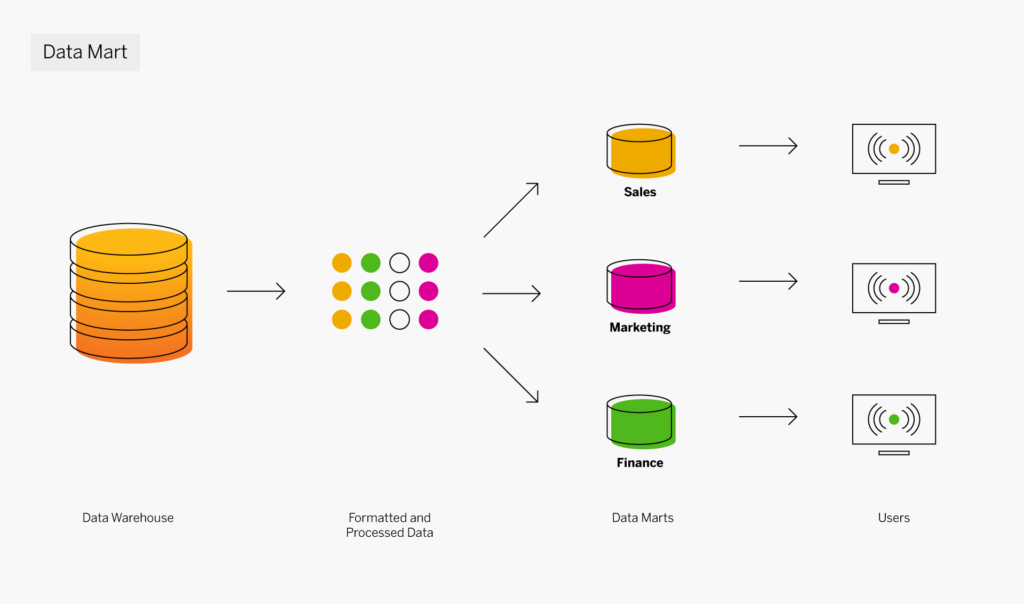
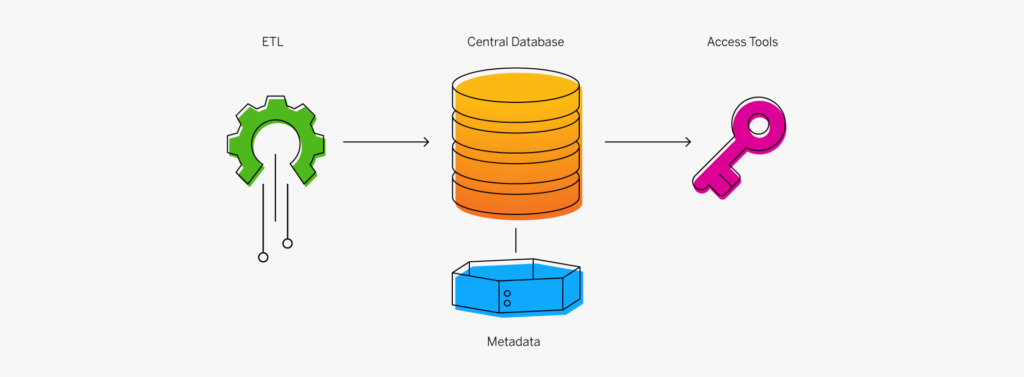
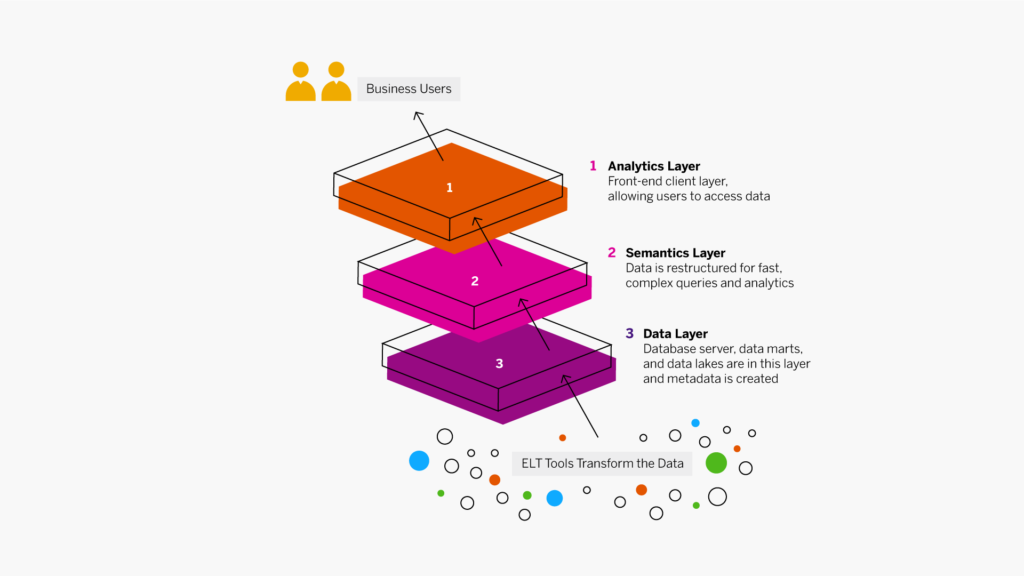
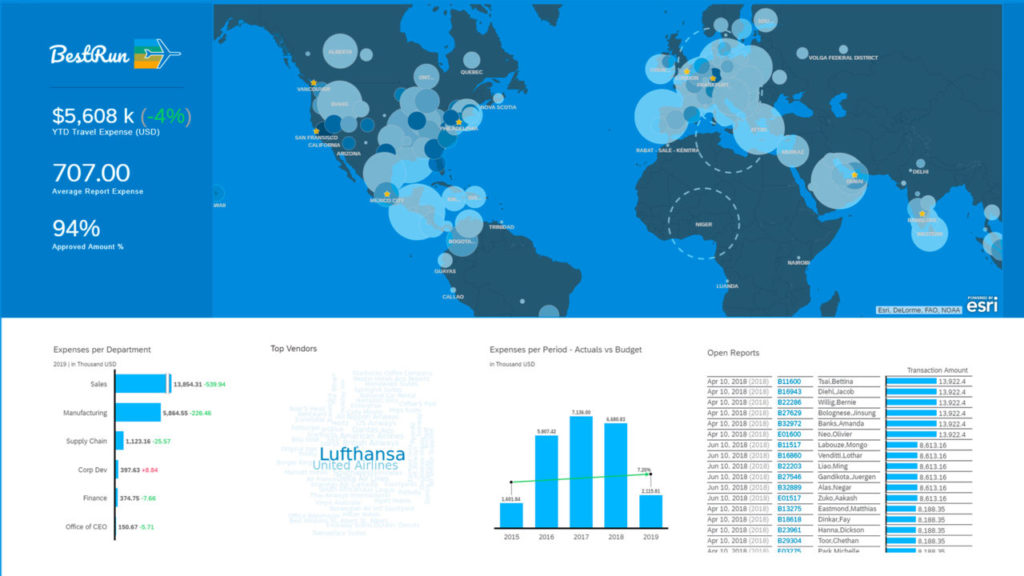
Il existe des centaines de systèmes ERP parmi lesquels choisir, avec un large panel de fonctionnalités, de points forts, de points faibles, d’applicabilité et de tarifs. Si cela peut sembler intimidant, un processus méthodique de comparaison des ERP peut guider votre équipe vers la bonne décision dans un délai raisonnable.
La méthodologie décrite ici, éprouvée, peut vous aider à trouver la solution qui répond le mieux aux besoins de votre entreprise. Elle peut sembler basique mais les entreprises qui se mettent en quête d’un fournisseur ERP sans suivre ces étapes logiques sont souvent confrontées à des retards, coûts supplémentaires et à une personnalisation inutile. Au contraire, les entreprises qui appliquent les meilleures pratiques gagnent généralement en fluidité dans le processus de sélection et dans les implémentations subséquentes. Elles peuvent ainsi profiter plus rapidement des avantages d’un système ERP moderne et être plus compétitives à l’ère du numérique.
Une méthodologie en 5 étapes pour évaluer les systèmes ERP
Une fois la décision prise de remplacer un ancien système ERP, la première étape consiste à monter une équipe pour piloter le processus de comparaison, de sélection et d’implémentation du logiciel ERP. L’équipe commence son travail par l’élaboration d’un plan initial, qui est plutôt à ce stade une stratégie générale.
Le processus de sélection d’un fournisseur ERP se déroule en cinq étapes :
- Définition des besoins en matière d’ERP
- Appel d’offres
- Evaluation de pré-sélection
- Comparaison des ERP et évaluation détaillée
- Décision finale et contrat
1. Définition des besoins en matière d’ERP
Vous devrez transmettre des informations concernant votre entreprise et ses besoins à vos fournisseurs ERP potentiels afin qu’ils puissent configurer, packager et tarifer correctement la solution appropriée. Commencez par identifier les principales ressources en ligne, telles que les démonstrations de produits et les blogs, qui racontent l’histoire de votre entreprise.
Décrivez votre entreprise et ses processus de manière générale plutôt que de créer de longues listes de besoins et processus spécifiques. Informez les fournisseurs de la taille de votre entreprise, de son volume d’activité et de transactions, de la complexité des différents processus et de toute caractéristique ou facteur spécifique. Concentrez-vous sur les critères et processus qui donnent à votre entreprise son avantage concurrentiel. Ce sont ces éléments qui différencieront les systèmes et qui vous permettront d’examiner de près la façon dont chacun peut être configuré pour les prendre en charge.
Indiquez les éléments que vous aimez dans votre système actuel. En effet, vous voudrez que votre nouveau système les gère au moins aussi bien. De même, indiquez les choses que votre système actuel ne fait pas (ou mal). Signalez les applications, fonctions ou modifications personnalisées qui doivent être prises en charge par des fonctionnalités standard ou une personnalisation simple du nouveau système (et non une modification). En d’autres termes, concentrez-vous sur les éléments qui sont uniques à votre entreprise et partez du principe que les éléments de base se feront d’eux-mêmes (vous vérifierez cette hypothèse lors des démonstrations et des évaluations finales).
« Concentrez-vous sur les éléments qui sont uniques à votre entreprise et partez du principe que les éléments de base se feront d’eux-mêmes. »
Principaux points à retenir et conseils
Ne vous fiez pas aux listes de contrôle / vérification des ERP. Ces check-lists, une vieille pratique courante dans le secteur, ne permettent pas de départager les solutions et ne vous aident pas vraiment à faire un bon choix. La majorité des éléments figurant sur ces listes sont des fonctions et caractéristiques proposées par tous les systèmes, au moins dans une certaine mesure. Et les fournisseurs en compétition sont susceptibles de cocher « oui » dans l’interprétation la plus large de la fonctionnalité.
Choisissez les bonnes personnes pour votre équipe projet. La spécification des besoins est une tâche difficile. Elle nécessite des collaborateurs engagés, qui connaissent bien l’entreprise et qui ont du temps à consacrer au projet. Refreinez la tentation de constituer une équipe de personnes enthousiastes mais inexpérimentées.
Assurez-vous que votre appel d’offres contient les informations suivantes :
- Présentation de votre entreprise et de ses processus
- Ce que votre système actuel fait bien
- Ce qu’il ne fait pas aussi bien que vous le souhaiteriez
- Ce que vous voulez que le nouveau système fasse d’autre (classé par ordre d’importance)
2. Appel d’offres ERP
L’étape suivante consiste à envoyer un appel d’offres à un groupe sélectionné de fournisseurs. Leur nombre peut varier, mais n’oubliez pas que vous devrez procéder à un examen détaillé pour chaque réponse. L’expérience a montré que plus le nombre de fournisseurs est réduit, plus les informations fournies sont détaillées et meilleures sont les réponses. Il est donc préférable d’identifier une douzaine (ou moins) des meilleurs candidats pour votre short list.
« L’expérience a montré que plus le nombre de fournisseurs est réduit, plus les informations fournies sont détaillées et meilleures sont les réponses. »
En réponse, les fournisseurs d’ERP doivent proposer un système qui offre les fonctionnalités et les caractéristiques requises pour répondre aux besoins que vous avez identifiés. Les propositions contiendront également des informations sur leurs sociétés, leurs produits, leur expérience dans le domaine, les ressources qu’ils consacreront à l’implémentation, ainsi que d’autres informations destinées à gagner votre confiance.
Alors comment identifier la douzaine (ou moins) de candidats sur lesquels concentrer vos efforts de sélection ? Comment réduire la liste des centaines de fournisseurs d’ERP pour n’en retenir que quelques-uns ? Commencez par consulter les publications spécialisées qui présentent des « success stories ERP » (gardez à l’esprit que ces publications ne vous parleront probablement pas des difficultés rencontrées ou des échecs, mettez donc ces informations en perspective). Utilisez vos contacts – par exemple associations et groupes d’entreprises – pour identifier d’autres professionnels qui ont pu avoir une expérience récente de la sélection et de l’implémentation d’un ERP.
Il existe également de nombreux annuaires en ligne, outils de sélection et services de sélection de systèmes qui peuvent vous aider à identifier les logiciels qui possèdent les fonctionnalités dont vous avez besoin et/ou les fournisseurs qui ont de l’expérience dans votre secteur.
Pour obtenir des conseils personnalisés, vous pouvez passer un contrat avec la branche conseil de votre cabinet comptable ou trouver une ressource conseil indépendante dans votre région et/ou dans votre secteur d’activité. Veillez à vérifier leurs antécédents et leurs affiliations pour vous assurer qu’ils sont réellement indépendants et pas associés à un ou plusieurs fournisseurs de systèmes ERP.
Vous pouvez choisir d’inclure certains fournisseurs de systèmes ERP qui présentent un intérêt pour d’autres raisons. Peut-être qu’un ou plusieurs de vos clients les plus importants utilisent un système ERP et vous ont encouragé à utiliser le même système. Ou peut-être que votre société fait partie d’une grande entreprise ou d’un groupe qui a opté pour une plateforme ERP donnée. Demandez une proposition au fournisseur recommandé puis évaluez toutes les propositions de manière équitable et impartiale avant de prendre votre décision.
Principaux points à retenir et conseils
Veillez à ce que toutes les parties prenantes définissent leurs besoins. Votre appel d’offres doit inclure les contributions de toutes les parties prenantes. Dans le cas contraire, vous risquez de choisir un système ERP qui ne sert que certaines fonctions de votre entreprise, obligeant les autres départements à investir dans des systèmes autonomes. Évaluez les systèmes qui fonctionnent pour l’ensemble de l’entreprise et utilisez le calendrier de déploiement pour livrer les modules prioritaires en premier.
Faites attention au classement des besoins. Souvent, l’appel d’offres est divisé en domaines fonctionnels avec des sections à remplir par chaque service. Chaque département – qu’il s’agisse des RH ou des opérations – fait généralement un excellent travail de classement des fonctionnalités pour son unité opérationnelle, mais ses priorités peuvent ne pas correspondre aux objectifs globaux de l’entreprise. C’est à votre équipe projet d’ajuster les priorités dans une perspective plus large. Quelles sont les fonctionnalités vitales, importantes ou simplement souhaitables ?
Vérifiez la disponibilité effective des fonctionnalités. Les sociétés de logiciels ont d’excellents départements marketing ; certaines vendent des produits qui n’ont pas été entièrement développés et testés. Faites des recherches sur les fonctionnalités « à venir dans une prochaine version » par rapport à celles qui sont utilisées dans les références actuelles. Il est tout à fait envisageable de prendre en compte les fonctionnalités en cours de développement – mais ne pariez pas tout votre projet sur des fonctionnalités à venir si elles sont essentielles.
Évaluez vos processus. Les processus intégrés dans les ERP packagés sont considérés comme étant conformes aux « meilleures pratiques ». Les consultants et les experts de l’implémentation d’ERP vous diront qu’il est presque toujours préférable de modifier la procédure pour l’adapter au logiciel (en tenant compte de la dimension « meilleure pratique ») que de modifier le logiciel pour l’adapter à la procédure existante. Toutefois, c’est à vous de prendre cette décision. Mais n’oubliez pas que les nouveaux processus peuvent être à l’origine des progrès et des avantages que vous tirez d’un nouveau système. N’oubliez pas non plus que tous les logiciels ERP modernes sont personnalisables. Vous disposez donc d’une grande souplesse pour modifier l’affichage, les procédures, les caractéristiques des données et leur traitement, et bien d’autres choses encore – sans modifier le code.
Tenez compte du retour sur investissement de votre ERP. La plupart des entreprises exigent une analyse du retour sur investissement (ROI) comme condition préalable à l’autorisation et au financement de tout projet majeur. Comme son nom l’indique, il s’agit de la somme des coûts liés à l’achat et au déploiement du nouveau système, plus la différence des coûts d’exploitation par rapport à ceux du système existant. Le ROI tient également compte des avantages qui s’ajoutent aux économies directes, notamment l’amélioration du rendement, du service à la clientèle et de la productivité au travail.
3. Evaluation de pré-sélection
L’évaluation se déroule en deux phases. Au cours de la première phase, toutes les propositions sont évaluées pour voir dans quelle mesure elles correspondent à votre environnement et aux exigences décrites dans votre appel d’offres (cette phase ne comprend pas la comparaison des fournisseurs, qui relève de la deuxième phase d’évaluation).
L’objectif à ce stade est d’écarter les offres qui ne remplissent pas vos critères et de classer celles qui semblent convenir. Il en résulte une short list des meilleures propositions. Celles-ci, et seulement celles-ci, seront soumises à une évaluation détaillée jusqu’à la sélection finale.
Si vous devez examiner de nombreuses réponses, les détails auront tendance à se brouiller et il vous sera difficile de vous souvenir des réponses particulièrement solides (ou celles insuffisantes) et dans quels domaines. Une échelle de notation numérique peut vous aider à ne pas perdre le fil et à documenter votre processus de décision. Voici quelques conseils supplémentaires pour vous aider lors de cette étape de documentation :
- Mettez en place un formulaire ou une feuille de calcul agencée de manière à ce que les évaluateurs puissent noter chaque proposition en fonction des principaux critères que vous avez spécifiés. Demandez à chaque examinateur d’attribuer une note à chaque critère d’évaluation (l’échelle peut être de un à dix, de un à cinq, de un à trois, ou tout autre niveau de granularité que vous jugez approprié). Vous pouvez avoir autant ou aussi peu d’examinateurs que vous le souhaitez.
- Laissez de la place pour des notes et des questions, pour le suivi. Vous pouvez demander des éclaircissements à ce stade ou attendre l’évaluation détaillée des propositions présélectionnées. Attribuez un coefficient à chaque critère en fonction de l’importance de la fonction ou du processus pour votre entreprise.
- Multipliez la note donnée par chaque évaluateur par le coefficient de chaque critère et calculez une note globale pour chaque fournisseur. Le plus souvent, plusieurs d’entre eux se classeront en haut de l’échelle, plusieurs autres un peu plus loin dans le classement, et quelques-uns ne seront pas retenus. Vous devriez maintenant avoir votre short list de finalistes – idéalement trois à cinq candidats – pour l’évaluation finale.
- Il y a de bonnes chances que vous puissiez identifier les meilleurs candidats, mais si ce n’est pas aussi clair, revenez aux évaluations individuelles et discutez-en avec l’équipe.
Principaux points à retenir et conseils
Traitez chaque fournisseur potentiel de la même manière. N’acceptez pas de démonstrations en direct, de réunions spéciales en présentiel ou de visites sur place, à moins que vous ne soyez prêt à offrir la même possibilité à tous les fournisseurs. Il est important de maintenir des règles du jeu équitables. Une technique courante consiste à organiser une « conférence des candidats » dans vos locaux pour faire visiter les lieux à tous les fournisseurs potentiels et répondre à leurs questions (devant tout le monde).
N’oubliez pas qu’une proposition est un document de vente. Les réponses contiendront les informations que vous avez demandées et bien plus. Partez du principe que toutes les affirmations sont véridiques ; vous pourrez vérifier la plupart, sinon toutes, au cours du processus d’évaluation. Mais sachez que les auteurs de la proposition répondront à vos questions de manière à présenter leurs produits sous le jour le plus favorable.
Recherchez les valeurs aberrantes. Accordez une attention particulière aux critères pour lesquels les notes varient considérablement. Si un évaluateur donne une note très élevée à une proposition pour un critère et qu’un autre évaluateur lui donne une note très basse, cela vaut la peine d’en discuter. Interrogez les deux évaluateurs de manière constructive pour savoir ce que chacun pensait. Il est probable que l’un ou l’autre ait remarqué quelque chose que les autres n’ont pas vu ou n’ont pas considéré comme important. À la suite de ces discussions, vous souhaiterez peut-être ajuster les notes pour un critère spécifique, ce qui pourrait modifier le classement général.
4. Comparaison des ERP et évaluation détaillée
Une fois que vous avez identifié trois à cinq finalistes, il est temps de vous mettre au travail pour vérifier leurs affirmations et valider leurs références.
Comment commencer votre évaluation
- Prenez contact avec chacun des fournisseurs potentiels et annoncez-leur la bonne nouvelle : ils ont été retenus dans la short list ! (Il n’y a pas de mal à leur dire combien il y a d’autres finalistes et même à leur faire savoir avec quelles entreprises ils sont en concurrence, si vous êtes à l’aise pour le faire).
- Dans certains cas, vous pouvez également leur demander d’affiner leurs propositions.
- Discutez avec les utilisateurs actuels du système (ou rendez-leur visite), de préférence ceux de votre industrie (ou d’un marché comparable) et de la taille de votre entreprise.
- Obtenez des références si les éditeurs ne les ont pas déjà fournies (les fournisseurs peuvent hésiter à fournir des références pour des raisons de concurrence. Mais vous devez insister. Rassurez-les sur le fait que vous signerez et respecterez les accords de non-divulgation).
Comment gérer les démonstrations
C’est également le moment d’inviter les candidats présélectionnés à effectuer des démonstrations détaillées de leurs systèmes – mais vous devez contrôler ces démonstrations.
- Fournissez à chaque candidat un script ou une liste des fonctionnalités que vous souhaitez voir bien avant la démonstration prévue. Tous les fournisseurs potentiels devraient recevoir la même liste.
- Permettez-leur de montrer les fonctions spéciales qu’ils souhaitent mettre en avant uniquement après vous avoir montré les fonctions et les processus décrits dans l’appel d’offres.
- Assurez-vous que votre script ou votre liste inclut les exigences spécifiques identifiées à l’étape 1. Les systèmes ERP traitent les processus courants de la même manière ; ce sont les exceptions qui posent problème (par exemple, la possibilité d’entrer des commandes pour des articles qui ne sont pas en stock, de vendre des articles dans des packages, des kits ou des ensembles, ou encore la prise en charge d’un processus spécifique de rapprochement des factures).
- Pendant la démonstration, vous voudrez voir comment le logiciel peut être configuré et adapté pour prendre en charge vos processus et procédures uniques. Cela dit, restez ouvert d’esprit dans la mesure où vous pourriez découvrir certaines meilleures pratiques dans ces fonctions standard qui amélioreraient les opérations et les résultats de votre entreprise.
- Dans l’idéal, le démonstrateur sera en mesure de montrer le fonctionnement du système en utilisant vos propres données. Ce n’est pas toujours possible, mais lorsque c’est le cas, cela vous donnera une bien meilleure idée de la façon dont le système fonctionnerait dans votre environnement.
Principaux points à retenir et conseils
Ne vous laissez pas éblouir par les démonstrations. Les professionnels qui font la démonstration des logiciels sont généralement très expérimentés et ont une forte personnalité. Leur objectif est de vous convaincre et de vendre leur logiciel. Ne vous laissez pas distraire par la personne ou le discours de vente, aussi captivant soit-il. Concentrez-vous sur le fond.
Tirez le meilleur parti des visites de référence. Sélectionnez avec soin les visites que vous souhaitez faire. Passez un bref appel à votre interlocuteur pour vous assurer qu’il a bien déployé le logiciel et qu’il a obtenu les avantages promis. Convenez de ce qu’il vous montrera et des personnes que vous rencontrerez au cours de la visite. Une fois sur place, jugez soigneusement si leur succès est reproductible dans votre environnement. Posez également les questions difficiles : « Quelles ont été vos plus grandes surprises ? » et « Si c’était à refaire, que feriez-vous différemment ? ».
Continuez à poser des questions. Encouragez votre équipe à poser des questions, ne serait-ce que pour clarifier les réponses. Faites-le lors de l’examen de l’appel d’offres et pendant les démonstrations ; cela réduira considérablement les risques de mauvaises surprises. C’est le moment de découvrir les réponses qui ne vous plaisent pas – avant que les négociations ne commencent. N’oubliez pas non plus que vous obtenez vos réponses gratuitement à ce stade, alors apprenez-en le plus possible. Lorsque vous commencerez à implémenter le produit, il se peut que vous deviez attendre une assistance ou même payer des frais.
5. Décision finale et contrat
Une fois les évaluations détaillées terminées, vous constaterez probablement que deux ou trois fournisseurs répondent à vos critères. Sélectionnez celui qui, selon vous, répond le mieux à vos besoins actuels et futurs, mais n’écartez pas les autres. Faites-leur plutôt savoir qu’ils vous conviennent mais qu’ils ne sont pas votre premier choix ; cela laisse la porte ouverte au cas où vos négociations avec le meilleur candidat ne se déroulent pas comme prévu.
Vous pouvez maintenant commencer à négocier les détails du contrat avec le meilleur candidat. La plupart des entreprises savent comment cette étape est « censée fonctionner ». Mais comme pour toutes les autres étapes du processus d’évaluation et de sélection d’un ERP, vous risquez d’avoir des surprises.
Le pouvoir est de votre côté dans les négociations. Cependant, il est préférable de considérer le fournisseur comme un futur partenaire, et non comme un adversaire dans les négociations. Visez un accord équitable qui incite les deux parties à déployer le système de manière efficace et à en assurer le bon fonctionnement.
Chaque aspect de l’implémentation du système et du maintien de l’assistance doit être discuté et documenté – en détaillant le prix, la personne responsable et, dans certains cas, le temps nécessaire. Le contrat comporte de nombreux aspects, dont notamment (mais pas exclusivement) :
- L’achat initial, la location ou la licence du matériel et des logiciels.
- L’implémentation du matériel et des logiciels (en précisant ce qu’englobe le mot ‘ »implémentation »).
- Coût et calendrier de la simulation d’implémentation (avant ou après le paiement du logiciel).
- Coûts de formation initiale et continue
- Maintenance continue du matériel et des logiciels (et à quel niveau).
- Conversion des données et intégration à d’autres systèmes
- Mise en réseau et sécurité
- Personnalisations (initiales et avec les versions futures)
Principaux points à retenir et conseils
N’annoncez pas votre sélection finale avant les négociations. À la fin de la phase d’évaluation détaillée, l’équipe peut vouloir déclarer un « gagnant ». Cependant, informer le candidat principal qu’il est « l’élu » n’est pas dans l’intérêt de votre entreprise. Il n’est pas rare d’avoir des surprises au cours du processus de négociation et vous devrez peut-être revoir votre choix.
Planifiez à long terme. Lors du démarrage, veillez à examiner attentivement les coûts à long terme afin que vos estimations soient correctes et que vous ne faussiez pas les chiffres du retour sur investissement de l’ERP. Certains fournisseurs offrent davantage de services gratuits pendant une période plus longue et d’autres peuvent confier leur assistance à long terme à une entreprise qui facture à l’appel. Certains fournisseurs fixent un plafond pour l’augmentation des tarifs annuels de maintenance ou d’abonnement, mais beaucoup ne le font pas. D’autres vendent un abonnement SaaS (Software-as-a-Service) à bas prix, qu’ils augmentent considérablement après quelques années. Certains fournisseurs proposent une mise à jour annuelle, mais ne fournissent aucune assistance réelle lors du processus de mise à jour. Posez des questions et obtenez des réponses écrites pour être sûr de bien appréhender vos coûts à long terme.
L’importance de l’équipe projet
Le facteur le plus important pour le succès du processus d’évaluation du système ERP est l’équipe projet. Cette équipe doit être constituée très tôt et doit être le moteur de l’élaboration, de la diffusion et de l’évaluation de l’appel d’offres et de la sélection du nouveau système ERP.
D’après notre expérience, lorsque les équipes sont au milieu d’une investigation et d’une évaluation détaillées, elles prennent souvent des raccourcis. Mais si votre équipe projet suit ces cinq étapes et prête attention aux enseignements tirés, elle sera en mesure de trouver la solution optimale pour répondre aux exigences de votre entreprise, maintenant et pour l’avenir.
Publié en anglais sur insights.sap.com
The post Conseils pour bien choisir votre (nouveau) système ERP appeared first on SAP France News.
Source de l’article sur sap.com