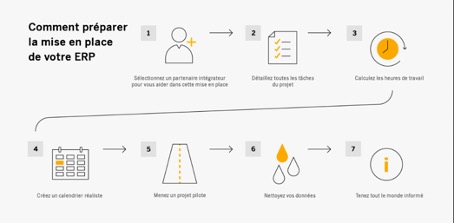
Quand on parle de solutions dans le cloud, ou le ‘nuage’, on évoque principalement l’utilisation de ressources informatiques mises à disposition par le biais d’Internet. Cette technique offre davantage de flexibilité et de rapidité. Elle se révèle également plus économique qu’une installation locale des composants et logiciels. Dans les solutions de Cloud Computing, les clients ne paient que pour les services basés dans le cloud qu’ils utilisent effectivement. En d’autres termes, vous pouvez grâce à cette technologie de pointe réduire vos coûts d’exploitation, faire fonctionner votre infrastructure informatique de manière optimale et efficace, et surtout, la faire évoluer en fonction de vos besoins. Mais au fait : qu’est-ce que le cloud ?
Qu’est-ce que le cloud ?
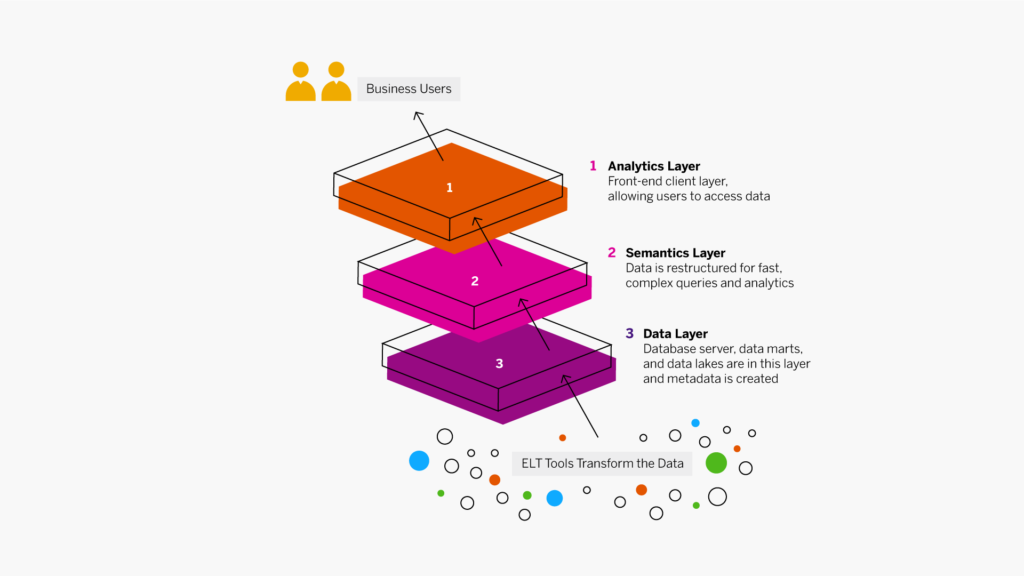
Le cloud, ou nuage en français, renvoie à une nouvelle conception de l’informatique. Les ressources de stockage, les logiciels d’analyse ou les applications sont basés sur Internet. Il s’agit donc de solutions dématérialisées, qui remplacent l’installation sur un réseau d’entreprise, en local. Le cloud constitue une infrastructure virtuelle sur laquelle des ressources accessibles depuis un navigateur ou une application dédiée sont mises à disposition. C’est le fournisseur des solutions de cloud computing qui se charge de la maintenance et de l’entretien de l’architecture sous-jacente.
Le terme ‘cloud’ est apparu dans les années 1990, pour désigner les parties d’une architecture dédiée à l’information et à son échange. On l’utilise couramment pour décrire les domaines informatiques dans lesquels des systèmes numériques comme des
ordinateurs de bureau, des serveurs, les smartphones ou les tablettes échangent des données. L’image du ‘nuage’ s’explique d’une part par le fait que cette architecture demeure pour une grande part voilée pour l’utilisateur, d’autre part par la dimension dématérialisée des ressources. L’histoire du cloud débute à proprement parler en 2006, lorsque Amazon décide de louer des capacités de stockage aux entreprises.
Depuis lors, l’offre croissante de services de cloud computing permet de délocaliser plus aisément à des prestataires externes des questions telles que le stockage des données ou la sécurité informatique. Les systèmes ERP cloud, par exemple, sont moins sensibles aux défaillances qu’un réseau local, dans la mesure où les données sont certes stockées sur un serveur, mais généralement de manière redondante, à plusieurs emplacements, ce qui limite le risque de perte. Les collaborateurs de l’entreprise peuvent alors se connecter par le biais d’Internet au stockage en ligne. Il leur suffit d’un PC, d’une tablette ou d’un smartphone pour accéder aux données dont ils ont besoin. L’accès peut se faire quel que soit l’endroit où ils se trouvent, au bureau, chez eux ou en déplacement.
Solutions de cloud computing : les avantages
Utiliser un ERP cloud présente pour les entreprises de nombreux avantages. Souvent, elles choisissent de passer à une solution cloud pour des raisons de coût. En effet, un ERP cloud permet de réduire l’investissement pour l’achat de matériel et de logiciels ou pour la mise en place de centres de données. De même, l’entreprise n’a pas besoin d’engager un expert en informatique pour gérer l’infrastructure locale, puisque celle-ci se trouve dans le cloud . Installer un centre de données local entraîne de nombreux frais pour une PME. S’y ajoutent des frais de gestion et le temps qu’il faut y consacrer, afin d’appliquer les mises à jour logicielles et de configurer le matériel. L’utilisation de logiciels cloud permet donc aux équipes informatiques en entreprise de se consacrer à d’autres missions et sur la stratégie commerciale.
Le cloud computing est aussi plus rapide que les ressources locales. S’agissant d’offres à la demande, en libre-service, les PME et les ETI peuvent disposer en quelques minutes d’une puissance importante, mise à disposition par le prestataire. Il en résulte une meilleure flexibilité. L’entreprise n’a plus besoin de se soucier de la planification de ses capacités. C’est d’autant plus vrai que les services informatiques en cloud s’appuient sur un réseau puissant de centres de données. Il est régulièrement mis à niveau avec du matériel informatique rapide et efficace. La latence réseau est donc bien plus faible.
Enfin, les solutions de cloud computing offrent des avantages en termes de fiabilité et de sécurité. Le cloud ERP simplifie la protection des données, la restauration en cas de problème et la continuité des activités. Le cloud permet en effet la mise en miroir des données, stockées à plusieurs endroits différents. Concernant la sécurité, c’est le prestataire de solutions cloud qui met à disposition les technologies de pointe. Il effectue également les contrôles indispensables. De cette manière, l’environnement informatique des PME et ETI est mieux sécurisé. Les données sont protégées et les applications résistent mieux aux menaces potentielles.
Les différents types de solutions de cloud computing
L’un des avantages du cloud est, comme nous avons pu le voir, la flexibilité. Selon l’organisation des entreprises, les habitudes de travail et le fonctionnement des équipes, un type donné de cloud computing est plus adapté qu’un autre. Votre prestataire étudie votre cahier des charges et vous propose un ERP basé sur le cloud convenant réellement à vos besoins et à ceux de votre activité. Autrement dit, les solutions de cloud computing sont taillées sur mesure pour les différents utilisateurs.
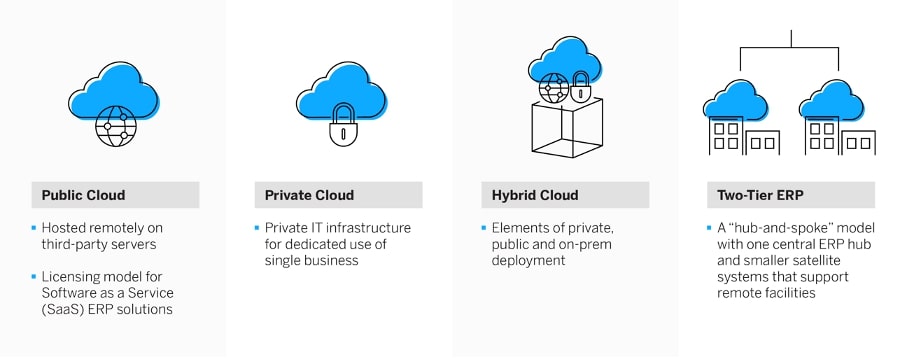
La première différence réside dans l’architecture du cloud sur lequel mettre en œuvre vos ressources. Il existe trois options pour la fourniture de services en cloud : le cloud public, le cloud privé et le cloud hybride. Dans le cas du cloud public, les ressources informatiques comme les serveurs et les supports de stockage se trouvent sur Internet. Le fournisseur donne accès aux logiciels et applications. Dans le cloud privé, à l’inverse, les ressources informatiques sont dédiées à une seule entreprise. Le cloud peut néanmoins être hébergé par un prestataire externe, pour les raisons que nous avons examinées ci-dessus. Enfin, le cloud hybride combine les deux solutions.
Les services et les logiciels cloud, quant à eux, appartiennent aux catégories suivantes :
- IaaS, ou Infrastructure as a service
- Paas, ou Platform as a service
- Saas, ou Software as a service.
Ces catégories peuvent évidemment se combiner pour fournir aux entreprises un service intégralement externalisé dans le cloud.
À quel moment une entreprise devrait-elle avoir recours à un ERP cloud ?
Vous vous demandez si des solutions de cloud computing sont faites pour vous ? Voici quelques éléments de réponse, sachant qu’aujourd’hui, environ un quart des entreprises a recours à un ERP cloud.
La réponse à cette question est relativement simple. L’utilisation du cloud computing apporte un plus indéniable dès lors que les données de l’entreprise doivent être disponibles à partir de plus d’un terminal numérique. Lorsque les collaborateurs de la PME utilisent des terminaux mobiles comme le smartphone ou les tablettes, le recours au cloud s’impose. Le cloud permet, comme nous l’avons vu, l’accès décentralisé aux données. Vos collaborateurs peuvent y accéder de partout, et pas seulement depuis le siège de l’entreprise.
Les solutions en cloud sont intéressantes pour les entreprises qui sont basées sur plusieurs sites différents, d’où elles doivent pouvoir consulter une base de données commune. C’est aussi le cas lorsque l’entreprise connaît une croissance rapide et qu’il lui faut des capacités informatiques supplémentaires. Le cloud est par ailleurs une solution de mobilité par excellence, incontournable à l’heure du télétravail. Grâce au cloud privé, la PME peut évoluer de manière flexible, en fonction de ses besoins en capacité de stockage et de calcul. L’accès aux données est accordé de manière sécurisée uniquement à ceux qui doivent pouvoir s’en servir. Le plus souvent, l’investissement dans une solution de cloud computing est rentabilisé rapidement, en une année environ.
Contrairement à ce qu’on pense souvent, les ERP cloud offrent une sécurité améliorée par rapport à la plupart des solutions locales. Le scepticisme que l’on rencontre parfois à l’égard des solutions en cloud n’est donc en aucun cas justifié. Le cryptage des données, en particulier, peut être mis en œuvre dans le cloud comme sur un serveur local. Il est important que le prestataire fournisse une solution de cryptage adaptée, auquel cas le stockage en cloud ne pose pas de problème particulier. Pour une sécurité optimale, nous vous conseillons évidemment le recours à des solutions de cloud computing dans le cloud privé.
Le cloud pour quelles utilisations ?
Le cloud computing permet de nombreuses utilisations. En voici quelques exemples, parmi les plus intéressants pour les PME / ETI. Le cloud permet tout d’abord de créer des applications et de les faire évoluer. On peut s’en servir aussi bien pour les applications sur ordinateur que pour les applications mobiles. Le cloud est particulièrement adapté aux applications API. Il est non seulement possible de les créer, mais aussi de les tester dans le cloud, de manière optimisée.
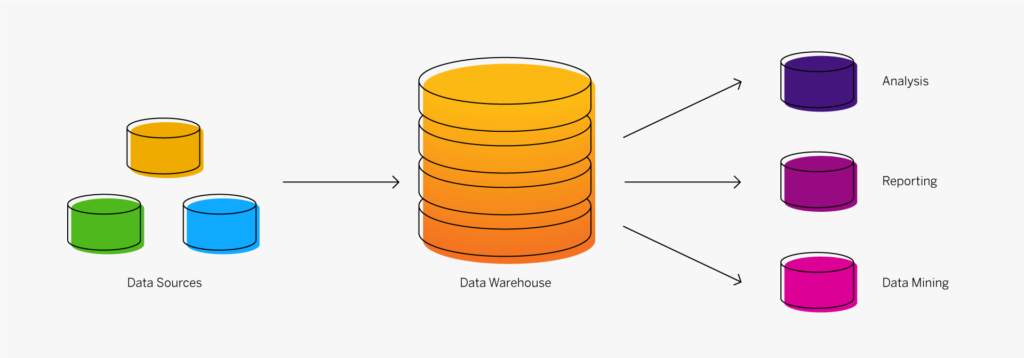
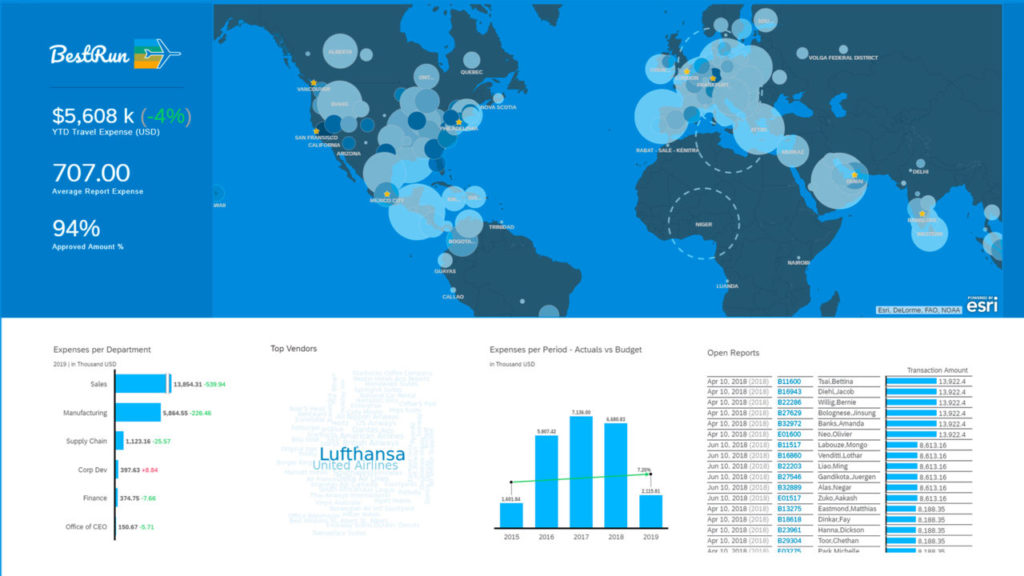
L’utilisation la plus courante est cependant le stockage de données, et leur restauration en cas de problème informatique. Le cloud contribue donc à la protection des données de l’entreprise. Ces données sont accessibles de partout. Il est facile de les analyser, en les partageant entre les membres de vos équipes et les différents services. Les services d’intelligence artificielle basés dans le cloud aident les dirigeants à prendre les meilleures décisions stratégiques.
La puissance des solutions basées dans le cloud vous permettra aussi d’offrir des supports audio et vidéo à vos clients. Ils pourront les consulter depuis n’importe quel emplacement, et sur n’importe quel terminal. Enfin, ce type d’hébergement est aujourd’hui incontournable pour y stocker des logiciels cloud, avec utilisation à la demande, ce qu’on appelle SaaS pour Software as a service.
Choisir les solutions de cloud computing SAP
SAP est spécialisé dans les solutions de cloud computing. Ce sont aujourd’hui plus de 200 millions d’utilisateurs du cloud qui les ont choisies comme support pour leur activité. SAP met en œuvre des technologies intelligentes depuis plus de 40 ans et accompagne les entreprises comme les PME / ETI. Aujourd’hui, SAP est la société de logiciels cloud leader dans le monde. Elle fournit en particulier des ERP cloud pour faciliter l’organisation de travail au quotidien et optimiser les processus de gestion. Tous les outils SAP peuvent être basés dans le cloud et sont conçus dans ce but.
Nous avons développé en particulier différentes solutions pour les PME / ETI afin de les aider à gérer leur trésorerie, leurs stocks, le télétravail, les missions des différents collaborateurs ou encore les opérations financières. Grâce aux solutions SAP, votre entreprise répond de manière plus agile à l’évolution du marché. De plus, elle améliore son indice de satisfaction client. Vous souhaitez en savoir plus sur nos solutions de cloud computing ou nos ERP cloud ?
N’hésitez pas à nous contacter, par téléphone, par courriel ou par le chat. Notre service de support analysera précisément vos besoins et vous orientera vers les solutions les mieux adaptées à votre entreprise.
The post Solution Cloud Computing : maitrisez le Big Data et accélérez l’innovation de votre PME/ETI appeared first on SAP France News.