Les données jouent un rôle clé dans le fonctionnement des entreprises. Il est donc essentiel de leur donner du sens et de déterminer leur pertinence parmi la multitude d’informations générées par les systèmes et technologies qui soutiennent nos économies mondiales hautement connectées. Les données sont omniprésentes, mais inutiles en tant que telles. Pour exploiter toutes les formes de données et les utiliser de manière pratique et efficace dans les chaînes logistiques, les réseaux d’employés, les écosystèmes de clients et de partenaires, etc., les entreprises doivent mettre en œuvre une stratégie, une gouvernance et un modèle de data management performants.
Qu’est-ce que le data management (ou gestion des données) ? Le data management consiste à collecter, organiser et accéder aux données en vue d’améliorer la productivité, l’efficacité et la prise de décision. Compte tenu de l’importance accrue des données, il est essentiel que toute entreprise, indépendamment de sa taille et de son secteur d’activité, mette en place un système moderne et une stratégie efficace de data management.
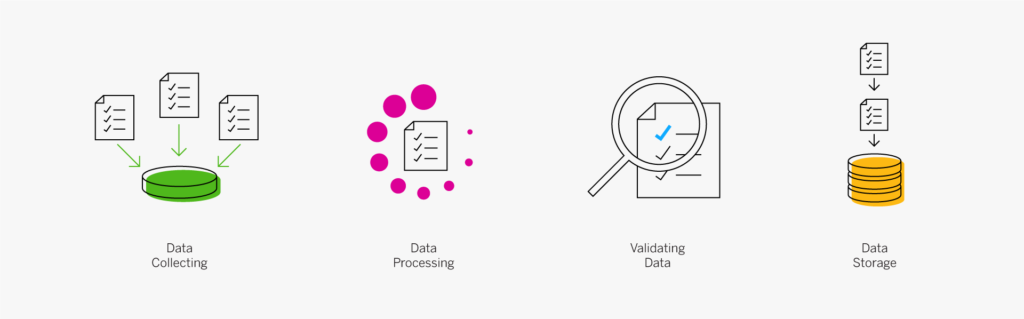
Le processus de data management comprend un large éventail de tâches et de procédures. Par exemple :
- Collecte, traitement, validation et stockage des données
- Intégration de différents types de données émanant de sources disparates, notamment des données structurées et non structurées
- Haute disponibilité des données et restauration après sinistre
- Gestion de l’utilisation des données et de l’accès aux données par les collaborateurs et les applications
- Protection et sécurisation des données en garantissant leur confidentialité
Pourquoi le data management est-il important ?
Les applications, solutions analytiques et algorithmes utilisés dans une entreprise (c’est-à-dire les règles et les processus associés au moyen desquels les ordinateurs résolvent les problèmes et exécutent les tâches) reposent sur un accès transparent aux données. Fondamentalement, un système de data management permet de garantir la sécurité, la disponibilité et l’exactitude des données. Mais ses avantages ne s’arrêtent pas là.
Transformer le Big Data en actif à forte valeur ajoutée
Les données trop volumineuses peuvent être inutiles, voire nuisibles, si elles ne sont pas gérées de manière appropriée. Toutefois, avec les outils adéquats, les entreprises peuvent exploiter le Big Data pour enrichir plus que jamais les renseignements dont elles disposent et améliorer leurs capacités prévisionnelles. Le Big Data peut les aider à mieux comprendre les attentes de leurs clients et à leur offrir une expérience exceptionnelle. L’analyse et l’interprétation du Big Data permet également de mettre en place de nouveaux modèles de gestion axés sur les données, tels que les offres de services basées sur l’Internet des Objets (IoT) en temps réel et les données de capteurs.
163 zettaoctets de données en 2025 (IDC)
80 % des données mondiales seront non structurées en 2025 (IDC)
Les Big Data sont des ensembles de données extrêmement volumineux, souvent caractérisés par les cinq V : le volume de données collectées, la variété des types de données, la vitesse à laquelle les données sont générées, la véracité des données et leur valeur.
Il est bien connu que les entreprises pilotées par les données disposent d’un avantage concurrentiel majeur. En utilisant des outils avancés, les entreprises peuvent gérer des volumes de données plus importants provenant de sources plus diversifiées que jamais. Elles peuvent aussi exploiter des données très variées, structurées et non structurées ou en temps réel, notamment les données des dispositifs IoT, les fichiers audio et vidéo, les données du parcours de navigation sur Internet et les commentaires sur les réseaux sociaux, ce qui leur offre davantage de possibilités de monétiser les données et de les utiliser comme véritable actif.
Créer une infrastructure de données qui favorise la transformation numérique
On dit souvent que les données sont le moteur de la transformation numérique. L’intelligence artificielle (IA), le machine learning, l’Industrie 4.0, les analyses avancées, l’Internet des Objets et l’automatisation intelligente requièrent d’énormes volumes de données ponctuelles, exactes et sécurisées.
L’importance des données et des technologies axées sur les données n’a fait que se renforcer depuis l’apparition de la COVID-19. De nombreuses entreprises ressentent le besoin urgent d’exploiter leurs données de manière plus efficace pour prévoir les événements à venir, réagir rapidement et intégrer la résilience dans leurs plans et modèles de gestion.
Le machine learning, par exemple, requiert des ensembles de données extrêmement volumineux et diversifiés pour « apprendre », identifier des modèles complexes, résoudre les problèmes et assurer la mise à jour et l’exécution efficace des modèles et algorithmes. Les analyses avancées (qui exploitent souvent l’apprentissage automatique) requièrent également de gros volumes de données de haute qualité pour pouvoir générer des informations pertinentes et exploitables qui puissent être utilisées en toute confiance. Quant à l’IoT et l’IoT industriel, ils s’exécutent sur un flux constant de données de machines et capteurs à 1,6 millions de kilomètres par minute.
Les données sont le dénominateur commun de tout projet de transformation numérique. Pour transformer leurs processus, tirer parti des nouvelles technologies et devenir intelligentes, les entreprises doivent disposer d’une infrastructure de données solide. En résumé, d’un système de data management moderne.
« La survie de toute entreprise dépendra d’une architecture agile centrée sur les données, capable de s’adapter au rythme constant du changement. »
Donald Feinberg, vice-président de Gartner
Garantir la conformité aux lois en matière de confidentialité des données
Une gestion appropriée des données est également essentielle pour garantir la conformité aux lois nationales et internationales en matière de confidentialité des données, telles que le Règlement général sur la protection des données (RGPD) et la loi californienne sur la protection de la vie privée des consommateurs (California Consumer Privacy Act ou « CCPA ») aux États-Unis, et répondre aux exigences de confidentialité et de sécurité spécifiques du secteur. En outre, il est essentiel de mettre en place des politiques et procédures solides en matière de data management pour satisfaire aux exigences d’audit.
Systèmes et composants du data management
Les systèmes de data management reposent sur des plates-formes et intègrent une combinaison de composants et processus qui vous aident à tirer profit de vos données. Il peut s’agir de systèmes de gestion de base de données, d’entrepôts de données, de lacs de données, d’outils d’intégration de données, d’outils analytiques, etc.
Systèmes de gestion de base de données (SGBD)
Il existe différents types de systèmes de gestion de base de données. Les systèmes les plus courants sont les systèmes de gestion de base de données relationnelle (SGBDR), les systèmes de gestion de base de données orientée objet (SGBDOO), les bases de données in-memory et les bases de données en colonnes.
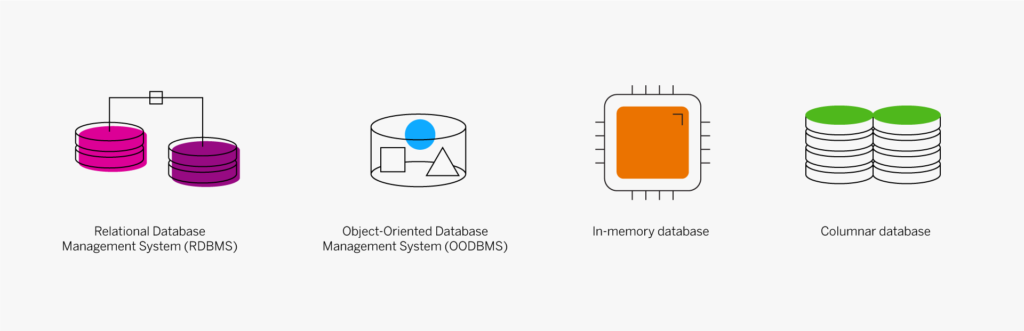
- Système de Gestion de Base de Données Relationnelle (SGBDR) :il s’agit d’un système qui contient des définitions de données permettant aux programmes et aux systèmes d’extraction de référencer les éléments de données par nom, plutôt que de décrire à chaque fois la structure et l’emplacement des données. En fonction du modèle relationnel, le système SGBDR gère également les relations entre les éléments de données qui améliorent l’accès et empêchent les doublons. Par exemple, la définition et les caractéristiques de base d’un élément sont stockées une seule fois et liées aux lignes de détail des commandes clients et aux tables de détermination du prix.
- Système de Gestion de Base de Données Orientée Objet (SGBDOO) :il s’agit d’une approche différente de la définition et du stockage de données, développée et utilisée par les développeurs de systèmes de programmation orientée objet (SPOO). Les données sont stockées en tant qu’objets, entités autonomes et auto-décrites, plutôt que dans des tables à l’image du système SGBDR.
- Base de données in-memory :une base de données in-memory (BDIM) stocke les données dans la mémoire principale (RAM) d’un ordinateur, plutôt que sur un lecteur de disque. L’extraction des données étant beaucoup plus rapide qu’à partir d’un système basé sur disque, les bases de données in-memory sont couramment utilisées par les applications qui exigent des temps de réponse rapides. Par exemple, les données qu’il fallait auparavant compiler dans un rapport sont désormais accessibles et peuvent être analysées en quelques minutes, voire quelques secondes.
- Base de données en colonnes : une base de données en colonnes stocke des groupes de données liées (une « colonne » d’informations) pour y accéder plus rapidement. Cette base de données est utilisée dans les applications de gestion in-memory modernes et dans de nombreuses applications d’entrepôt de données autonomes dans lesquelles la vitesse d’extraction (d’un éventail de données limité) est importante.
Entrepôts et lacs de données
- Entrepôt de données :un entrepôt de données est un référentiel central de données cumulées à partir de différentes sources à des fins de reporting et d’analyse.
- Lac de données :un lac de données est un vaste pool de données stockées dans leur format brut ou naturel. Les lacs de données sont généralement utilisés pour stocker le Big Data, y compris les données structurées, non structurées et semi-structurées.
Gestion des données de base (MDM)
La gestion des données de base est une discipline qui consiste à créer une référence de base fiable (référence unique) de toutes les données de gestion importantes, telles que les données produit, les données client, les données d’actifs, les données financières, etc. Elle garantit que l’entreprise n’utilise pas plusieurs versions potentiellement incohérentes des données dans ses différentes activités, y compris dans les processus, les opérations, l’analyse et le reporting. La consolidation des données, la gouvernance des données et la gestion de la qualité des données constituent les trois piliers clés d’une gestion des données de base efficace.
« Une discipline basée sur la technologie dans laquelle l’entreprise et l’organisation informatique collaborent pour garantir l’uniformité, la précision, l’administration, la cohérence sémantique et la responsabilité des ressources de données de base partagées officielles de l’entreprise. »
Définition de la gestion des données de base par Gartner
Gestion du Big Data
De nouveaux types de bases de données et d’outils ont été développés pour gérer le Big Data : d’énormes volumes de données structurées, non structurées et semi-structurées inondent les entreprises aujourd’hui. Outre les infrastructures basées sur le Cloud et les techniques de traitement hautement efficaces mises en place pour gérer le volume et la vitesse, de nouvelles approches ont vu le jour pour interpréter et gérer la variété de données. Pour que les outils de data management puissent comprendre et utiliser différents types de données non structurées, par exemple, de nouveaux processus de prétraitement permettent d’identifier et de classer les éléments de données en vue de faciliter leur stockage et leur extraction.
Intégration des données
L’intégration des données consiste à intégrer, transformer, combiner et mettre à disposition les données à l’endroit et au moment où les utilisateurs en ont besoin. Cette intégration s’effectue dans l’entreprise et au-delà, chez les partenaires et dans les cas d’utilisation et les sources de données tierces, pour répondre aux besoins de consommation de données de toutes les applications et de tous les processus de gestion. Les techniques utilisées incluent le déplacement des données en masse/par lots, l’extraction, la transformation, le chargement (ETL), la capture des données de modification, la réplication des données, la virtualisation des données, l’intégration des données de streaming, l’orchestration des données, etc.
Gouvernance, sécurité et conformité des données
La gouvernance des données est un ensemble de règles et de responsabilités visant à garantir la disponibilité, la qualité, la conformité et la sécurité des données dans toute l’organisation. Elle définit l’infrastructure et désigne les collaborateurs (ou postes) au sein d’une organisation dotés du pouvoir et de la responsabilité nécessaires pour assurer le traitement et la sauvegarde de types de données spécifiques. La gouvernance des données est un aspect clé de la conformité. Alors que les mécanismes de stockage, de traitement et de sécurité sont gérés par les systèmes, la gouvernance des collaborateurs permet de s’assurer que les données sont exactes, correctement gérées et protégées avant d’être entrées dans les systèmes, lorsqu’elles sont utilisées, puis lorsqu’elles sont extraites des systèmes à d’autres fins d’utilisation et de stockage. La gouvernance détermine comment les responsables utilisent les processus et les technologies pour gérer et protéger les données.
La sécurité des données est bien évidemment une préoccupation majeure dans notre monde actuel constamment menacé par les pirates informatiques, les virus, les cyberattaques et les violations de données. Bien que la sécurité soit intégrée dans les systèmes et les applications, la gouvernance des données garantit que ces systèmes sont correctement configurés et administrés pour protéger les données, et que les procédures et les responsabilités sont appliquées pour assurer leur protection en dehors des systèmes et de la base de données.
Business Intelligence et analyses
La plupart des systèmes de data management, sinon tous, incluent des outils de reporting et d’extraction des données de base, et beaucoup d’entre eux intègrent ou sont fournis avec de puissantes applications d’extraction, d’analyses et de reporting. Les applications d’analyses et de reporting sont également disponibles auprès de développeurs tiers et sont presque toujours incluses dans le groupe d’applications en tant que fonctionnalité standard ou en tant que module complémentaire facultatif pour des fonctionnalités plus avancées.
La puissance des systèmes de data management actuels réside, dans une large mesure, dans les outils d’extraction ad hoc qui permettent aux utilisateurs disposant d’un minimum de formation de créer leurs propres extractions de données à l’écran et d’imprimer des rapports en bénéficiant d’une grande flexibilité dans la mise en forme, les calculs, les tris et les résumés. En outre, les professionnels peuvent utiliser ces outils ou des jeux d’outils d’analyses plus avancés pour aller encore plus loin en termes de calculs, comparaisons, mathématiques abstraites et mises en forme. Les nouvelles applications analytiques permettent de relier les bases de données traditionnelles, les entrepôts de données et les lacs de données pour intégrer le Big Data aux données des applications de gestion en vue d’améliorer les prévisions, les analyses et la planification.
Qu’est-ce qu’une stratégie de gestion des données d’entreprise et quelle est son utilité ?
De nombreuses entreprises se sont montrées passives dans leur approche de stratégie de data management en acceptant ce que leur fournisseur d’applications de gestion avait intégré dans leurs systèmes. Mais cela ne suffit plus. Avec l’explosion actuelle des données et leur importance accrue dans le fonctionnement de toute entreprise, il devient indispensable d’adopter une approche plus proactive et plus globale du data management. D’un point de vue pratique, cela implique de définir une stratégie des données visant à :
- identifier les types de données spécifiques utiles à votre entreprise ;
- attribuer des responsabilités pour chaque type de données ; et
- définir des procédures régissant l’acquisition, la collecte et la gestion de ces données.
La mise en œuvre d’une infrastructure et d’une stratégie de gestion des données d’entreprise offre notamment l’avantage de fédérer l’entreprise, en coordonnant toutes les activités et décisions à l’appui de ses objectifs, à savoir offrir des produits et des services de qualité de manière efficace. Une stratégie globale de data management et une intégration transparente des données permettent de décloisonner les informations. Elles aident chaque service, responsable et employé à mieux comprendre sa contribution individuelle à la réussite de l’entreprise, et à adopter des décisions et des actions alignées sur ces objectifs.
Évolution du data management
La gestion efficace des données joue un rôle clé dans la réussite des entreprises depuis plus de 50 ans : elle permet d’améliorer la précision du reporting, de repérer les tendances et de prendre de meilleures décisions pour favoriser la transformation numérique et exploiter les nouvelles technologies et les nouveaux modèles de gestion. Les données représentent aujourd’hui une nouvelle forme de capital et les organisations visionnaires sont toujours à l’affût de nouveaux moyens de les exploiter à leur avantage. Ces dernières tendances en matière de data management méritent d’être surveillées et peuvent être pertinentes pour votre entreprise et votre secteur d’activité :
- Structure de données : la plupart des entreprises disposent aujourd’hui de différents types de données déployées sur site et dans le Cloud, et utilisent plusieurs systèmes de gestion de bases de données, outils et technologies de traitement. Une structure de données, qui est une combinaison personnalisée d’architecture et de technologie, utilise une intégration et une orchestration dynamiques des données pour permettre un accès et un partage transparents des données dans un environnement distribué.
- Data management dans le Cloud :de nombreuses entreprises se sont mises à migrer tout ou partie de leur plateforme de gestion des données dans le Cloud. Le data management dans le Cloud offre tous les avantages du Cloud, notamment l’évolutivité, la sécurité avancée des données, l’amélioration de l’accès aux données, les sauvegardes automatisées et la restauration après sinistre, les économies de coûts, etc. Les solutions de base de données Cloud et base de données en tant que service (DBaaS), les entrepôts de données Cloud et les lacs de données Cloud montent en puissance.
- Data management augmenté :c’est l’une des dernières tendances. Identifiée par Gartner comme une technologie au potentiel perturbateur d’ici 2022, la gestion des données augmentée exploite l’IA et l’apprentissage automatique pour donner aux processus de gestion la capacité de s’autoconfigurer et s’autorégler. Le data management augmenté automatise tout, de la qualité des données et de la gestion des données de base jusqu’à l’intégration des données, ce qui permet au personnel technique qualifié de se concentrer sur des tâches à plus forte valeur ajoutée.
« D’ici 2022, les tâches manuelles de data management seront réduites de 45 % grâce à l’apprentissage automatique et à la gestion automatisée des niveaux de service. »
– Gartner
- Analyse augmentée : l’analyse augmentée, une autre tendance technologique de pointe identifiée par Gartner, est en train d’émerger. L’analyse augmentée exploite l’intelligence artificielle, l’apprentissage automatique et le traitement du langage naturel (TLN) pour rechercher automatiquement les informations les plus importantes, mais aussi pour démocratiser l’accès aux analyses avancées afin que tous les collaborateurs, et pas uniquement les experts en Big Data, puissent interroger leurs données et obtenir des réponses d’une manière naturelle et conversationnelle.
Découvrez d’autres termes et tendances en matière de data management.
Synthèse
L’information est dérivée des données et si elle synonyme de pouvoir, cela signifie que la gestion et l’exploitation efficaces de vos données pourraient représenter une formidable opportunité de croissance pour votre entreprise. Les responsabilités en matière de data management et le rôle des analystes de bases de données (DBA) évoluent vers un modèle d’agent du changement, qui favorise l’adoption du Cloud, exploite les nouvelles tendances et technologies et apporte une valeur stratégique à l’entreprise.
Solutions de data management et de bases de données
Découvrez comment SAP peut vous aider à gérer, administrer et intégrer vos données d’entreprise pour disposer d’analyses fiables et prendre des décisions avisées.
En savoir plus
Publié en anglais sur insights.sap.com
The post Qu’est-ce que le data management ? appeared first on SAP France News.
Source de l’article sur sap.com


 Rather than spring cleaning, do some spring “shopping” for tools that will make your design life easier. Packed with free options this month, this list is crammed full of tools and elements that you can use in your work every day.
Rather than spring cleaning, do some spring “shopping” for tools that will make your design life easier. Packed with free options this month, this list is crammed full of tools and elements that you can use in your work every day.

















 In our
In our 