Introduction
In our previous article, we discussed two emerging options for building new-age data pipes using stream processing. One option leverages Apache Spark for stream processing and the other makes use of a Kafka-Kubernetes combination of any cloud platform for distributed computing. The first approach is reasonably popular, and a lot has already been written about it. However, the second option is catching up in the market as that is far less complex to set up and easier to maintain. Also, data-on-the-cloud is a natural outcome of the technological drivers that are prevailing in the market. So, this article will focus on the second approach to see how it can be implemented in different cloud environments.
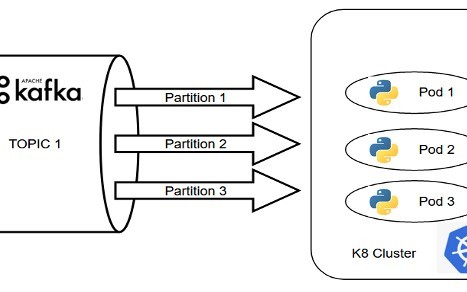
Kafka-K8s Streaming Approach in Cloud
In this approach, if the number of partitions in the Kafka topic matches with the replication factor of the pods in the Kubernetes cluster, then the pods together form a consumer group and ensure all the advantages of distributed computing. It can be well depicted through the below equation:







