
Originally published on January 31, 2015
How do we implement database relationships using spring data JPA?
Originally published on January 31, 2015
How do we implement database relationships using spring data JPA?

In this post, we will show you how to use Spring Batch to read an XML file with your ItemReader using StaxEventItemReader and write its data to Oracle Database using Custom ItemWriter. We will also learn how to use ItemProcessor to process input data before writing to the database.
Custom ItemReader or ItemWriter is a class where we write our own way of reading or writing data. In Custom Reader we are required to handle the chunking logic as well. This comes in handy if our reading logic is complex and cannot be handled using Default ItemReader provided by spring.


In this post, we look at the long and storied history of the SQL vs NoSQL debate. The articles included stretch way back to the ancient days of the early 2010s and go through 2019 – each exploring a different aspect of the SQL vs NoSQL quandry.
After all these years duking it out, is either solution winning the battle for developers’ hearts and minds?

MySQL 8 is one of the most popular database engines. It can assist link thousands of databases to servers once configured correctly and at comparatively low prices. Additionally, as it’s such a common tool, you’re unlikely to run into issues where servers don’t acknowledge it or configure it to do what you want it to do.
There may be few situations when using MySQL 8 where you will not be able to access or use MySQL correctly. These can be very unpleasant situations, but they can be readily fixed. However, you must understand the issue before you search for the solution!

The Entity Framework is a set of technologies in ADO.NET that support the development of data-oriented software applications. With the Entity Framework, developers can work at a higher level of abstraction when they deal with data and can create and maintain data-oriented applications with less code than in traditional applications.
NCache introduces the caching provider, which acts between Entity Framework and the Data source. The major reason behind the EF Caching provider is to reduce database trips (which slow down application performance) and serve the query result from the cache. The provider acts in between the ADO.NET entity framework and the original data source. Therefore, the caching provider can be plugged without changing/compiling the current code.
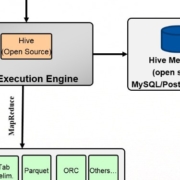
The idea of the traditional data center being centered on relational database technology is quickly evolving. Many new data sources exist today that did not exist as little as 5 years ago. Devices such as active machine sensors on machinery, autos and aircraft, medical sensors, RFIDs, as well as social media and web click-through activity are creating tremendous volumes of mostly unstructured data, which cannot possibly be stored or analyzed in traditional RDMS’s.
These new data sources are pushing companies to explore the concepts of Big Data and Hadoop architecture, which is creating a new set of problems for corporate IT. Hadoop development and administration can be complicated and time-consuming. Developing the complex MapReduce programs to mine this data is a complicated and very specialized skill. Companies need to invest in training their existing personnel or hire people specializing in MapReduce programming and administration. This is the very reason many enterprises have been hesitant to invest in big data applications.

With the MicroProfile-Config API, there is a new and easy way to deal with configuration properties in an application. The MicroProfile-Config API allows you to access config and property values from different sources, like:
Developers can find a good introduction into the MicroProfile Config API here. Of course, developers can also implement your own config source. However, most of the examples are based on reading custom config values from an existing file, like in the example here.

Extended Support for SQL Server 2008 and 2008 R2 ended in July 2019, and Extended Support for Windows Server 2008 and 2008 R2 will end in January 2020. Upgrading the software to the latest versions is always an option, of course, but for a variety of reasons, that may not be viable or cost-effective for some legacy applications. Another option is to pay an additional fee to continue receiving Extended Security Update support for three more years. But for most organizations, the best option will be to get continued support for free by moving the databases to the Azure cloud.
This article highlights the considerations and challenges involved when migrating mission-critical SQL Server 2008/R2 databases to the Azure cloud and offers some useful suggestions to help avoid common pitfalls.

As the second feature of Index Advisor released in Couchbase server 6.5 (Developer Preview), the Advisor function extends the scope from advising on a single query to providing index recommendations for query workload and support on session handling. In this article, we look at a brief review of how it works in these two different ways.
You may also like: Indexing Best Practices
Advisor function works in the following steps:

A data construct that often appears in business applications is the hierarchical data structure. Hierarchy captures the parent-child relationship often between the same object. For instance, a company structure captures the reporting line between employees. A business organization captures the relationship between parent companies and subsidiaries. Territory hierarchies in Sales. Book of accounts in financial applications.
Due to the self-referencing nature of hierarchy, querying the structure efficiently along with its associated data can be a challenge for RDBMSs, particularly from a performance perspective. In this article, I will discuss how a traditional RDBMS handles hierarchical queries, the challenges that it has to deal with, and how this issue can be similarly addressed with Couchbase N1QL and Couchbase GSI.