying work. Any skills or experience you acquire probably won’t be transferable. (It might give you the topic for a blog post.)
If the work were meant to benefit you, it would be called personalis bono.
Nevertheless, many of us will find ourselves agreeing to do pro bono work, either out of obligation or idealism. It’s not something to shy away from; changing the world — whether for a group or an individual — is a noble pursuit.
The key is that while you will not profit, neither should you suffer a loss. Volunteering your time, skills, and experience should be a sustainable process. One that you will not come to regret.
Featured image via Unsplash.
The post How to Work for Free Without Wrecking Your Career first appeared on Webdesigner Depot.

 The world of web design is incredibly dynamic. Every year, new trends and opportunities emerge, primarily driven by the arrival of modern technology.
The world of web design is incredibly dynamic. Every year, new trends and opportunities emerge, primarily driven by the arrival of modern technology. 

 This week, a significant portion of the Web fell over when on Tuesday, sites powered by Fastly were impacted by
This week, a significant portion of the Web fell over when on Tuesday, sites powered by Fastly were impacted by 


 Ten years ago, people began talking about the “Independent Web.” Although we don’t commonly use the term anymore, that doesn’t mean that it’s not still as vital a topic of discussion today as it was a decade ago.
Ten years ago, people began talking about the “Independent Web.” Although we don’t commonly use the term anymore, that doesn’t mean that it’s not still as vital a topic of discussion today as it was a decade ago.

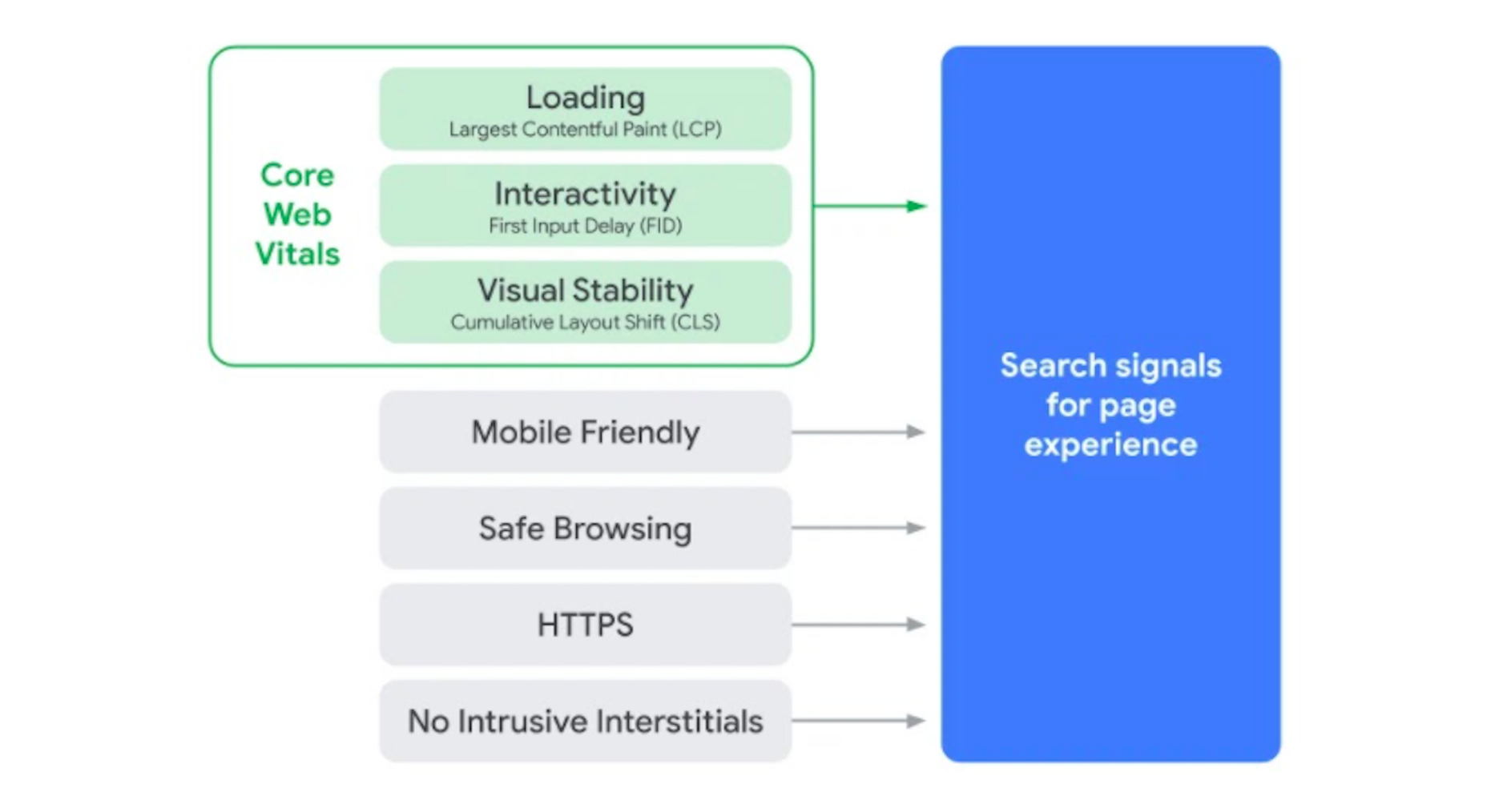
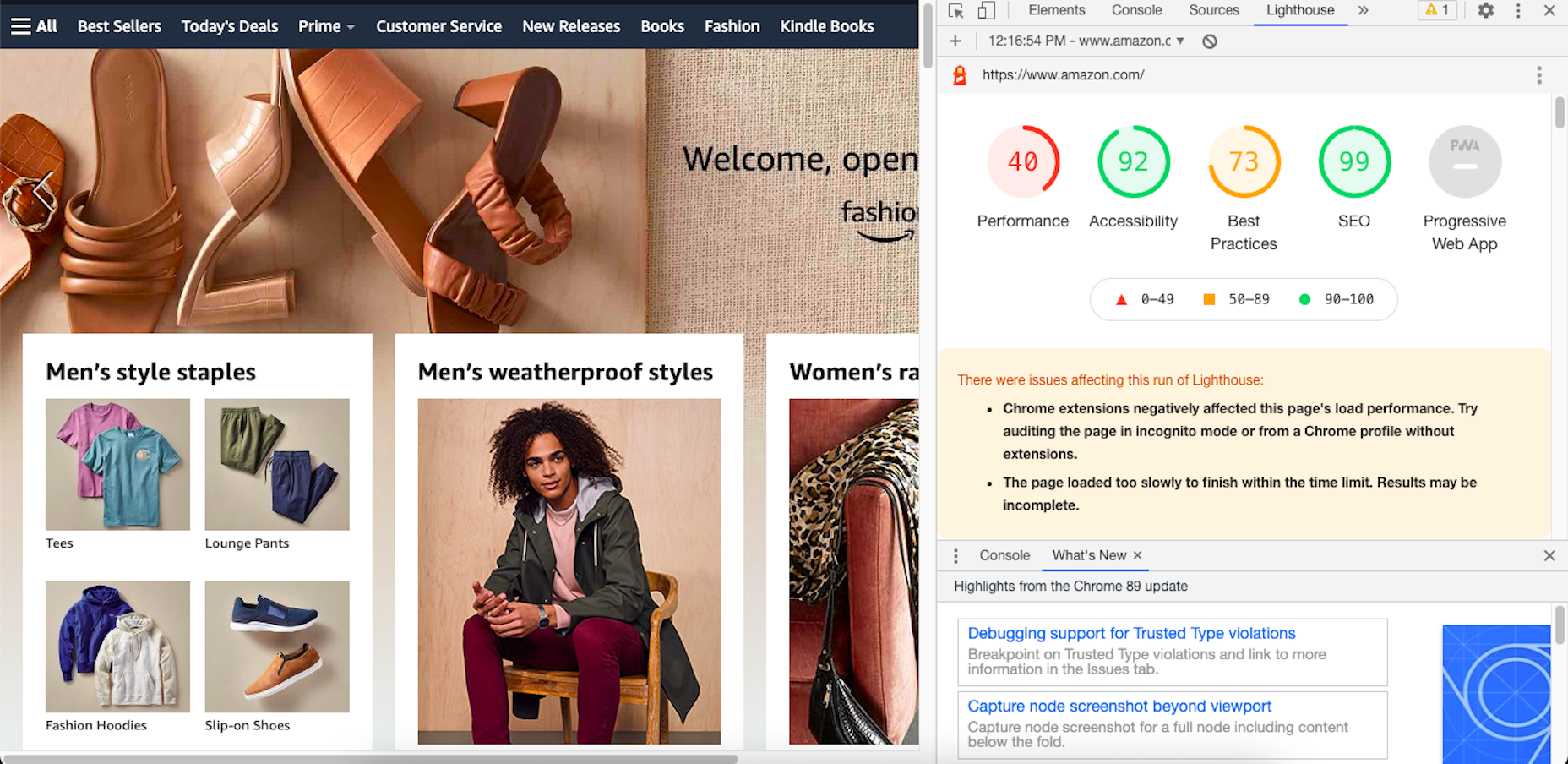
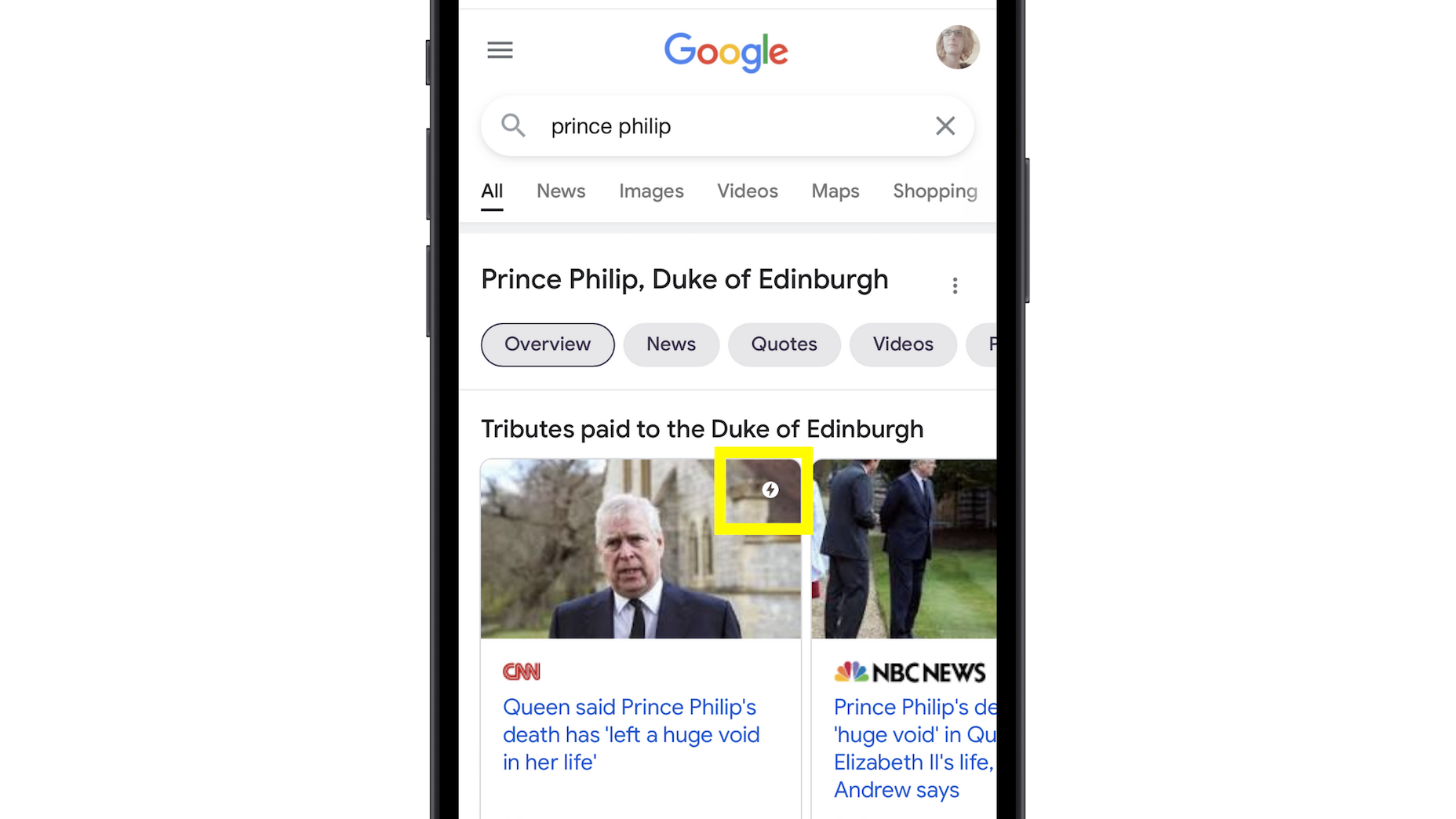
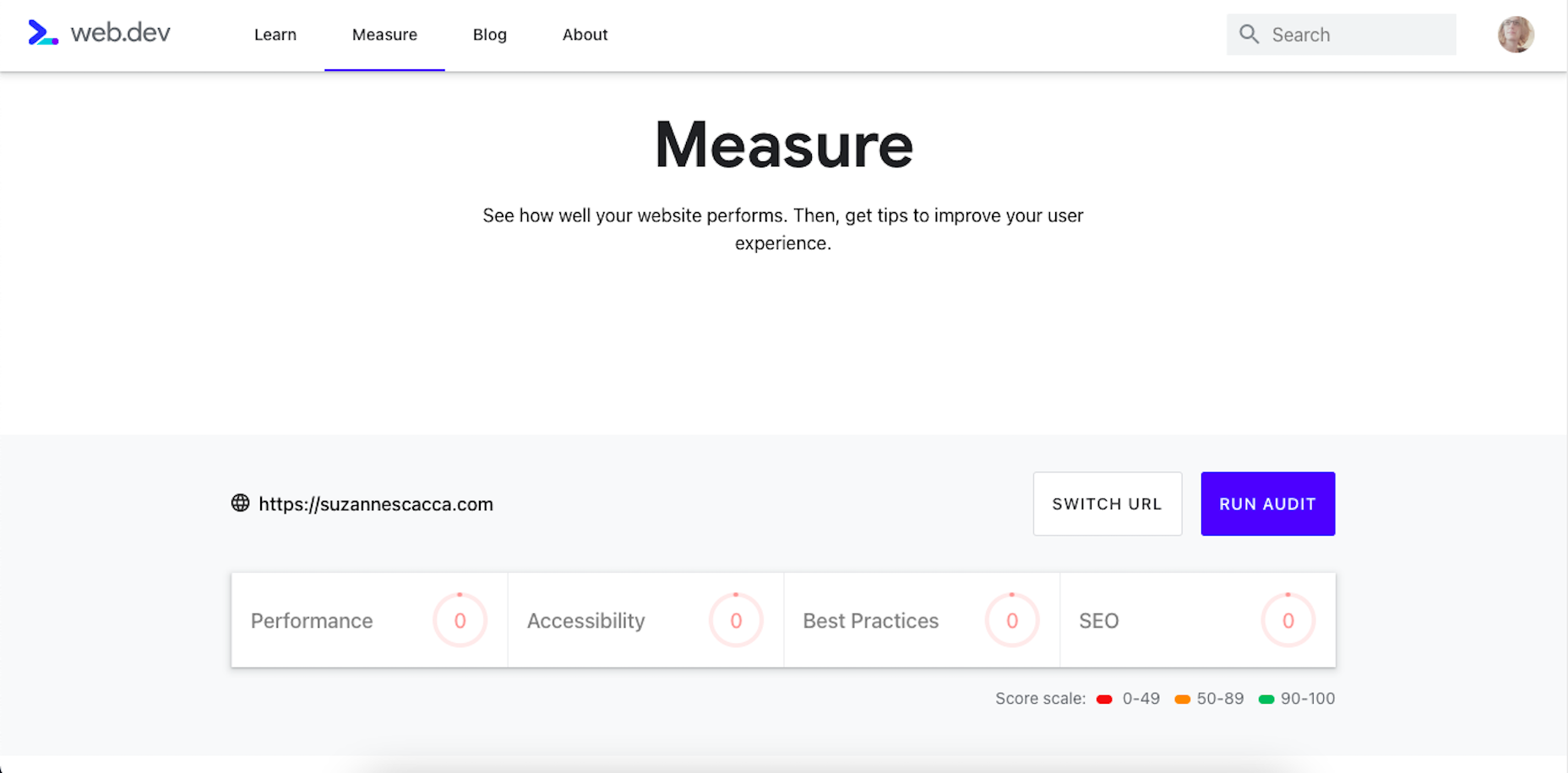
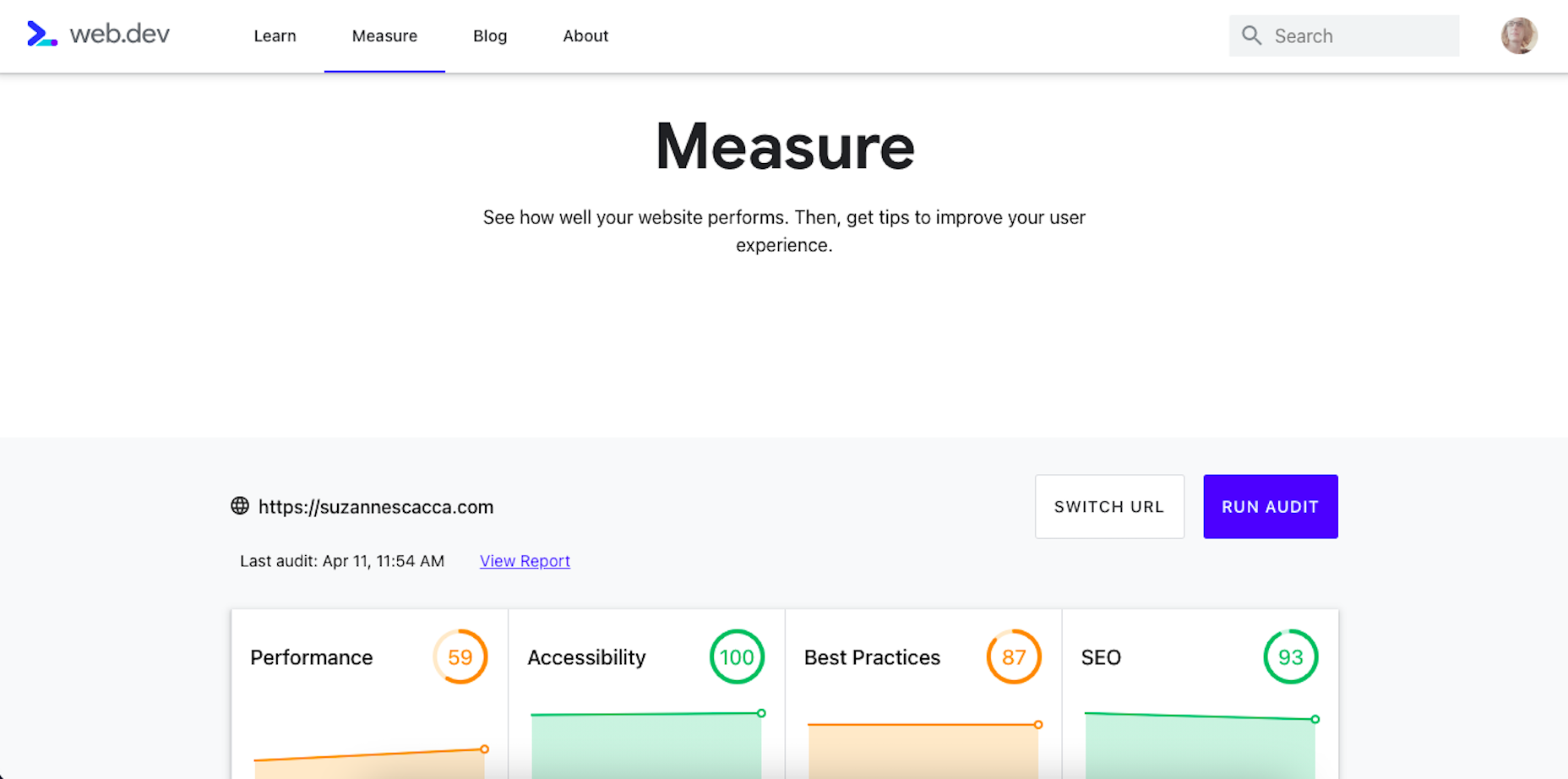
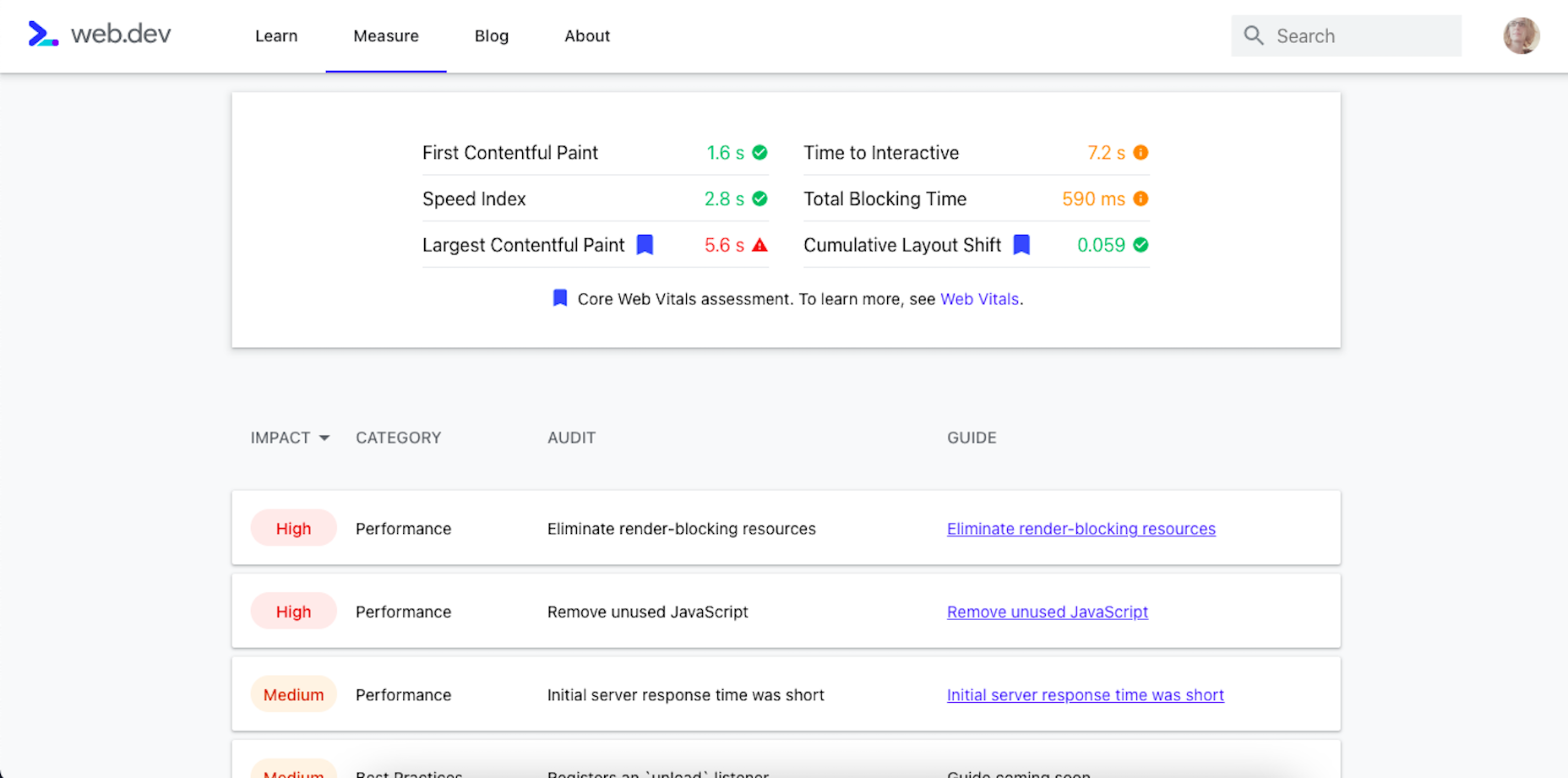
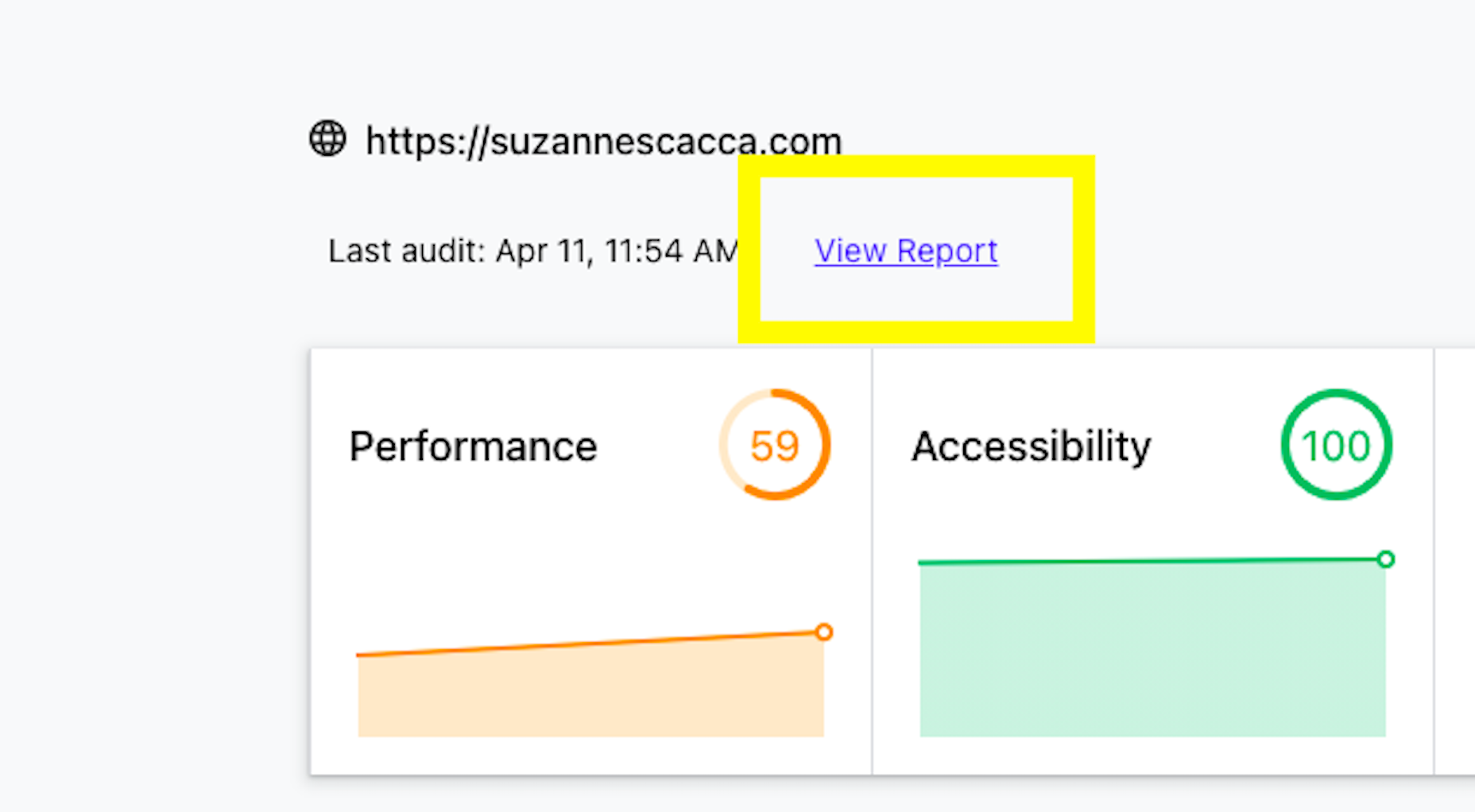
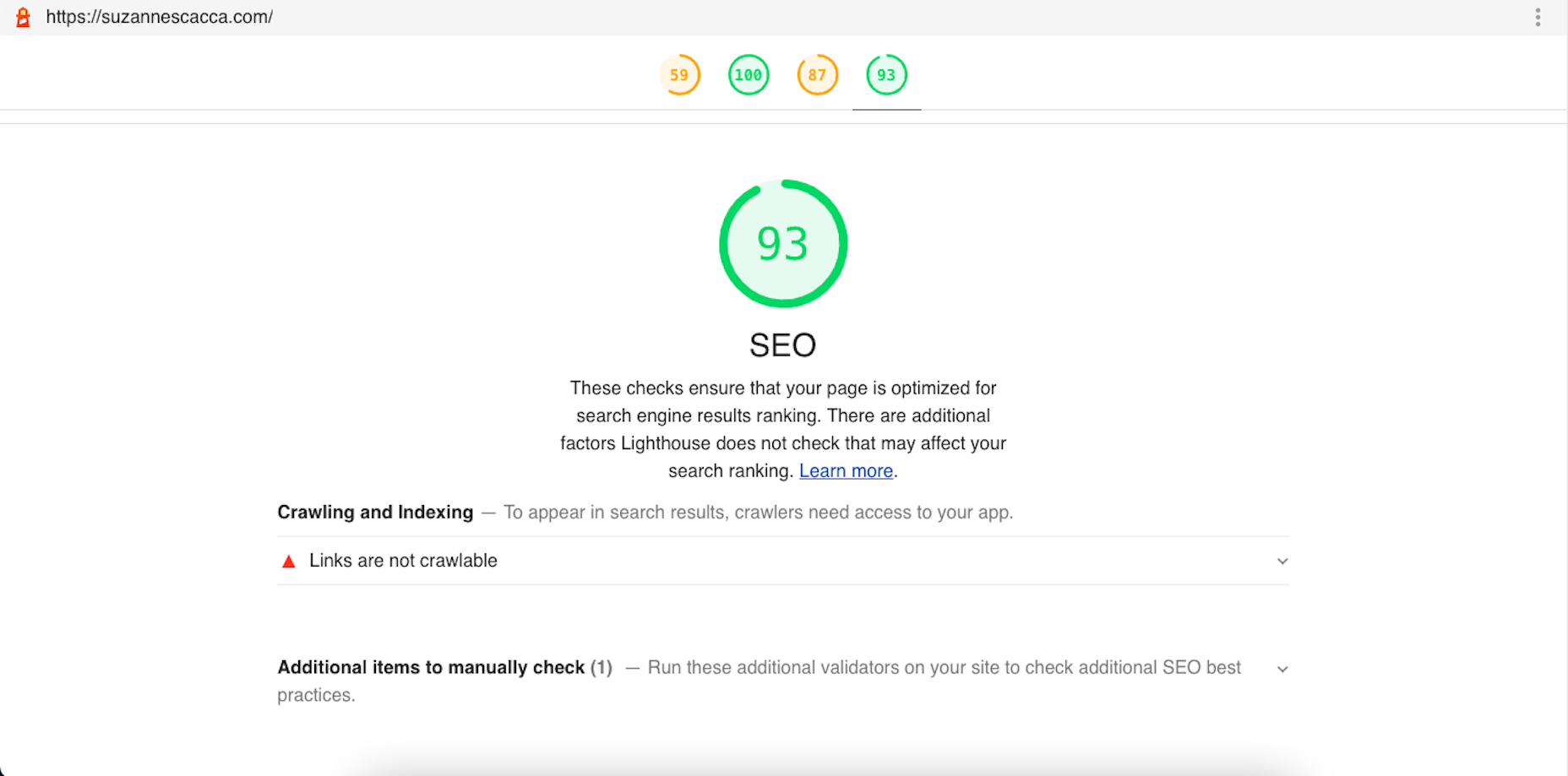
 Google has been talking about the Core Web Vitals tool and the Page Experience Update for about a year now.
Google has been talking about the Core Web Vitals tool and the Page Experience Update for about a year now.