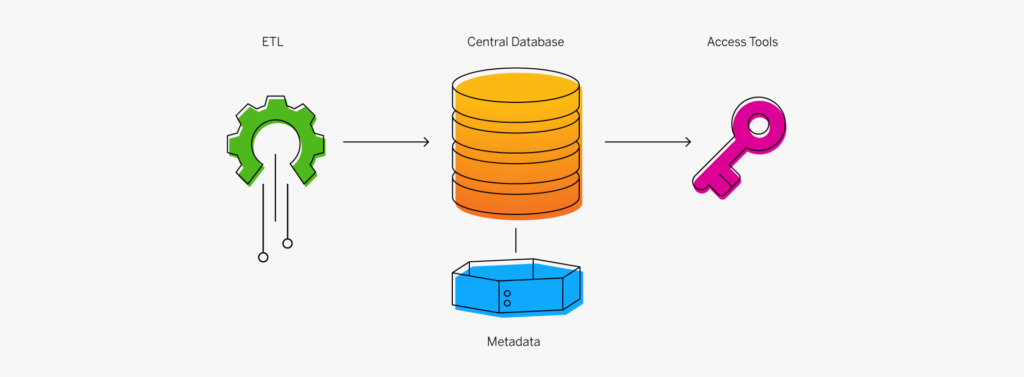
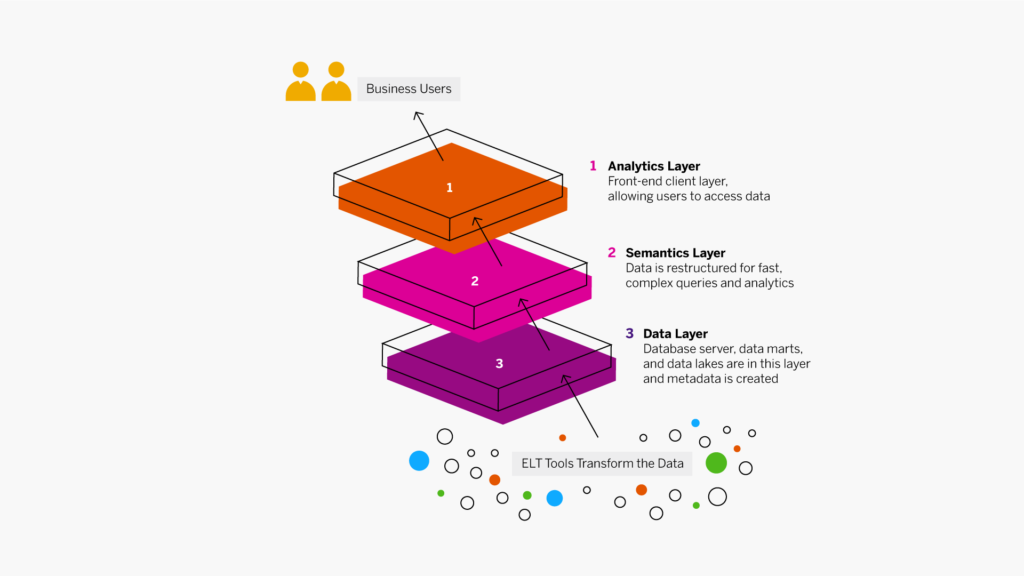
La modélisation des données correspond au processus de création de diagrammes de flux de données. Lors de la création d’une structure de base de données, qu’elle soit nouvelle ou non, le concepteur commence par élaborer un diagramme illustrant la façon dont les données entreront et sortiront de la base de données. Ce diagramme est utilisé pour définir les caractéristiques des formats et structures de données, ainsi que des fonctions de gestion de base de données, afin de répondre efficacement aux exigences des flux de données. Une fois la base de données créée et déployée, le modèle de données servira de documentation expliquant les motifs de création de la base de données ainsi que la manière dont les flux de données ont été conçus.
Le modèle de données résultant de ce processus établit une structure de relations entre les éléments de données dans une base de données et sert de guide d’utilisation des données. Les modèles de données sont un élément fondamental du développement et de l’analyse de logiciels. Ils fournissent une méthode standardisée pour définir et mettre en forme les contenus de base de données de manière cohérente dans les systèmes, ce qui permet à diverses applications de partager les mêmes données.
Pourquoi la modélisation des données est-elle importante ?
Un modèle de données complet et optimisé permet de créer une base de données logique et simplifiée qui élimine la redondance, réduit les besoins en stockage et permet une récupération efficace. Elle dote également tous les systèmes de ce que l’on appelle une « source unique de la vérité », ce qui est essentiel pour assurer des opérations efficaces et garantir une conformité vérifiable aux réglementations et exigences réglementaires. La modélisation des données est une étape clé dans deux fonctions vitales d’une entreprise numérique.
Projets de développement logiciel (nouveaux ou personnalisations) mis en place par le service informatique
Avant de concevoir et de créer un projet logiciel, il doit exister une vision documentée de ce à quoi ressemblera le produit final et de son comportement. Une grande partie de cette vision concerne l’ensemble de règles de gestion qui régissent les fonctionnalités souhaitées. L’autre partie est la description des données : les flux de données (ou le modèle de données) et la conception de la base de données qui les prendra en charge.
La modélisation des données est une trace de cette vision et fournit une feuille de route pour les concepteurs de logiciels. Grâce à la définition et à la documentation complètes des flux de données et de la base de données, ainsi qu’au développement des systèmes conformément à ces spécifications, les systèmes devraient être en mesure de fournir les fonctionnalités attendues requises pour garantir l’exactitude des données (en supposant que les procédures ont été correctement suivies).
Analyses et visualisation (ou Business Intelligence) : un outil de prise de décision clé pour les utilisateurs
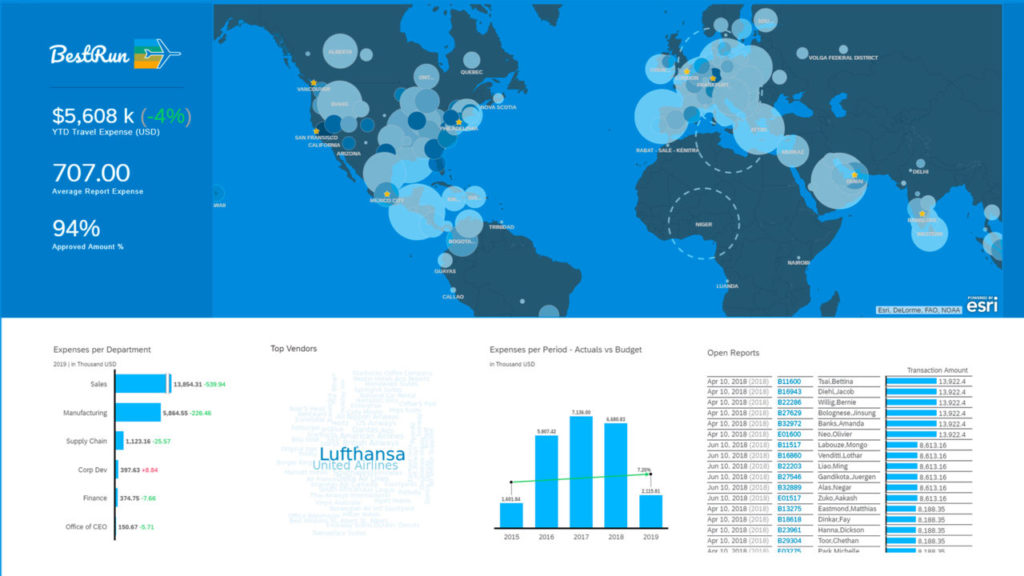
Avec l’augmentation des volumes de données et le nombre croissant d’utilisateurs, les entreprises ont besoin de transformer les données brutes en informations exploitables pour prendre des décisions. Sans surprise, la demande en analyse des données a augmenté de façon spectaculaire. La visualisation des données rend les données encore plus accessibles aux utilisateurs en les présentant sous forme graphique.
Les modèles de données actuels transforment les données brutes en informations utiles qui peuvent être transposées dans des visualisations dynamiques. La modélisation des données prépare les données pour l’analyse : nettoyage des données, définition des mesures et des dimensions, amélioration des données par l’établissement de hiérarchies, la définition d’unités et de devises et l’ajout de formules.
Quels sont les types de modélisation des données ?
Les trois types de modèles de données clés sont le modèle relationnel, le modèle dimensionnel et le modèle entité-association. Il en existe d’autres qui ne sont pas communément utilisés, notamment les types hiérarchique, réseau, orienté objet et à plusieurs valeurs. Le type de modèle définit la structure logique, à savoir comment les données sont stockées, organisées et extraites.
- Type relationnel : bien qu’« ancien » dans son approche, le modèle de base de données le plus couramment utilisé aujourd’hui est le relationnel, qui stocke les données dans des enregistrements au format fixe et organise les données dans des tables avec des lignes et des colonnes. Le type de modèle de données le plus basique comporte deux éléments : des mesures et des dimensions. Les mesures sont des valeurs numériques, telles que les quantités et le chiffre d’affaires, utilisées dans les calculs mathématiques comme la somme ou la moyenne. Les dimensions peuvent correspondre à des valeurs numériques ou textuelles. Elles ne sont pas utilisées dans les calculs et incluent des descriptions ou des emplacements. Les données brutes sont définies comme une mesure ou une dimension. Autres termes utilisés dans la conception de base de données relationnelle : « relations » (la table comportant des lignes et des colonnes), « attributs » (colonnes), « nuplets » (lignes) et « domaine » (ensemble de valeurs autorisées dans une colonne). Bien qu’il existe d’autres termes et exigences structurelles qui définissent une base de données relationnelle, le facteur essentiel concerne les relations définies dans cette structure. Les éléments de données communs (ou clés) relient les tables et les ensembles de données. Les tables peuvent également être explicitement liées, comme une relation parent/enfant, y compris les relations dites un-à-un (one-to-one), un-à-plusieurs (one-to-many) ou plusieurs-à-plusieurs (many-to-many).
- Type dimensionnel : moins rigide et structurée, l’approche dimensionnelle privilégie une structure de données contextuelle davantage liée à l’utilisation professionnelle ou au contexte. Cette structure de base de données est optimisée pour les requêtes en ligne et les outils d’entreposage de données. Les éléments de données critiques, comme une quantité de transaction par exemple, sont appelés « faits » et sont accompagnés d’informations de référence appelées « dimensions », telles que l’ID de produit, le prix unitaire ou la date de la transaction. Une table de faits est une table primaire dans un modèle dimensionnel. La récupération peut être rapide et efficace (avec des données pour un type d’activité spécifique stockées ensemble), mais l’absence de relations peut compliquer l’extraction analytique et l’utilisation des données. Étant donné que la structure des données est liée à la fonction qui produit et utilise les données, la combinaison de données produites par divers systèmes (dans un entrepôt de données, par exemple) peut poser des problèmes.
- Modèle entité-association (modèle E-R) : un modèle E-R représente une structure de données métier sous forme graphique contenant d’une part des boîtes de différentes formes pour représenter des activités, des fonctions ou des « entités », et d’autre part des lignes qui représentent des dépendances, des relations ou des « associations ». Le modèle E-R est ensuite utilisé pour créer une base de données relationnelle dans laquelle chaque ligne représente une entité et comporte des zones qui contiennent des attributs. Comme dans toutes les bases de données relationnelles, les éléments de données « clés » sont utilisés pour relier les tables entre elles.
Quels sont les trois niveaux d’abstraction des données ?
Il existe de nombreux types de modèles de données, avec différents types de mises en forme possibles. La communauté du traitement des données identifie trois types de modélisation permettant de représenter les niveaux de pensée au fur et à mesure que les modèles sont développés.
Modèle de données conceptuel
Ce modèle constitue une « vue d’ensemble » et représente la structure globale et le contenu, mais pas le détail du plan de données. Il s’agit du point de départ standard de la modélisation des données qui permet d’identifier les différents ensembles de données et flux de données dans l’organisation. Le modèle conceptuel dessine les grandes lignes pour le développement des modèles logiques et physiques, et constitue une part importante de la documentation relative à l’architecture des données.
Modèle de données logique
Le deuxième niveau de détail est le modèle de données logique. Il est étroitement lié à la définition générale du « modèle de données » en ce sens qu’il décrit le flux de données et le contenu de la base de données. Le modèle logique ajoute des détails à la structure globale du modèle conceptuel, mais n’inclut pas de spécifications pour la base de données en elle-même, car le modèle peut être appliqué à diverses technologies et divers produits de base de données. (Notez qu’il peut ne pas exister de modèle conceptuel si le projet est lié à une application unique ou à un autre système limité).
Modèle de données physique
Le modèle de base de données physique décrit comment le modèle logique sera réalisé. Il doit contenir suffisamment de détails pour permettre aux techniciens de créer la structure de base de données dans les matériels et les logiciels pour prendre en charge les applications qui l’utiliseront. Il va sans dire que le modèle physique est spécifique à un système logiciel de base de données en particulier. Il peut exister plusieurs modèles physiques dérivés d’un seul et même modèle logique si plusieurs systèmes de base de données seront utilisés.
Processus et techniques de modélisation des données
La modélisation des données est par essence un processus descendant qui débute par l’élaboration du modèle conceptuel pour établir la vision globale, puis se poursuit avec le modèle logique pour s’achever par la conception détaillée contenue dans le modèle physique.
L’élaboration du modèle conceptuel consiste principalement à mettre des idées sous la forme d’un graphique qui ressemble au diagramme des flux de données conçu par un développeur.
Les outils de modélisation des données modernes peuvent vous aider à définir et à créer vos modèles de données logiques et physiques et vos bases de données. Voici quelques techniques et étapes classiques de modélisation des données :
- Déterminez les entités et créez un diagramme entité-association. Les entités sont considérées comme des « éléments de données qui intéressent votre entreprise ». Par exemple, « client » serait une entité. « Vente » en serait une autre. Dans un diagramme entité-association, vous documentez la manière dont ces différentes entités sont liées les unes aux autres dans votre entreprise, et les connexions qui existent entre elles.
- Définissez vos faits, mesures et dimensions. Un fait est la partie de vos données qui indique une occurrence ou une transaction spécifique, comme la vente d’un produit. Vos mesures sont quantitatives, comme la quantité, le chiffre d’affaires, les coûts, etc. Vos dimensions sont des mesures qualitatives, telles que les descriptions, les lieux et les dates.
- Créez un lien de vue de données à l’aide d’un outil graphique ou via des requêtes SQL. Si vous ne maîtrisez pas SQL, l’option la plus intuitive sera l’outil graphique : il vous permet de faire glisser des éléments dans votre modèle et de créer visuellement vos connexions. Lors de la création d’une vue, vous avez la possibilité de combiner des tables et d’autres vues dans une sortie unique. Lorsque vous sélectionnez une source dans la vue graphique et que vous la faites glisser dans une source déjà associée à la sortie, vous pouvez soit la joindre, soit créer une union de ces tables.
Les solutions analytiques modernes peuvent également vous aider à sélectionner, filtrer et connecter des sources de données à l’aide d’un affichage graphique de type glisser-déposer. Des outils avancés sont disponibles pour les experts en données qui travaillent généralement au sein des équipes informatiques. Toutefois, les utilisateurs peuvent également créer leurs propres présentations en créant visuellement un modèle de données et en organisant des tables, des graphiques, des cartes et d’autres objets pour élaborer une présentation basée sur des analyses de données.
Exemples de modélisation des données
Pour toute application, qu’elle soit professionnelle, de divertissement, personnelle ou autre, la modélisation des données est une étape préalable nécessaire à la conception du système et à la définition de l’infrastructure nécessaire à sa mise en œuvre. Cela concerne tout type de système transactionnel, de suite d’applications de traitement des données, ou tout autre système qui collecte, crée ou utilise des données.
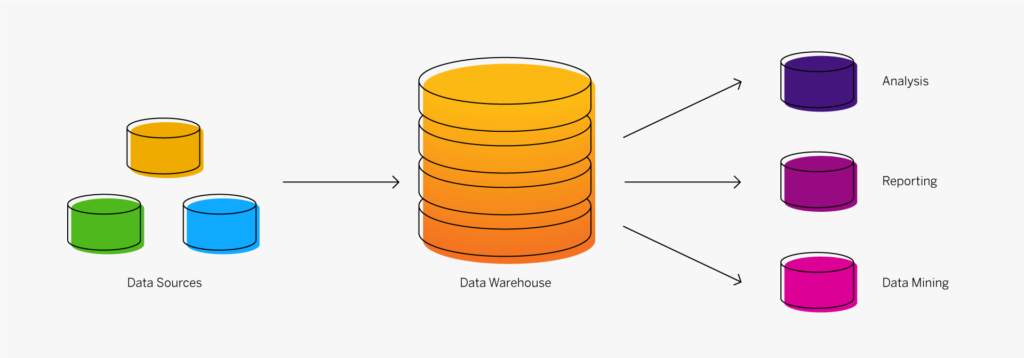
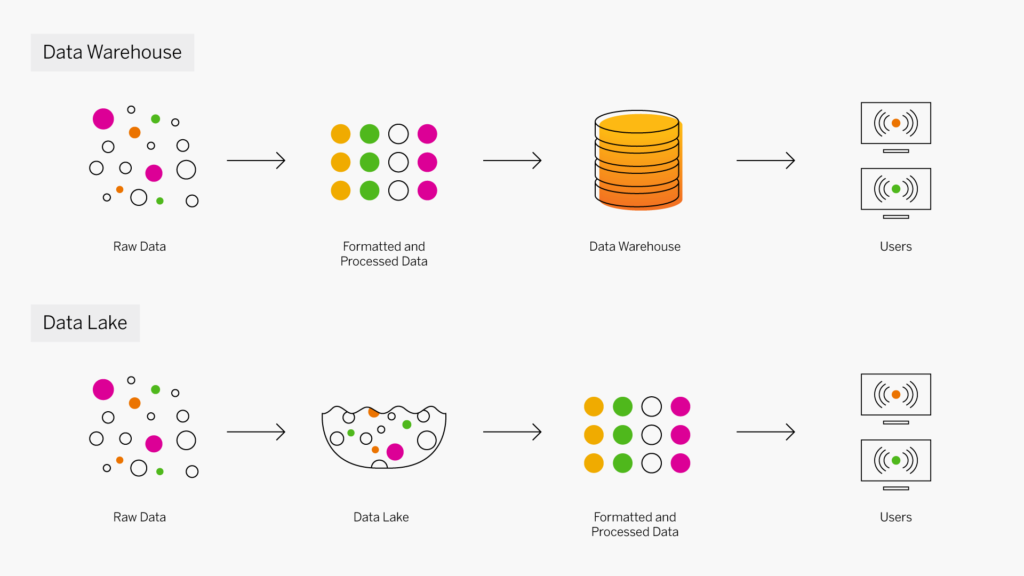
La modélisation des données est essentielle pour l’entreposage de données car un entrepôt de données est un référentiel de données provenant de plusieurs sources, qui contiennent probablement des données similaires ou liées, mais disponibles sous des formats différents. Il est nécessaire de mapper en premier lieu les formats et la structure de l’entrepôt afin de déterminer comment manipuler chaque ensemble de données entrant pour répondre aux besoins de la conception de l’entrepôt, afin que les données soient utiles pour l’analyse et l’exploration de données. Le modèle de données est alors un catalyseur important pour les outils analytiques, les systèmes d’information pour dirigeants (tableaux de bord), l’exploration de données et l’intégration à tous les systèmes et applications de données.
Dans les premières étapes de conception de n’importe quel système, la modélisation des données est une condition préalable essentielle dont dépendent toutes les autres étapes pour établir la base sur laquelle reposent tous les programmes, fonctions et outils. Le modèle de données est comparable à un langage commun permettant aux systèmes de communiquer selon leur compréhension et leur acceptation des données, comme décrit dans le modèle. Dans le monde actuel de Big Data, d’apprentissage automatique, d’intelligence artificielle, de connectivité Cloud, d’IdO et de systèmes distribués, dont l’informatique en périphérie, la modélisation des données s’avère plus importante que jamais.
Évolution de la modélisation des données
De façon très concrète, la modélisation des données est apparue en même temps que le traitement des données, le stockage de données et la programmation informatique, bien que le terme lui-même n’ait probablement été utilisé qu’au moment où les systèmes de gestion de base de données ont commencé à évoluer dans les années 1960. Il n’y a rien de nouveau ou d’innovant dans le concept de planification et d’architecture d’une nouvelle structure. La modélisation des données elle-même est devenue plus structurée et formalisée au fur et à mesure que davantage de données, de bases de données et de variétés de données sont apparues.
Aujourd’hui, la modélisation des données est plus essentielle que jamais, étant donné que les techniciens se retrouvent face à de nouvelles sources de données (capteurs IdO, appareils de localisation, flux de clics, réseaux sociaux) et à une montée des données non structurées (texte, audio, vidéo, sorties de capteurs brutes), à des volumes et à une vitesse qui dépassent les capacités des systèmes traditionnels. Il existe désormais une demande constante de nouveaux systèmes, de nouvelles structures et techniques innovantes de bases de données, et de nouveaux modèles de données pour rassembler ces nouveaux efforts de développement.
Quelle est la prochaine étape de la modélisation des données ?
La connectivité des informations et les grandes quantités de données provenant de nombreuses sources disparates (capteurs, voix, vidéo, emails, etc.) étendent le champ d’application des projets de modélisation pour les professionnels de l’informatique. Internet est, bien sûr, l’un des moteurs de cette évolution. Le Cloud est en grand partie la solution car il s’agit de la seule infrastructure informatique suffisamment grande, évolutive et agile pour répondre aux exigences actuelles et futures dans un monde hyperconnecté.
Les options de conception de base de données évoluent également. Il y a dix ans, la structure dominante de la base de données était relationnelle, orientée lignes et utilisait la technologie traditionnelle de l’espace disque. Les données du grand livre ou de la gestion des stocks d’un système ERP standard étaient stockées dans des dizaines de tables différentes qui doivent être mises à jour et modélisées. Aujourd’hui, les solutions ERP modernes stockent des données actives dans la mémoire à l’aide d’une conception en colonnes, ce qui réduit considérablement le nombre de tables et accroît la vitesse et l’efficacité.
Pour les professionnels du secteur, les nouveaux outils en libre-service disponibles aujourd’hui continueront à s’améliorer. De nouveaux outils seront également introduits pour rendre la modélisation et la visualisation des données encore plus simples et plus collaboratives.
Synthèse
Un modèle de données bien pensé et complet est la clé du développement d’une base de données véritablement fonctionnelle, utile, sécurisée et exacte. Commencez par le modèle conceptuel pour présenter tous les composants et fonctions du modèle de données. Affinez ensuite ces plans dans un modèle de données logique qui décrit les flux de données et définit clairement les données nécessaires et la manière dont elles seront acquises, traitées, stockées et distribuées. Le modèle de données logique donne lieu au modèle de données physique spécifique à un produit de base de données et constitue le document de conception détaillé qui guide la création de la base de données et du logiciel d’application.
Une bonne modélisation des données et une bonne conception de base de données sont essentielles au développement de bases de données et de systèmes d’application fonctionnels, fiables et sécurisés, qui fonctionnent bien avec les entrepôts de données et les outils analytiques, et facilitent l’échange de données entre les partenaires et entre les suites d’application. Des modèles de données bien pensés aident à garantir l’intégrité des données, ce qui rend les données de votre entreprise encore plus précieuses et fiables.

Découvrez les outils modernes de modélisation des données de SAP Data Warehouse Cloud
The post Qu’est-ce que la modélisation des données ? appeared first on SAP France News.