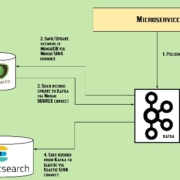
There are multiple ways to ingest data streams into the Apache Kafka topic and subsequently deliver to various types of consumers who are hooked to the topic. The stream of data that collects continuously from the topic by consumers, passes through multiple data pipelines and then stream processing engines like Apache Spark, Apache Flink, Amazon Kinesis, etc and eventually landed upon the real-time applications to deliver a final data-driven decision. From finances, manufacturing, insurance, telecom, healthcare, commerce, and more, real-time applications are becoming the best solution for organizations to take immediate action, gain insights from the updated data. In the present day, Apache Kafka shapes the central nervous system that brings data from all aspects of the business to the large information operational hubs where choices are made.
The text files contain unformatted ASCII text and are commonly used for the storage of information. Each line of the file represents a data record and can be updated continuously to store. Every insert of a new line or lines on the text file can be considered as new data insertion on the file. Henceforth, every addition of a new line or lines on the text file continuously either by humans or applications (no modification on the already inserted line)and subsequently moves or sends to a different location can be considered as data streaming from the file. Every addition of a new line or row in the text file can be analyzed continuously by exporting the new line/lines to the Kafka topic and importing them by consumers that hooks up with the topic.
Source de l’article sur DZONE