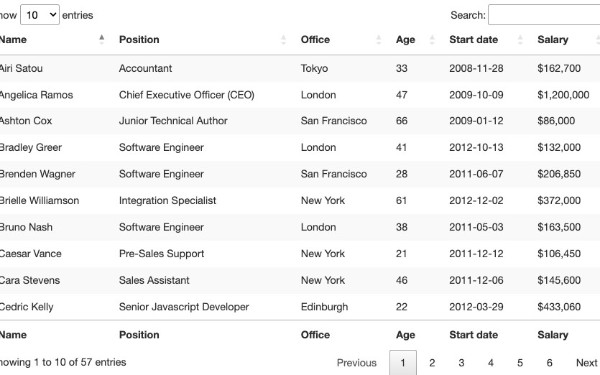
Tabular data is one of the best sources of data on the web. They can store a massive amount of useful information without losing its easy-to-read format, making it gold mines for data-related projects.
Whether it is to scrape football data or extract stock market data, we can use Python to quickly access, parse and extract data from HTML tables, thanks to Requests and Beautiful Soup.





