
In this example, we’ll learn how to create a separate schema for loading Spring Batch metadata tables and actual code. Inspiration from: https://www.linkedin.com/post/edit/6617880493067210752/
DatabaseConfig.java
In this example, we’ll learn how to create a separate schema for loading Spring Batch metadata tables and actual code. Inspiration from: https://www.linkedin.com/post/edit/6617880493067210752/
DatabaseConfig.java

Apache Ignite as a distributed database and caching platform needs end-to-end monitoring to act on time. Historically, Apache Ignite provides a set of API and instrumentation to gather application-specific information and metrics by the external tools. In release 2.8.0, Apache Ignite improved the monitoring capabilities and introduced some nice features like "System views subsystem" and "Metrics subsystem."
In this short article, we are going to explore the Apache Ignite new monitoring opportunities and how to use different tools and technics to gather metrics for diagnosis. Anyway, the full release notes of version 2.8.0 can be found here.

Quarkus supports imperative as well as reactive programming styles. In this article, I compare access times to Postgres from Java-based microservices developed with Quarkus. For synchronous invocations Panache is used, for asynchronous access Vert.x Axle.
I’ve created a sample application that comes with the cloud-native-starter project. The ‘articles’ microservice accesses the database running in Kubernetes. To keep the scenario simple, only one REST API is tested which reads articles from Postgres.

Spider is a storage engine for the MariaDB Platform that allows you to build distributed databases from a standard MariaDB setup. The technology is not complicated, although the implementation is. This blog will explain how the Spider storage engine works, what it does and will also show some of the use cases.
Before we look at the Spider storage engine, let’s have a quick look at the storage engine concept. A storage engine is the implementation of code that manages the low level of data access in MariaDB. The storage engine handles things such as reading and writing data, row-level locking, if supported, multi-versioning and transaction management, among other things.

Couchbase N1QL is a SQL-like language for JSON data. To retrieve and manipulate JSON data effectively, we need appropriate indexes. The rules for creating these indexes can be read here. But that involves too much reading, hence we now have an Index Advisor service that accepts a query and gives out an index recommendation that would meet the expectations of the Couchbase query engine — all without downloading the latest Couchbase server.
This service will provide index recommendations to help DBAs, developers, and architects optimize query performance and meet the SLAs.

As more organizations look to migrate their databases to the cloud, what does this mean for developers? We at DZone believe there is no one better to ask than you! Tell us about your experiences with cloud databases by taking this 5 minute survey!
 Over the next two weeks, we plan to survey hundreds of software developers about their experiences with cloud databases. The key findings from the survey will be found in our Cloud Database Trend Report to be released February 19. It is our hope that we can identify some of the key trends happening in the space to help our community stay ahead of the curve.
Over the next two weeks, we plan to survey hundreds of software developers about their experiences with cloud databases. The key findings from the survey will be found in our Cloud Database Trend Report to be released February 19. It is our hope that we can identify some of the key trends happening in the space to help our community stay ahead of the curve.

When we think about the performance of a database, indexing is the first thing that comes to the mind. Here, we are going to look into how database indexing works on a database. Please note that here, architectural details are described referenced to SQLite 2.x database architecture. You can find out the backend implementation of SQLite 2.5.0 with tests, which is relevant to this post from https://github.com/madushadhanushka/simple-sqlite.
Read how overall SQLite database architecture composed in this DZone article.
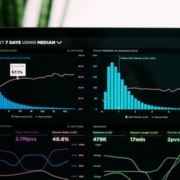
Monitoring metrics is highly important to operate distributed systems in production. Alluxio collects metrics using the Codahale Metrics Library on I/O throughput, RPC throughput, and resource usage. Alluxio metrics are shown in its webUI but are also available through a REST endpoint or exportable to several third-party sinks in a time-series manner (see docs).
Grafana, a comprehensive metrics visualization software, ties into this process by pulling the metrics that systems like Alluxio collect through a sink and visualizes them in a more helpful fashion. This guide will cover how to set up Grafana and Graphite, a supported sink for Alluxio, which will put metrics in a time-series database, along with exploring some of the possibilities that the combination offers.

The past several years have seen increasing adoption for PostgreSQL. PostgreSQL is an amazing relational database. Feature-wise, it is up there with the best, if not the best. There are many things I love about it — PL/ PG SQL, smart defaults, replication (that actually works out of the box), and an active and vibrant open source community. However, beyond just the features, there are other important aspects of a database that need to be considered.
If you are planning to build a large 24/7 operation, the ability to easily operate the database once it is in production becomes a very important factor. In this aspect, PostgreSQL does not hold up very well. In this blog post, we will detail some of these operational challenges with PostgreSQL. There is nothing fundamentally unfixable here, just a question of prioritization. Hopefully, we can generate enough interest in the community to prioritize these features.
The Couchbase CTO, Ravi Mayuram, announced the Beta of Distributed Multi-document ACID Transactions in Couchbase Server 6.5. I highly recommend reading Ravi’s blog, which highlights how Couchbase transactions are an innovative union of ACID guarantees with scale, high-availability, performance, and flexibility.
In this article, I will dive deeper into our distributed ACID transactions functionality.